




 本文介绍如何使用Python网络爬虫精准定位PDF文件URL,设置下载规则,选择‘下载文件’选项,处理相对网址,并选择存储方式,包括不分主题存放和分主题存放的设置方法。
本文介绍如何使用Python网络爬虫精准定位PDF文件URL,设置下载规则,选择‘下载文件’选项,处理相对网址,并选择存储方式,包括不分主题存放和分主题存放的设置方法。
举个例子,我们打算把这个法规/标准网站上的pdf格式的法规文件下载下来:
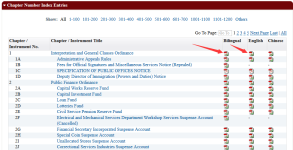

如果人工下载这些文件的话,需要在这个网页上逐个点击那些文件图标,即可激发下载过程。
下面将详细讲解定义规则和抓取过程。
1. 定义抓取规则
定义抓取规则的方法参看基础教程中的相应章节,请注意,这种标注是一种快捷的规则定义方法,但是并没有精确地定位HTML DOM节点,比如,在英文附件那个图标上做内容标注,会自动定位到DOM的IMG节点。为了下载pdf文件,定位到这个IMG节点是不精确的,这种内容标注主要用于采集文本内容。
为了精确地把pdf文件的url网址抓取下来,应该精确地做内容映射,如下图:
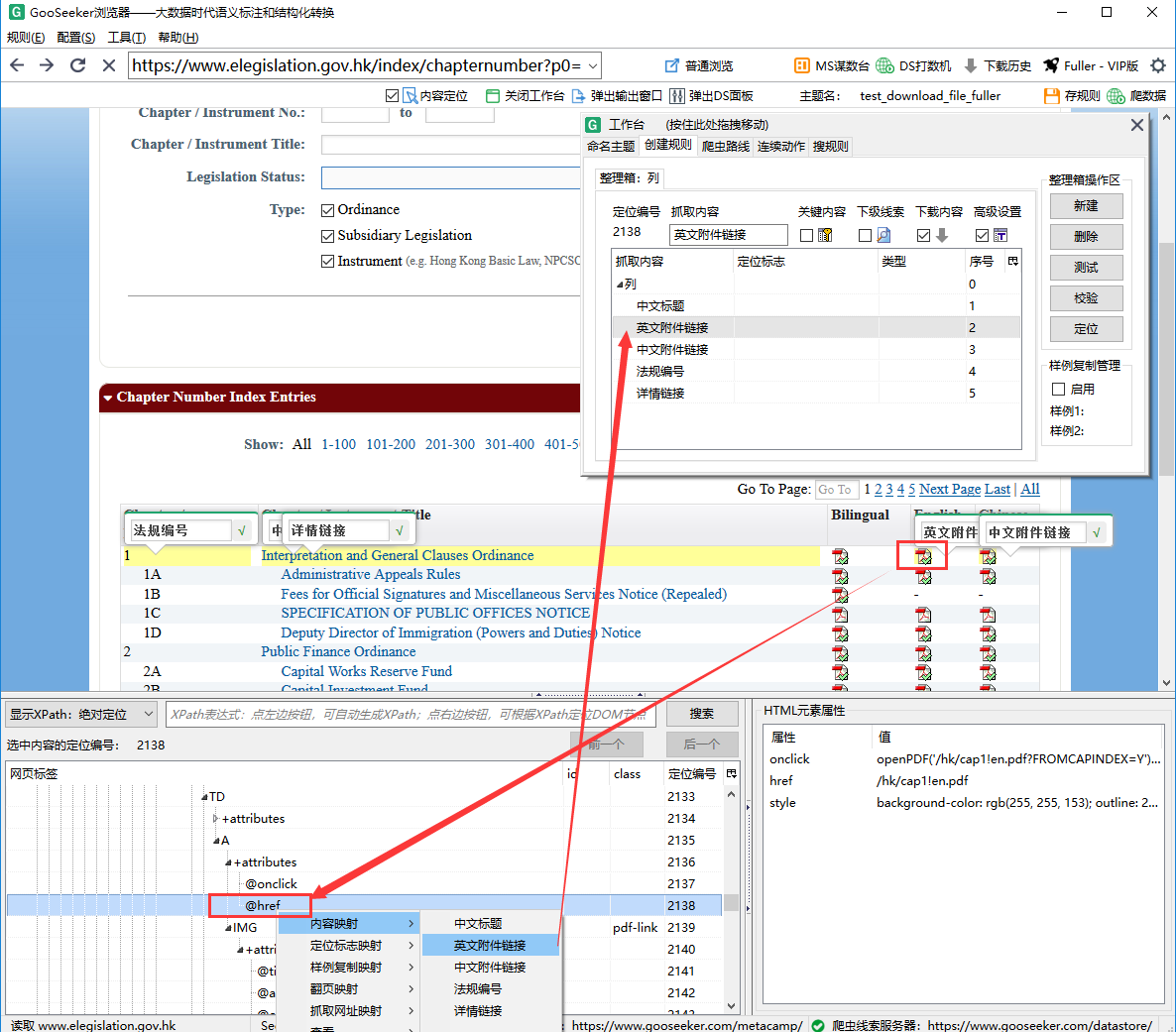
步骤如下:
- 在文件图标上通过双击做内容标注,并且命名抓取内容为“英文附件链接”
- 观察窗口下部的DOM树,看到自动定位到了IMG,而我们需要这个图标对应的url,用以下载文件。通过观察DOM树,可以确定url存于IMG的父节点A中的属性节点@href中。
- 选中@href节点,用鼠标右键菜单 内容映射->英文附件链接,就可把@href映射给英文附件链接这个抓取内容。做了映射以后,就能看到工作台上的这个抓取内容的定位编号变化了。
上述过程就是普通的定义抓取规则过程,下面将是跟下载文件有关的设置过程。
2. 设置下载
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 866
866



 到【灌水乐园】发言
到【灌水乐园】发言







