



包含编程籽料、学习路线图、爬虫代码、安装包等!【点击领取】

在当今大数据时代,数据采集成为了许多项目的核心环节。Python凭借其丰富的库和简洁的语法,成为了网络爬虫开发的首选语言。本文将带你从零开始,轻松掌握Python网络爬虫的基本技能,并通过详细的代码示例,帮助你快速上手数据采集。
目录
1.网络爬虫简介
2.环境准备
3.基本爬虫实现
4.数据解析与存储
5.高级技巧与反爬虫策略
6.实战案例
1. 网络爬虫简介
网络爬虫(Web Crawler)是一种自动化程序,用于从互联网上抓取数据。它可以模拟浏览器行为,访问网页并提取所需的信息。常见的应用场景包括搜索引擎索引、数据挖掘、价格监控等。
2. 环境准备
在开始编写爬虫之前,我们需要安装一些必要的Python库。常用的库包括requests、BeautifulSoup、lxml和pandas。


3. 基本爬虫实现
3.1 发送HTTP请求
首先,我们需要使用requests库发送HTTP请求,获取网页内容。
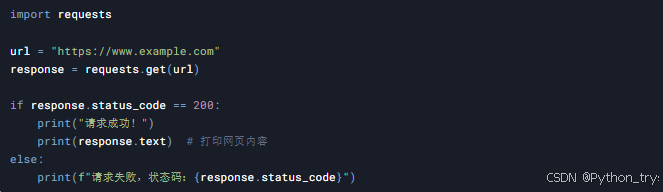
3.2 解析HTML内容
获取到网页内容后,我们需要解析HTML,提取出有用的信息。这里我们使用BeautifulSoup库。
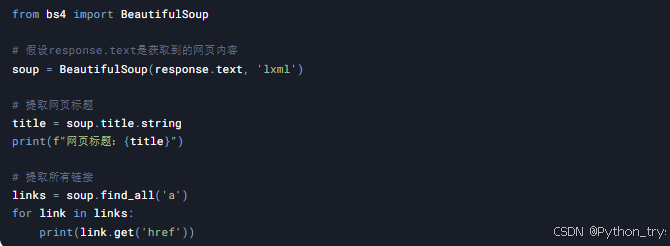
4. 数据解析与存储
4.1 提取结构化数据
通常我们需要从网页中提取特定的结构化数据,例如新闻标题、发布时间等。
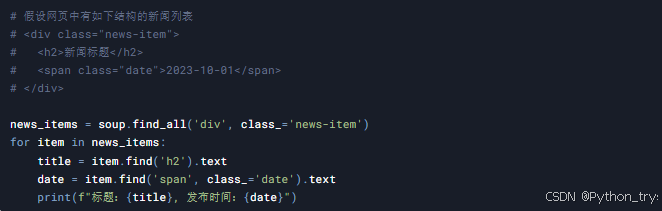
4.2 存储数据
我们可以将提取到的数据存储到CSV文件中,方便后续分析。
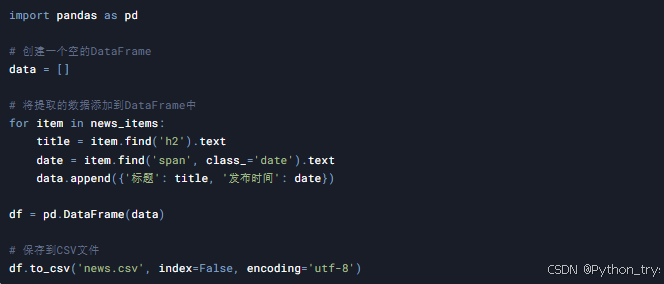
5. 高级技巧与反爬虫策略
5.1 处理动态加载内容
有些网页使用JavaScript动态加载内容,直接使用requests无法获取到这些内容。这时可以使用Selenium模拟浏览器行为。
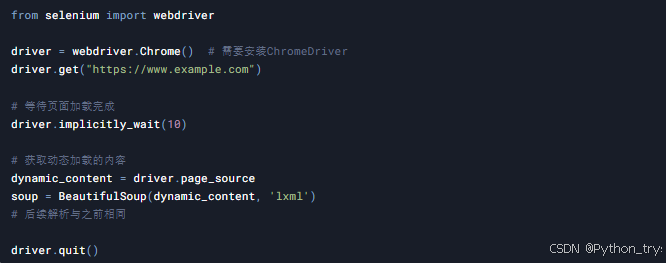
5.2 应对反爬虫策略
许多网站会设置反爬虫机制,如IP封禁、验证码等。我们可以通过以下方法应对:
设置请求头:模拟浏览器请求。
使用代理IP:避免IP被封禁。
降低请求频率:避免触发反爬虫机制。

6. 实战案例
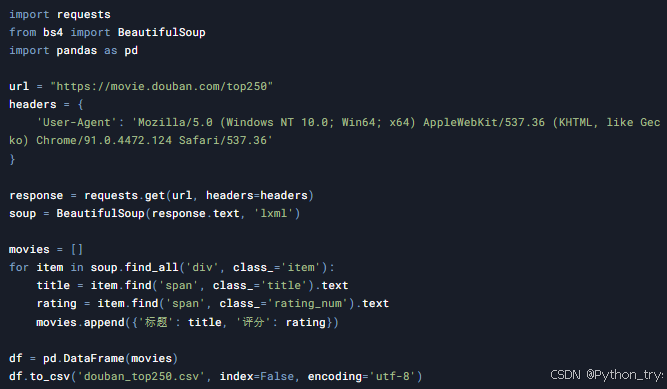
6.1 爬取豆瓣电影Top250
我们以爬取豆瓣电影Top250为例,综合运用前面所学的知识。
结语
通过本文的学习,你已经掌握了Python网络爬虫的基本技能,并能够进行简单的数据采集。在实际项目中,你可能会遇到更复杂的情况,但万变不离其宗,掌握了基础,再复杂的爬虫也能应对自如。
希望这篇教程对你有所帮助,如果你有任何问题或建议,欢迎在评论区留言!
最后:
希望你编程学习上不急不躁,按照计划有条不紊推进,把任何一件事做到极致,都是不容易的,加油,努力!相信自己!
文末福利
最后这里免费分享给大家一份Python全套学习资料,希望能帮到那些不满现状,想提升自己却又没有方向的朋友,也可以和我一起来学习交流呀。
包含编程资料、学习路线图、源代码、软件安装包等!【点击这里领取!】
① Python所有方向的学习路线图,清楚各个方向要学什么东西
② 100多节Python课程视频,涵盖必备基础、爬虫和数据分析
③ 100多个Python实战案例,学习不再是只会理论
④ 华为出品独家Python漫画教程,手机也能学习


















 1836
1836

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









