




一、操作步骤
爬虫不仅能抓到网页上的文本、网址数据,还可以批量下载图片到电脑中。无论是列表页还是详情页上的图片,只要能获取图片网址都可以用爬虫来下载图片。下面就以途牛网的自助游网页为案例,操作步骤如下:


**注意事项:**从爬虫软件V9.0.0开始,图片下载后的存储位置有了很大改变,但是定义规则过程不变,请注意看第五步里面的说明和相应的链接。
二、案例规则+操作步骤
- 样本网址:http://www.tuniu.com/tours/210299425
- 采集内容:旅游名称、价格、图片网址。
如果纯粹采集图片,就不知道图片来源于哪里,所以,我们通常会把网页上的文本信息“旅游名称”“价格”也采集下来,最后可以用excel把它们匹配起来。文章《采集网页数据》已经详细讲过前两步操作了,下面就从第三步操作开始讲。
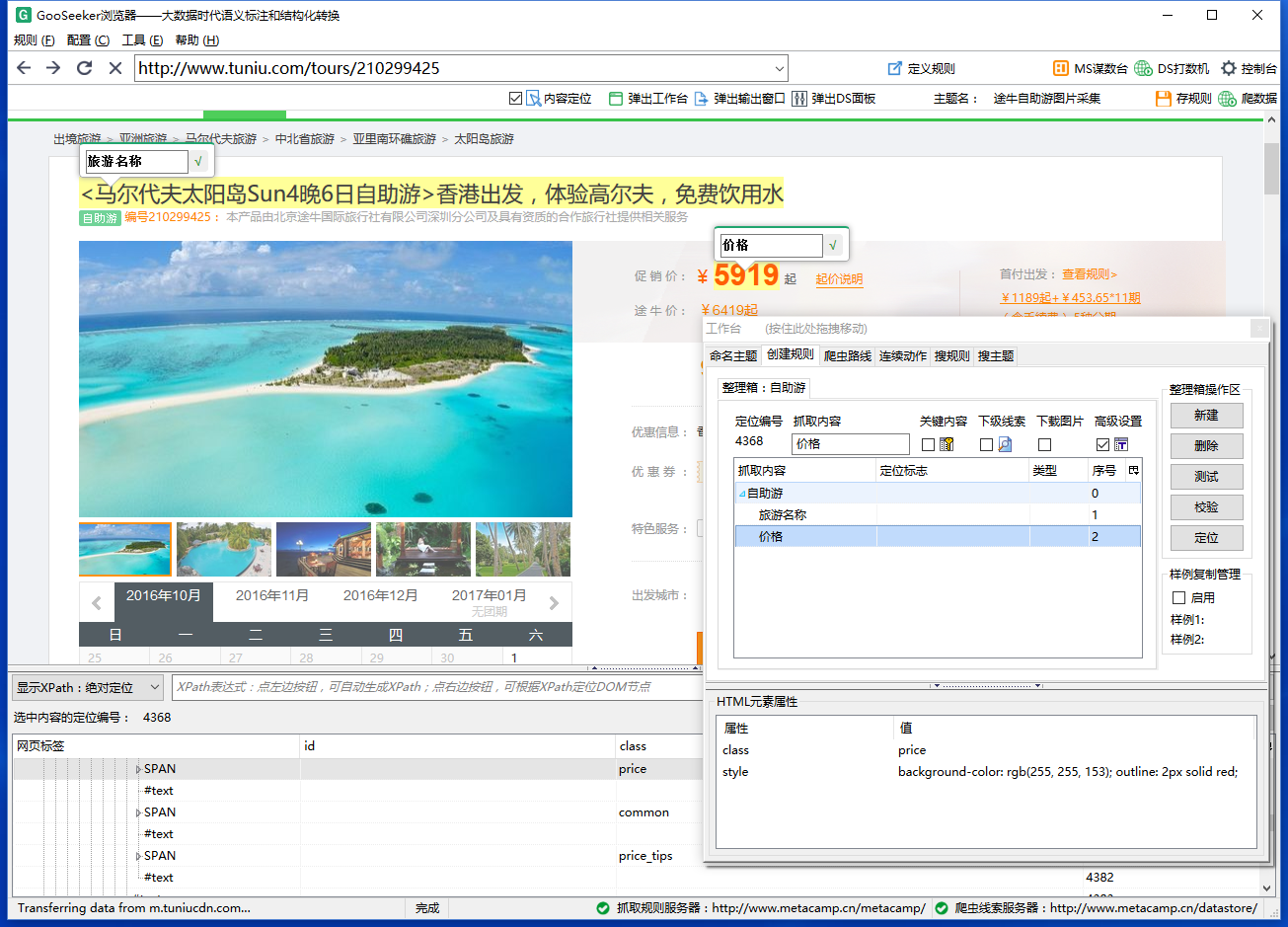
第三步:采集图片网址
3.1, 点击小图可以定位到它的IMG节点。我们不直接采集大图,因为大图是由小图放大的,并且只显示一张,也就只能抓到一张大图,但是小图可以全部抓到,最后用excel处理就能变成大图,所以,类似这种网页的情况抓小图就容易多了。
3.2,再双击展
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 1205
1205

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









