



本人于今日(2025年07月14日)正式在多平台开源2025届齐鲁工业大学(山东省科学院)优秀毕业设计项目《基于LLM与多模态人工智能的健康管理与辅助诊疗系统的设计与实现》,欢迎各位老师同学和开发者借鉴使用!
(一)系统名称及开源地址📖
项目全名: 明康慧医——基于LLM与多模态人工智能的健康管理与辅助诊疗系统的设计与实现(简称: 明康慧医智慧医疗系统)
【英语:Minh Khoe Tue Y — Design and Implementation of a Health Management and Diagnostic Assistance System Based on LLMs and Multimodal Artificial Intelligence (Abbreviation: MKTY Smart Healthcare System);越南语:Minh Khỏe Tuệ Y – Thiết kế và triển khai hệ thống quản lý sức khỏe và hỗ trợ chẩn đoán y tế dựa trên LLM và trí tuệ nhân tạo đa mô thức (Tên viết tắt: MKTY – Hệ Thống Y Liệu Trí Tuệ)】
![]()
DOI: https://doi.org/10.5281/zenodo.17444889
项目开源地址:
(1) GitHub平台: https://github.com/duyu09/MKTY-System
(2) HuggingFace平台(模型权重):https://huggingface.co/Duyu/MKTY-3B-Chat
(3) Gitee平台:https://gitee.com/duyu09/MKTY-System
(4) Gitcode平台:https://gitcode.com/duyu09/MKTY-System


(二)项目简介📖
在新时代互联网应用与技术进一步普及与人工智能技术飞速发展的双重驱动下,计算机技术在医健领域的应用可谓愈加广泛,大众对医健日渐增加的需求难以为传统的诊疗与保健管理模式所满足,其面临的诸多如诊断效率低下、医资配置不均、患者不便利与决策依赖经验等问题已相对严重。因此,如何利用互联网与前沿的人工智能技术,特别是利用大规模语言模型(LLM)与多模态技术来提升医疗保健相关业务的数字化、智能化已成为一个重要的课题。为更好地探讨互联网技术以及大语言模型与多模态等AI技术在医疗领域的潜力,本研究设计并实现了“明康慧医——基于LLM与多模态人工智能的健康管理与辅助诊疗系统”,本人同时也为提高医患交流效率和优化诊疗的流程尽一份作为本科毕业生的微薄之力。
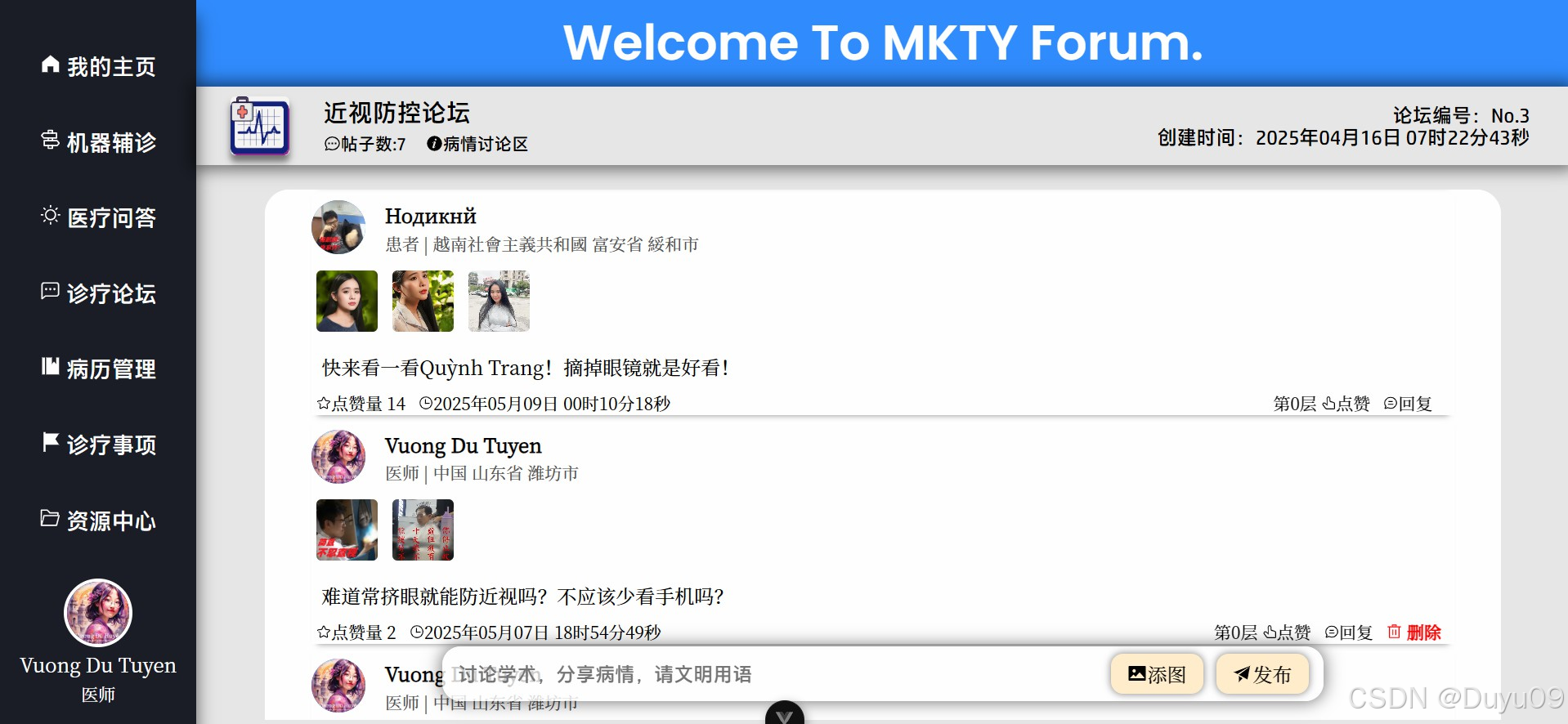
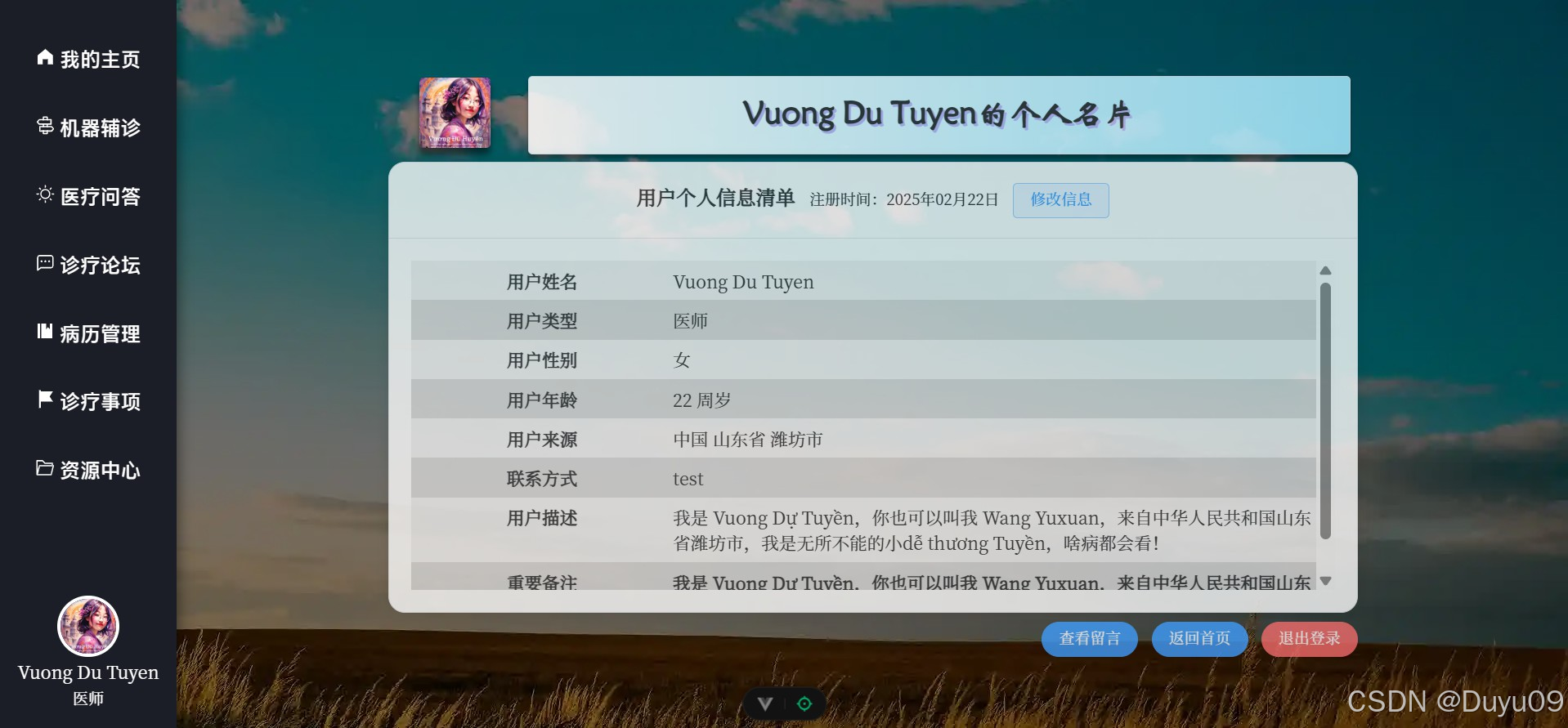
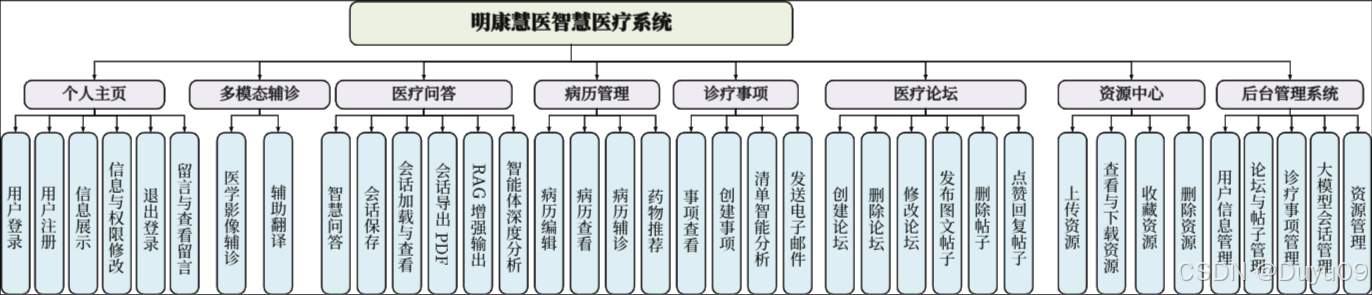
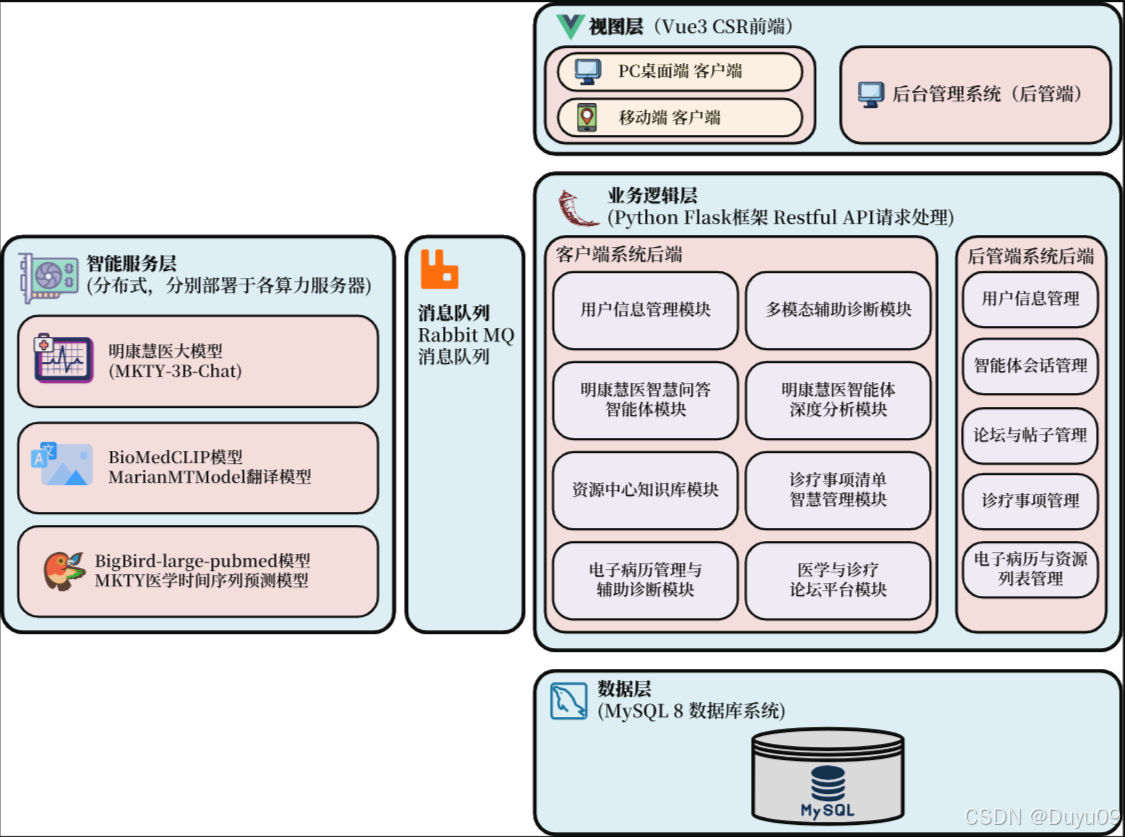
本平台是一个集注册登录、个人信息管理、多模态智能辅诊、医疗问答、诊疗论坛、病历管理、诊疗事项清单管理、资源中心及后台管理九大模块于一体的分布式系统平台。系统宏观架构采用前后端分离设计,业务逻辑层后端基于Python Flask框架,数据库采用MySQL的方案,RabbitMQ实现完成业务逻辑端与智能服务端的异步消息通信,构建分布式微服务部署;前端页面组件化与交互效果采用Vue3、axios与Element Plus实现,系统鉴权通过JWT机制实现,保障数据的安全。
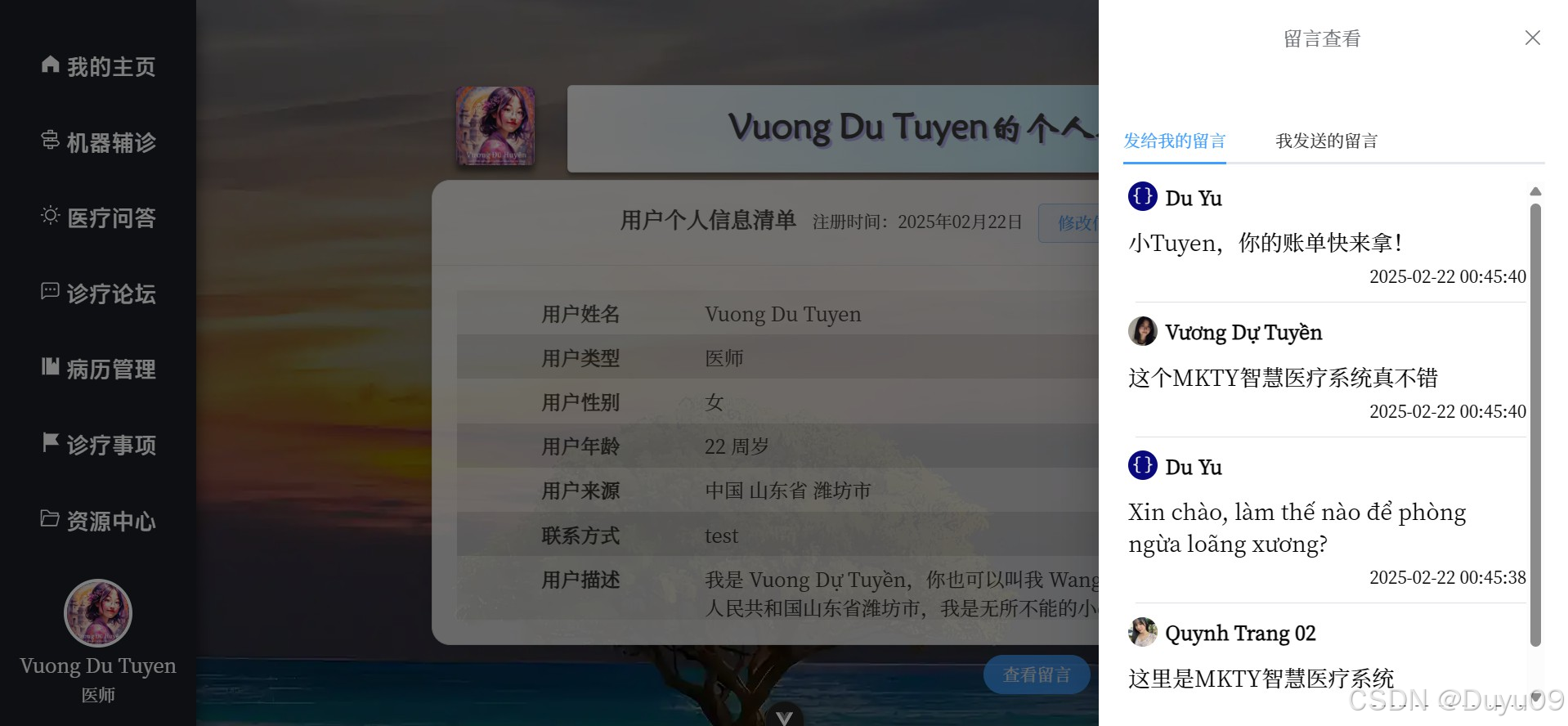
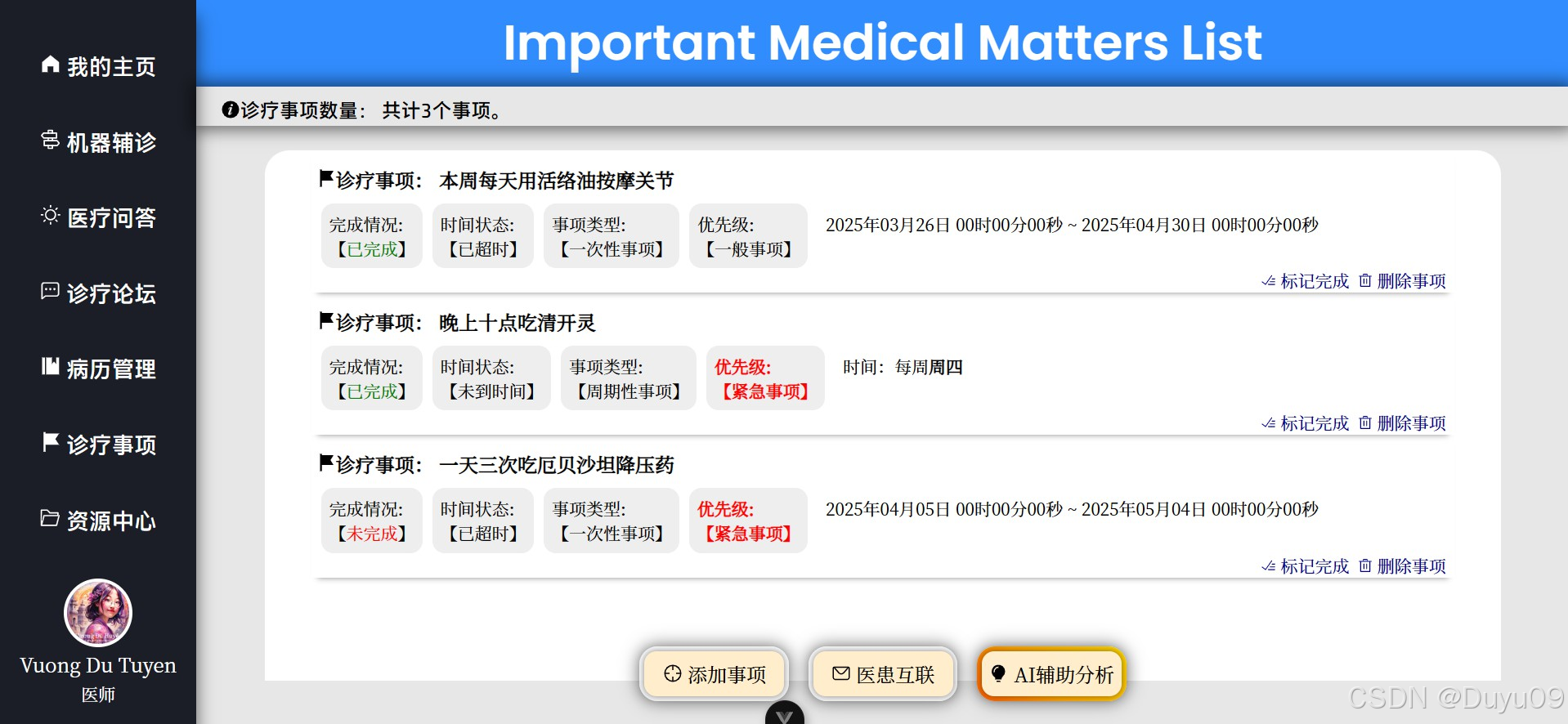
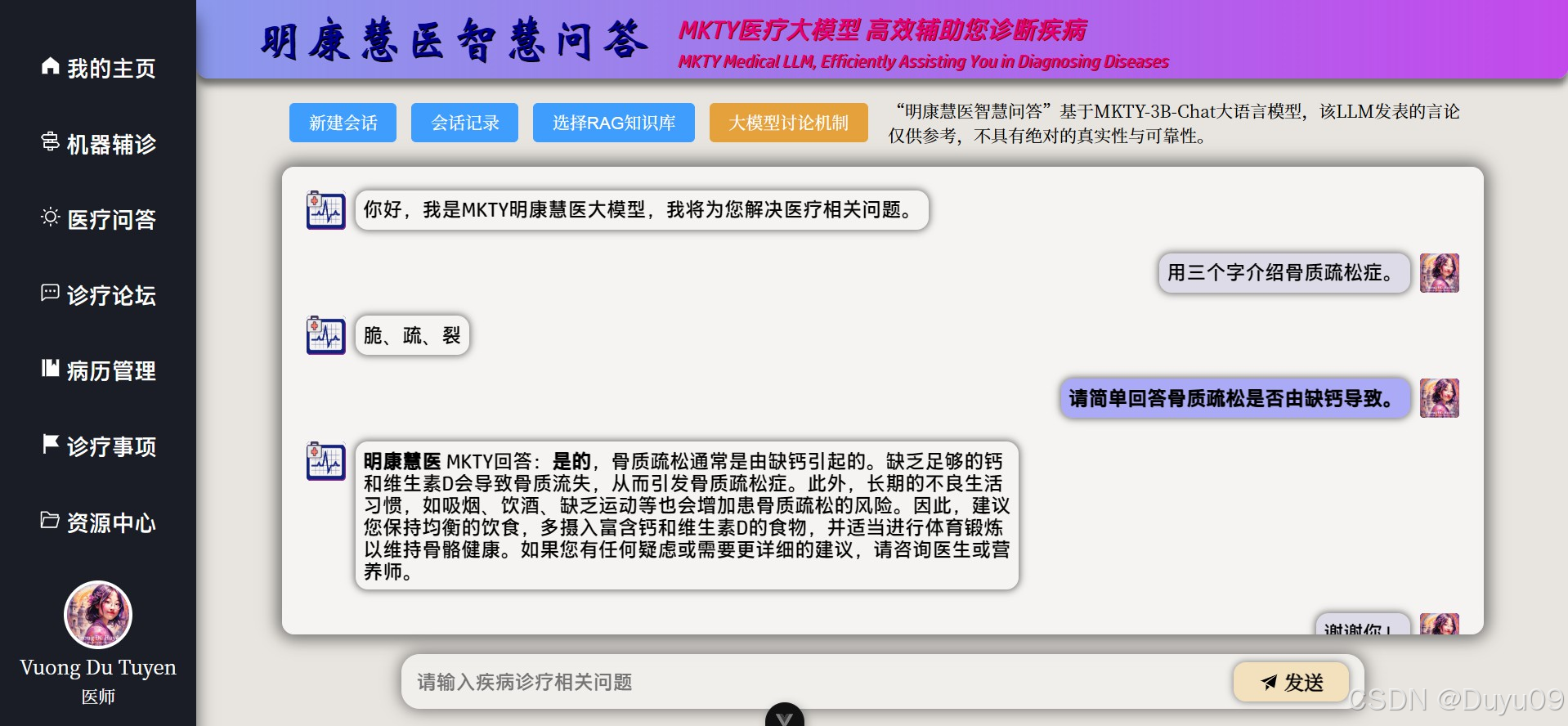
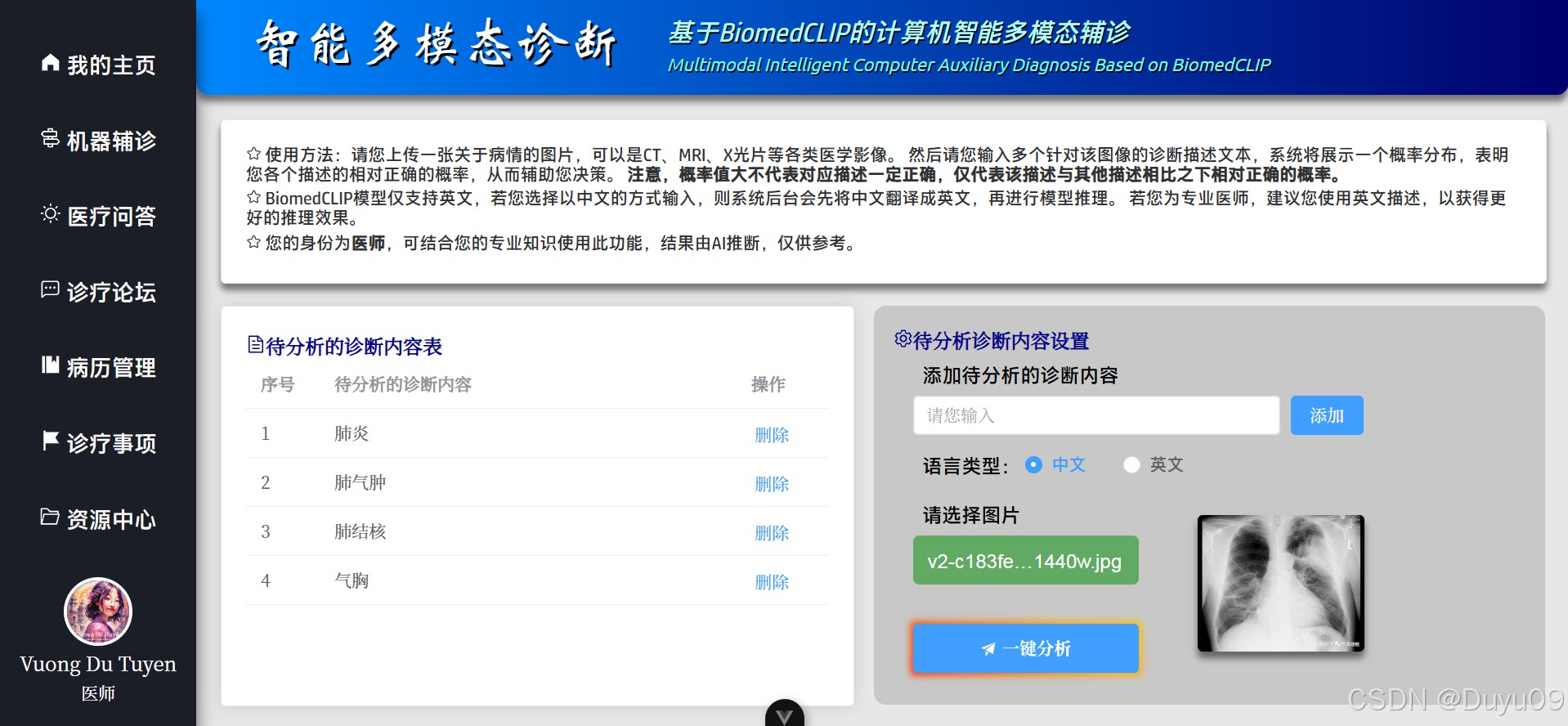
在AI智能服务端方面,“智能多模态辅诊”基于BioMedCLIP对比学习模型与MarianMTModel中英文神经机器翻译模型的级联架构,通过输入的医学影像,计算多条待判中文诊断描述为正确的相对概率分布。医疗问答、问题深度研究及其它语言生成任务均利用MKTY-3B-Chat大模型。该LLM以Qwen2.5-3B-Instruct为底座,采用LLaMA-Factory利用大量医学领域文本微调而成。问题深度研究模块基于“大模型讨论机制”(LLMDM),是为本人自研的一种LLM生成模式,可充分挖掘大模型内部的知识且可引导其推理。
关键词:医疗数字化;辅助诊疗;大规模语言模型;多模态;Vue3;Python Flask;
(三)技术栈🛠️
本项目主要使用了以下库、组件或开源项目:
- 前端: Vue.js、Element Plus、Axios、marked.js、DOMPurify、highlight.js、jQuery
- 后端: Python Flask、pika、weasyprint、smtplib、PIL、argon2、rich、SQLAlchemy
- 数据库: MySQL
- 消息队列: RabbitMQ
- 机器学习与大模型: PyTorch、Transformers、Qwen2.5-3B-Instruct
(四)人工智能技术🤖
4.1 明康慧医大模型 (MKTY-3B-Chat)
明康慧医大模型权重公开地址: https://huggingface.co/Duyu/MKTY-3B-Chat
明康慧医大模型(英语:MKTY-3B-Chat Large-scale Language Model;越南语:MKTY-3B-Chat Mô hình Ngôn ngữ Quy mô Lớn)是本项目的重要组成部分,为本人2025级齐鲁工业大学(山东省科学院)计算机科学与技术学部本科毕业设计而开发。
模型参数量3.09B,量化精度BF16,其在医学、医疗及生物学领域进行了微调与优化,其表现优于底座模型通义千问Qwen2.5-3B-Instruct。微调过程采用LoRA算法,仅针对中文语言。微调时使用增量预训练Pretrain与指令监督微调SFT两种方法,并分四个微调步骤进行,具体来说就是一轮增量预训练+一轮指令监督交替进行两次,这样做是考虑到底座模型规模不大,吸收知识的能力跟巨大规模模型相比稍逊一筹,若只进行一轮微调,那么经过SFT后大模型可能会遗忘掉其先在增量训练阶段学习到的知识,执行两轮微调可减轻大模型的灾难性遗忘。
训练数据方面:语料数据包含为生物领域广泛文本、医学诊断与问答、医学考试选择题以及自我意识等。在本项目中,MKTY大模型的使用场景是医疗问答、大模型讨论、总结诊疗计划、根据病历诊断和推荐药物,开发时针对这四条用途准备了数据集,医学生物广泛知识文本用以在增量预训练阶段增加大模型的医疗专业知识,医学问答数据集用于指令监督微调,增强大模型回答问题的能力,医学诊断用于增强大模型诊断病历的能力,使用医学考试选择题的目的是告诉模型一个问题及其回答正确答案的回答模式,在大模型讨论机制功能中,不论是独立智能体角色还是主持人角色,都应该针对某问题结合已有的答案做出自己的判断,而教会大模型做医考选择题即可达到训练大模型按这种模式来回答问题的目的。另外“自我意识”是指通过指令监督,使模型得知自己是谁,由谁开发等。
大模型所用训练数据总量约为2.88GB(解压后约为6.79GB),是为从全网各网站平台以及本人个人关系获得的,所有训练数据均为开源的,并且是在不违反开源协议的合法情况下使用的,由于数据来源数量非常大且难以统计,以下仅列出了主要的数据来源网址,所有数据用于训练前都做过二次清洗和规整格式等预处理:
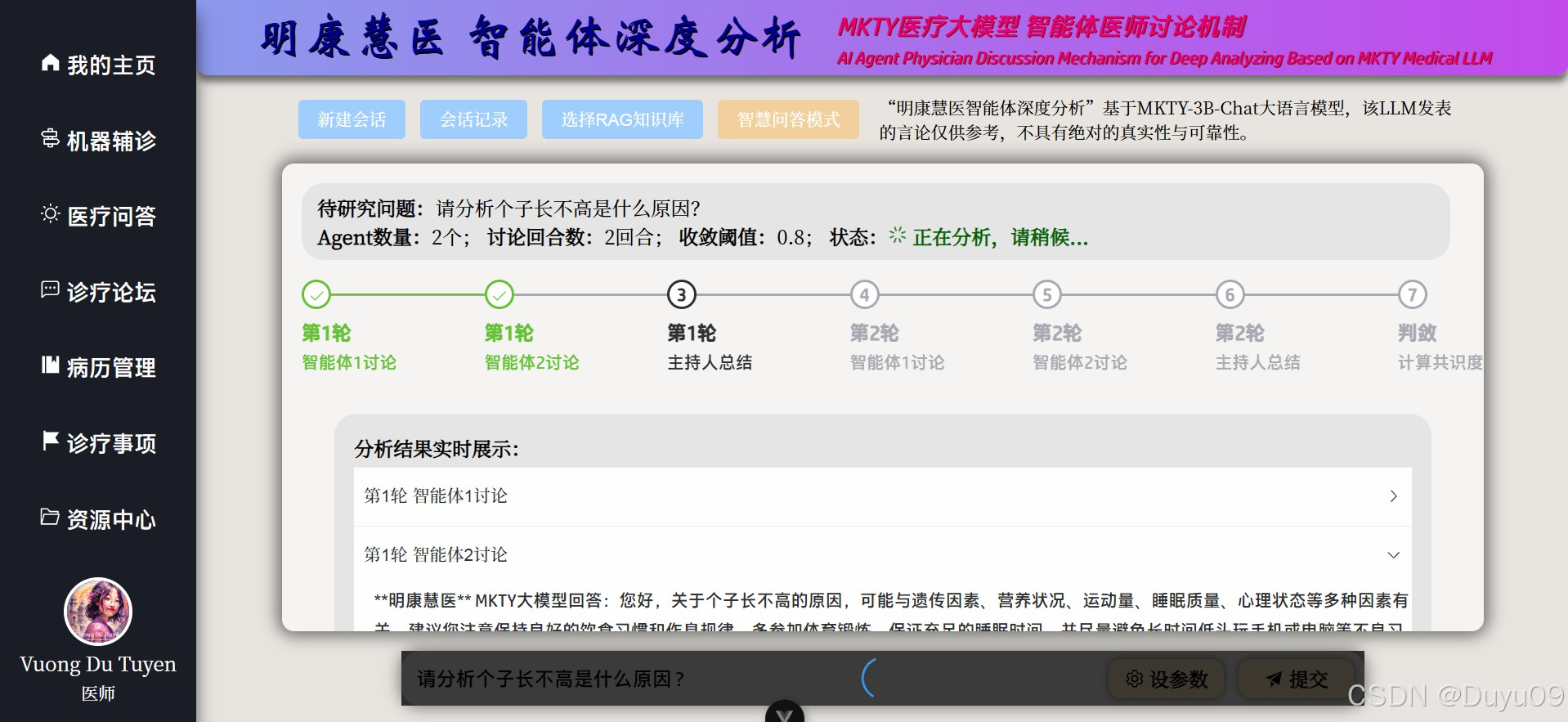
4.2 智能体深度分析
智能体深度分析功能基于本人自研的大模型讨论机制LLMDM。该方法有智能体个数、讨论回合数与判敛阈值三个超参数,完全相同的若干大模型(MKTY-3B-Chat)在会话上下文不同时不认为是同一个智能体。第一轮讨论过程是,系统通过设置多个上下文数组模拟多个智能体,让每个智能体分别回答待深入研究的问题,然后由没有会话上文的“主持人”智能体总结各方发言。以后每轮讨论,都将上轮主持人的总结和原问题拼接合并,并由各智能体基于自己的会话上下文再分别回答合并后的prompt,最后主持人总结,周而复始,直至达到最大讨论轮次数。
然后是“判敛”的过程:用BigBird将最后一轮讨论各方的输出计算句子嵌入向量,然后计算各向量两两之差的平均值,以此反应各方达成共识的程度,即讨论语义收敛程度,这个数值可供人类用户作参考。
4.3 融合文本的时间序列预测模型
目前基于深度学习方法的各领域时间序列预测问题所使用最多的算法是LSTM或GRU,直至去年(2024年)也才有学者受NLP技术的启发提出基于Transformer的时序预测模型,但这些方法都没有考虑到时间序列与多模态相结合。
本次研究中,本人基于GRU,尝试性地设计了一种基于医学文书的医疗时间序列预测模型,模型原理:主要使用门控循环单元进行初步的时间序列预测,而后通过FFT计算历史时间序列的频域,将频域中各频率序数对应的振幅向量与相位向量拼接得到频域特征,随后用BigBird提取医学文本描述的句子嵌入,利用交叉注意力机制计算出频域联合特征向量与该句子嵌入的分数矩阵,从而得出加权频域联合特征。将此特征向量拆解并求逆FFT可得到一个差值时序数据,与此同时将求逆FFT前的频域数据通过一个线性层,求得一个阈值向量,利用门控的思想将这个阈值向量与求得的差值时序数据相乘,再加到基础GRU输出的结果上,作为模型最终的输出。
这样设计的思想在于,时间序列的频域反映了序列的整体情况,而不像时域那样局限于局部时间,计算文本特征与序列频域特征的交叉注意力因而有意义,比如以心电图举例,文本描述“心跳加速”,那么从频域角度看,这句话代表的是整个心电图波形更高频部分的振幅增大,这很容易通过交叉注意力向某高频部分的振幅加权权重增大来反映出来,而时序数据理论上无法体现。
下图展示了时序预测模型结构:

(五)项目结构🚀
本系统是一个分布式系统,建议按性能要求部署至多台服务器,业务逻辑后端、数据库端、SSR前端服务器无特别要求。有明显性能要求的部分是智能服务层,其中明康慧医大模型权重及推理时缓存等共需8GB显存,BioMedCLIP需2GB显存,BigBird需2GB显存,时序预测模型显存占用可忽略。只部署一部分或不部署智能服务层也可以启动系统,但只能启动系统业务逻辑后端和CSR/SSR前端,且系统中相应AI服务不可用。
明康慧医系统功能模块图:
明康慧医系统架构图:
具体代码及部署、运行方法参见系统开源代码仓库。
https://github.com/duyu09/MKTY-System
(六)著作权及开源协议声明🎓
该项目已用于2025年齐鲁工业大学(山东省科学院)计算机科学与技术学部毕业设计。
👤 项目作者
- 杜宇 (英语:Du Yu;越南语:Đỗ Vũ;电邮:202103180009@stu.qlu.edu.cn 与 qluduyu09@163.com),齐鲁工业大学(山东省科学院)计算机科学与技术学部 2025届本科毕业生
🏫 毕业设计指导教师
- 校方老师:姜文峰 (英语:Jiang Wenfeng;越南语:Khương Văn Phong),齐鲁工业大学(山东省科学院)计算机科学与技术学部 副教授
- 企业方老师:李君 (英语:Li Jun;越南语:Lý Quân),安博教育科技集团(NYSE: AMBO) 山东师创软件实训学院 高级软件工程师
⚖️ 开源协议
本系统基于 添加了附加条款 的MPL-2.0 (Mozilla Public License 2.0) 开源协议公开发布,您下载、使用、修改、发布本软件系统项目或其源代码前请认真阅读并完全知晓、充分理解https://github.com/duyu09/MKTY-System/blob/main/LICENSE文件中的内容。
说明
-
请您务必遵守
LICENSE文件中规定的内容(MPL-2.0以及附加条款)本人对侵犯著作权的行为持“零容忍”态度。本人完全赞成并欢迎他人使用本项目及源代码,但对于任何违反协议的侵权行为,本人必将对其追究法律责任,并要求其受到法律限度内最严厉的处罚与赔偿(顶格处罚)。 -
侵权风险提示:将本项目的部分或全部当作商品售卖(包括但不限于以“课程设计”、“毕业设计”等名义)在
MPL-2.0协议及附加条款中并不明确反对,但必须在醒目的位置标明本项目的名称(至少包含简称“明康慧医”)、原始作者(至少包含“杜宇”)、官方开源仓库链接(https://github.com/duyu09/MKTY-System)否则将有试图“混淆或隐瞒本软件的开源性质及其在项目中使用的事实”的嫌疑。 -
若您发现有任何违反开源协议及上述内容的个人或组织,欢迎举报,举报方式包括但不限于向本项目任何一名作者发送举报邮件,或在项目所在的开源平台提起issue等方式。
项目开源地址:
(1) GitHub平台: https://github.com/duyu09/MKTY-System
(2) HuggingFace平台(模型权重):https://huggingface.co/Duyu/MKTY-3B-Chat
(3) Gitee平台:https://gitee.com/duyu09/MKTY-System
(4) DOI(Zenodo平台托管):https://doi.org/10.5281/zenodo.17444889
本文到此结束,感谢您的阅览。
GIỮ VỮNG TÂM ĐẦU, KIÊN ĐỊNH CHÍ HƯỚNG


















 2761
2761

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











