






前言
chatgpt横空出世以来,震惊八方、独步天下。自24年底,我国大模型deepseek-r1模型横空出世,这把火也彻底的燃烧了,各行各业的引入,迫使技术人也都得参与其中。本人web应用出身,从事工作超过2年半,由于本人从事隔离网业务开发,对大模型本地化部署与应用也有一些个人的见解和思考。
一.本地大模型应用的基础认知
优势如下:
1.数据安全与隐私保护:
符合对数据敏感的企业、机构(如:医疗、金融、政府等部门)的安全标准
2.低网络依赖:
无需频繁与互联网或者云端通信、在无网环境(偏远地区、涉密场所)大模型也能稳定运行。并且响应速度也很快。
3.个性化定制:
企业可根据自身业务需求、数据特点对本地大模型进行微调优化,贴合独特业务流程与应用场景
劣势如下:
1.高成本投入:
搭建本地计算基础设施(高性能服务器、GPU 集群等)、购置专业软件许可证、维护硬件设备,前期需投入大量资金,后期运维也需持续人力、物力成本,对资金实力弱的企业形成较高门槛。
2.模型性能受限
受本地硬件资源(内存、计算核心数量等)制约,难以像超大规模云数据中心那样支撑超大型模型训练与运行,在处理复杂任务、大规模数据集时,运算能力不足,导致模型精度、泛化能力逊于云端大模型。
总结
不论如何,企业级开发,大部分情况下还是要走本地化部署。数据安全往往是一些企业考虑的第一要务。
二.本地化部署架构
这里采用目前比较通用的本地化部署架构(外挂知识库)
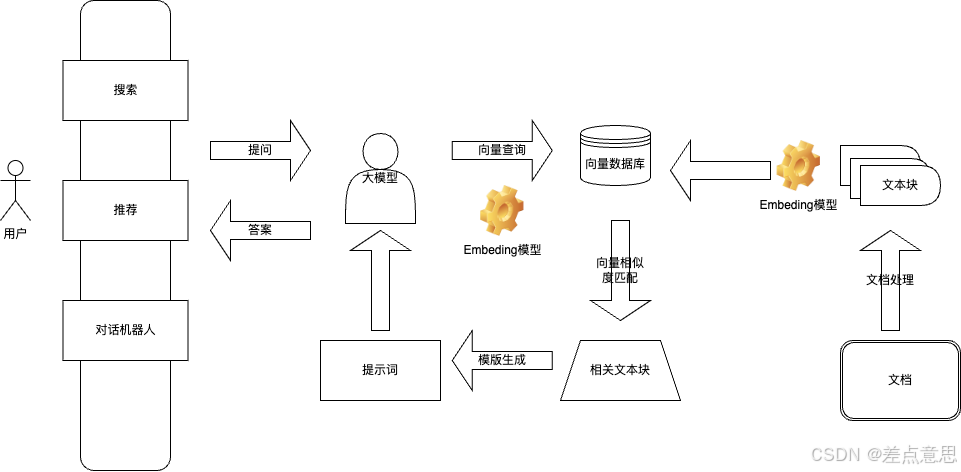
流程阅读:
1.搭建流程:
1.首先文档,当然是有关数据的文档,按照一定的规范进行切割。
2.将切割生成的文本灌入检索引擎,向量数据库中。
2.整个查询流程:
检索 -》 promt -》llm -》回复
三.落地应用的挑战
向量初高中知识都学过,有方向有大小。计算向量之差,向量余弦值。这些都是用来计算二者的误差大小。文本向量属于高维向量。目前来说,大规模的文本数据可以达到1000多维,维度越高,识别颗粒度越细。有助于复杂的文本生成、深度语义匹配任务等。
思考点:
1.文本向量如何在企业中得到?目前现有的技术是否支撑企业定制化文本相似度的计算?
2.其次,向量数据库,目前来说市面上开源向量数据库**Milvus**、**Chroma**,太多了,如何选择也是一个问题。还有,当文本数据向量累计一定程度,也会导致向量数据库性能是一个瓶颈,必须IO是应用开发的痛点。是分布式部署呢?还是走大模型微调路线?
3.关于文本分割的粒度问题,如果颗粒度太大导致检索不精准,颗粒度太小导致信息不全面,哪哪儿都是矛盾,这样导致召回数据存在很大的问题。是否有改进文本或者切割文本的体系化的流程和先进的切割文本理念进行实现。还有多文本格式文档处理,处理的文档格式包括execl、word、pdf、OFD 等等。
4.关于权限问题,rag知识库是否能够全量给所有用户展示问答是一个巨大的挑战。
5.具体的落地方向,推荐?查询?还是搜索?结合业务深入挖掘?
6.整合,AI的出现是否可以帮我们整合很多系统业务的共性问题?
现有部分解决方案:
文本分片:
-
使用分词库
Stanford NLP: 提供了丰富的工具集用于处理各种自然语言处理任务,包括中文分词、命名实体识别等。可以利用其提供的Java API进行文本分割。 Jieba分词: 虽然Jieba最初是为Python设计的,但也有Java版本可用(如jieba-analysis)。它支持精确模式、全模式等多种分词模式,并且能够通过自定义词典来提高分词准确性。 HanLP: HanLP是一个高效的中文处理工具包,支持多种语言和功能,包括分词、词性标注、命名实体识别等。HanLP提供了Java接口,非常适合需要对中文文本进行处理的场景。 -
基于LangChain的文本分割工具
LangChain4J 是一个用于开发语言模型应用的框架,Spring AI的直接竞争对手,它提供了多种工具和组件来处理文本数据,包括文档分割(Document Splitters)。文档分割器(DocumentSplitters)的主要目的是将大型文档分割成更小的块或片段,以便更有效地处理或分析。这些分割策略对于确保文本块适合于特定的语言模型输入限制(如最大token长度)非常重要。
四.Web服务应用
本人基于前端vue3 + 后端 jdk17版本 springboot + springAi框架+ Qwen大模型搭建图书馆智能问答助手
演示地址: https://b23.tv/QdKsBwQ
实现功能:
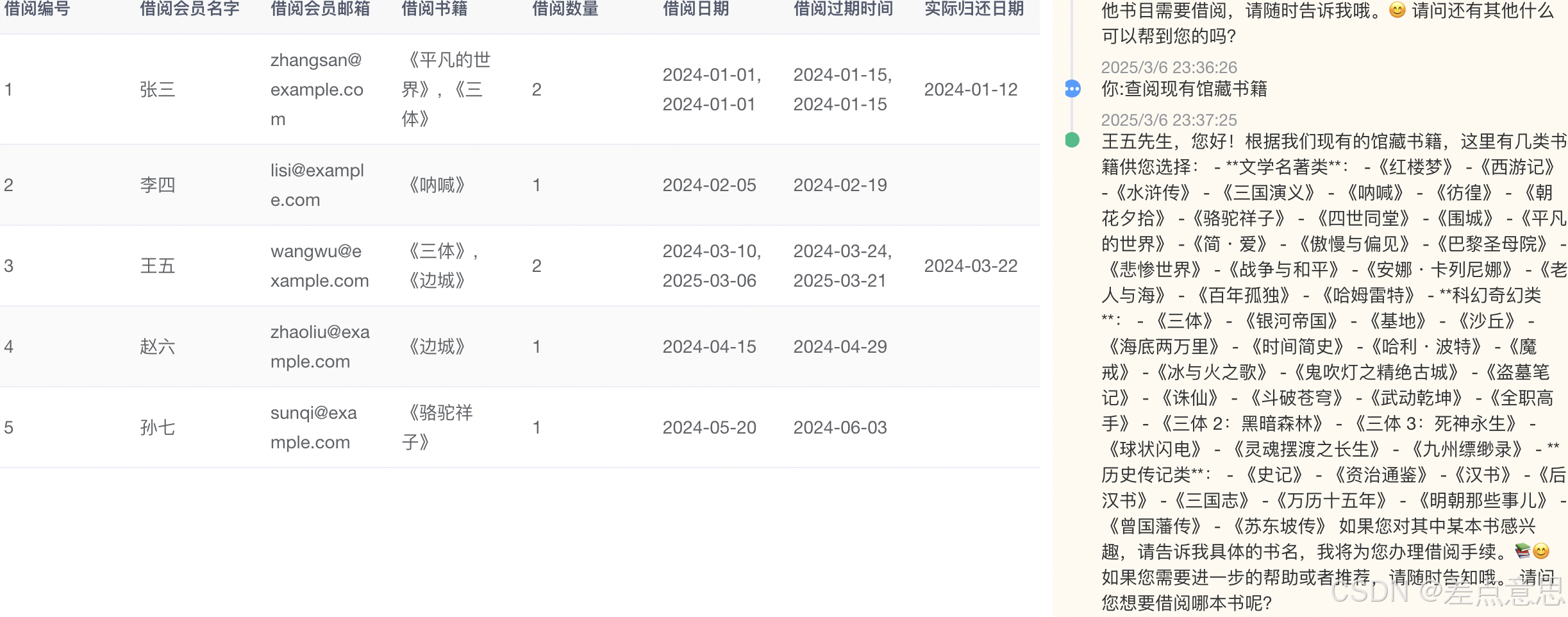
1.根据借阅编号和姓名找到相关借阅信息。
2.可以查询本图书馆所有在册书籍(外挂rag)
3.预定书籍,包括借阅时间
4.逾期收费等等功能。
1.开始对话
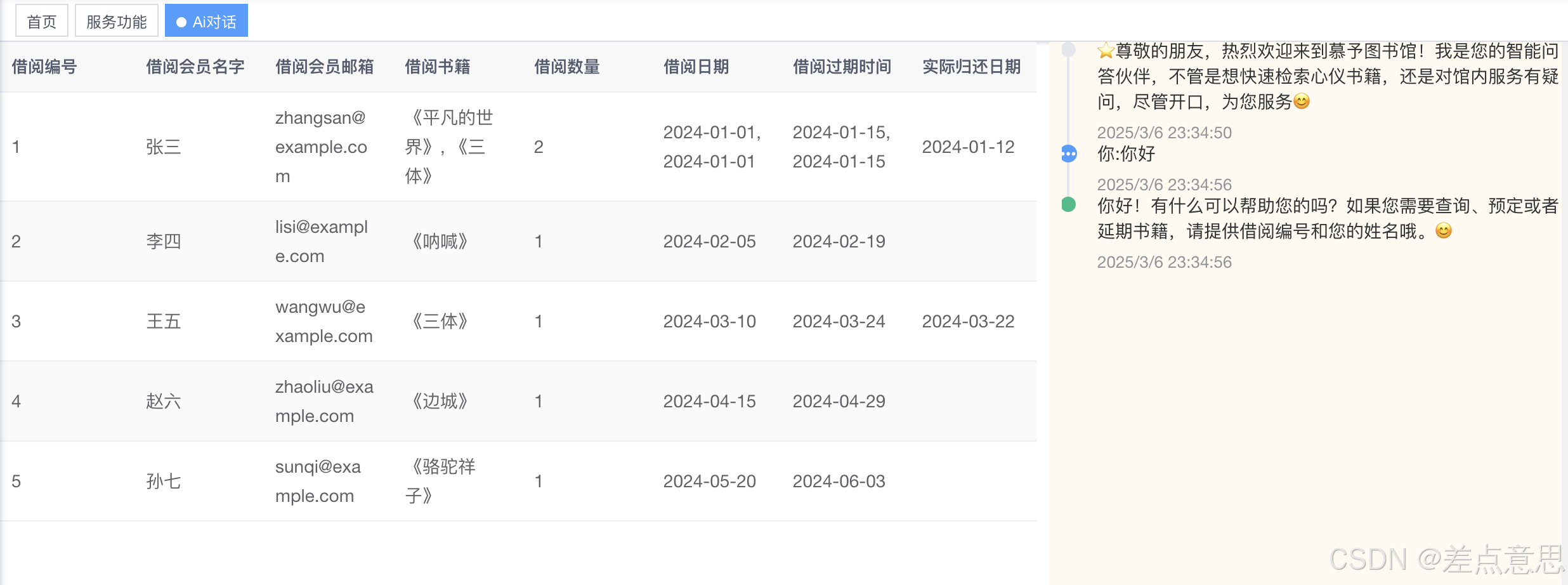
2.输入查阅姓名
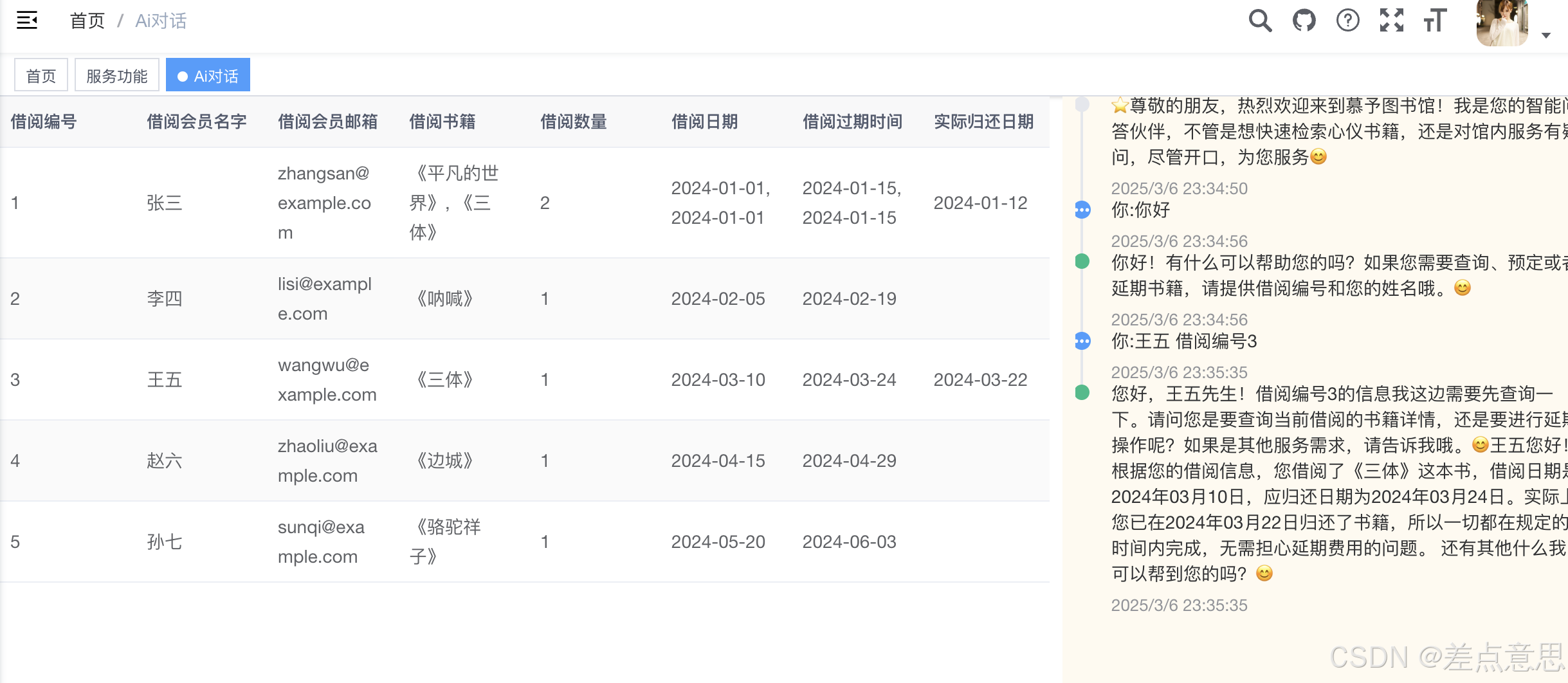
3.开始借阅新书籍
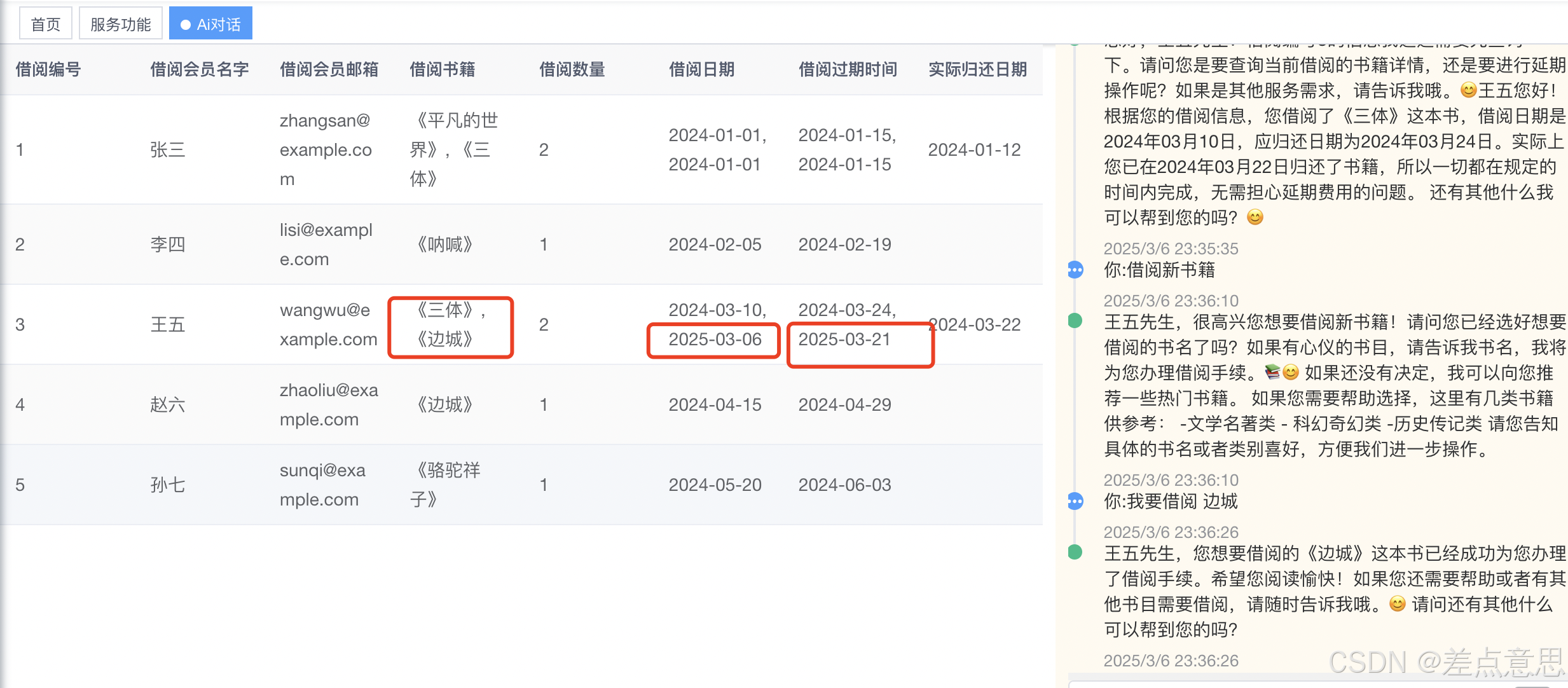
4.查阅馆藏书籍(外挂知识库)


















 604
604

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









