




包含编程籽料、学习路线图、爬虫代码、安装包等!点击这里领取!
数据分析时,原始数据存在大量不完整、不一致、异常数据,严重影响数据分析结果,所以进行数据清洗尤为重要。
数据清洗就是处理缺失数据及无意义的信息,如删除原始数据集中的无关数据、重复数据、平滑噪声数据,筛选掉与分析主题无关数据,处理缺失值、异常值;因此数据分析过程中,数据清洗占据很大工作量。
1.重复值处理
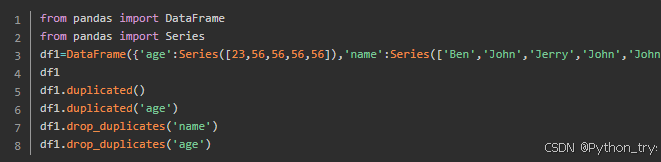
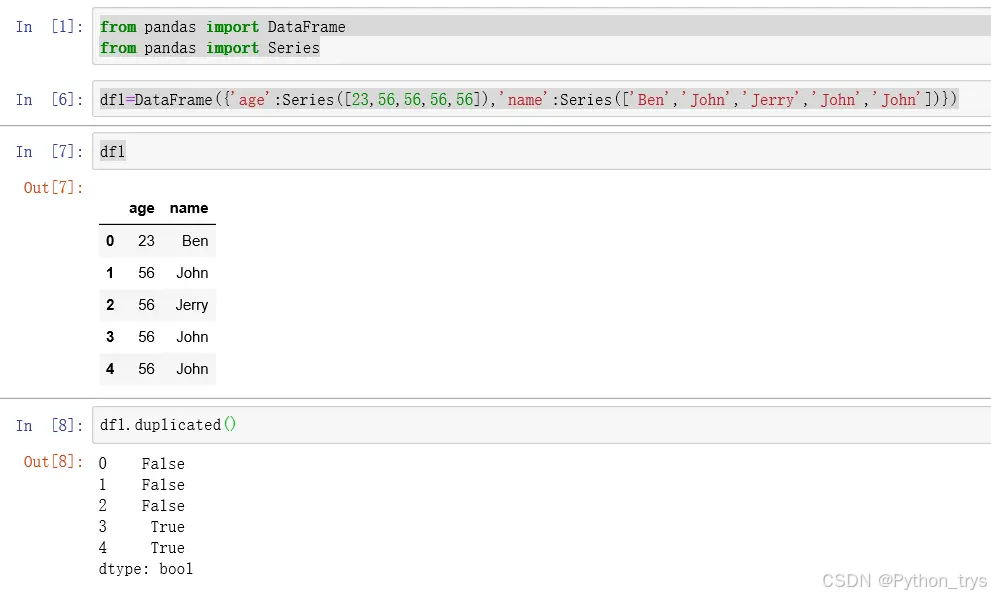
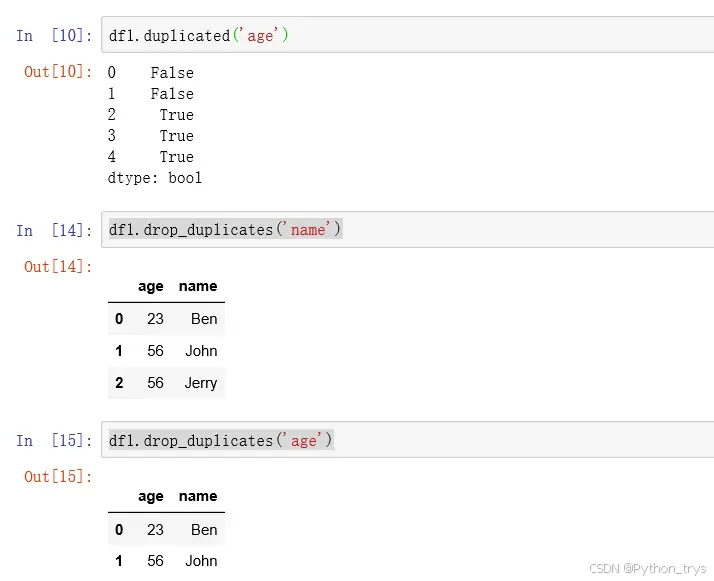
用DataFrame中duplicated方法返回布尔型Series,没有重复行False,重复行除首行均显示Ture;再用drop_duplicates方法返回一个移除重复行的DataFrame。
格式:duplicated(self,subset=none,keep=‘first’)
其中 :
subset默认识别所有列标签;
keep=‘first’ / ‘last’ 除第一次/最后一次出现,其余标记重复;
keep=False 所有相同数据标记重复;
duplicated方法、drop_duplicates方法没有设置参数,默认全部列;
frame.drop_duplicates([‘state’]) 指定部分列(state列)进行重复判断;
2.缺失值处理
缺失值的处理包含两个步骤,缺失数据识别和缺失数据处理;
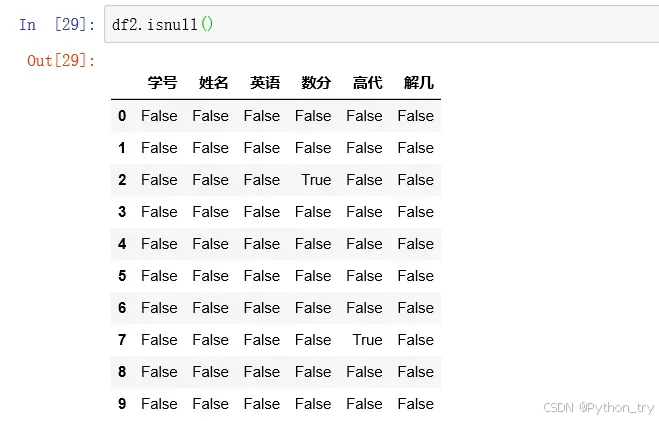
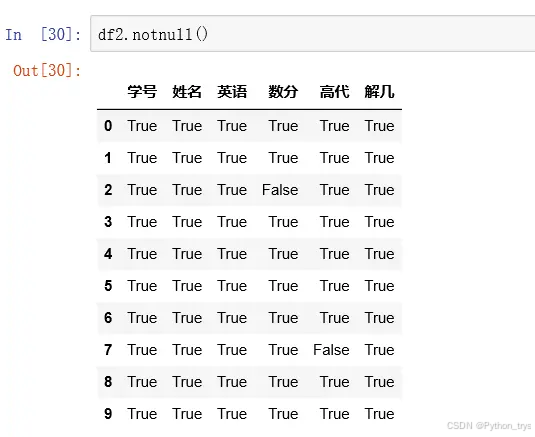
缺失值识别:使用.isnull和.notnull函数来判断缺失情况,NaN表示浮点和非浮点数组缺失数据
缺失值处理方式:数据补齐、删除对应行、不处理等方法。
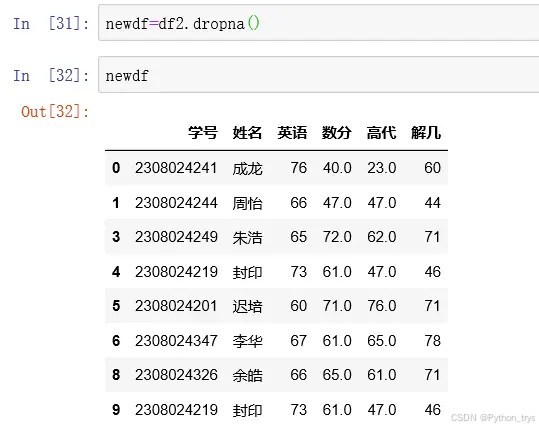
dropna() 去除值为空的数据行;
df.dropna(how=‘all’) 行里数据全空时才删除
df.dropna(how=‘all’,axis=1) 列里数据全空时才删除
df.fillna() 用其他数据替代NaN,
df.fillna(‘?’) ?填充缺失值
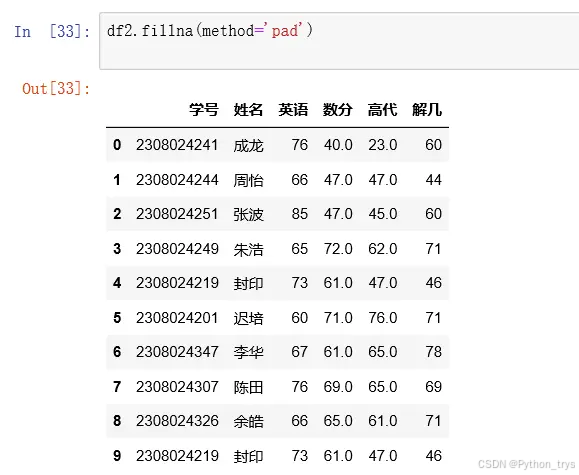
df.fillna(method=‘pad’) 前一个值替代NaN
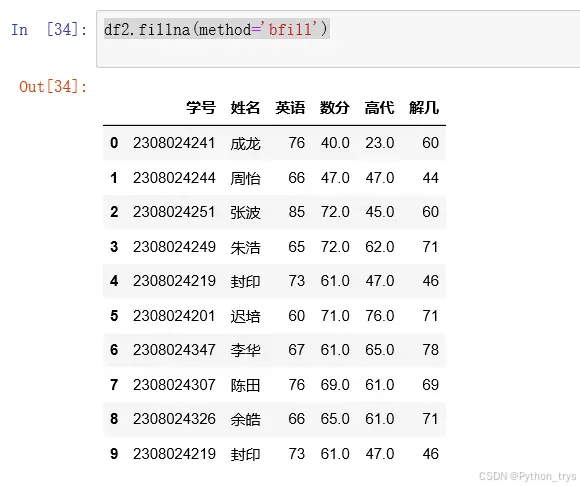
df.fillna(method=‘bfill’) 后一个值替代NaN
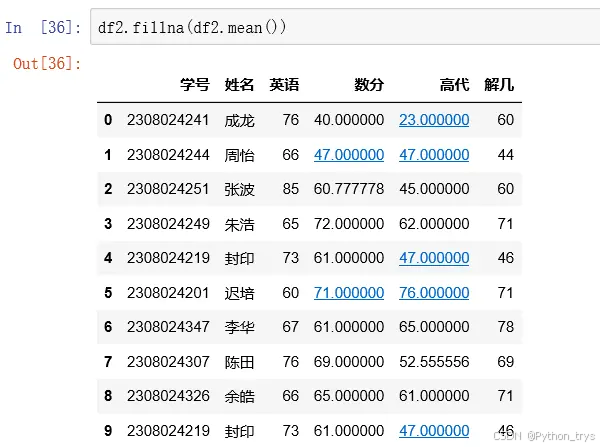
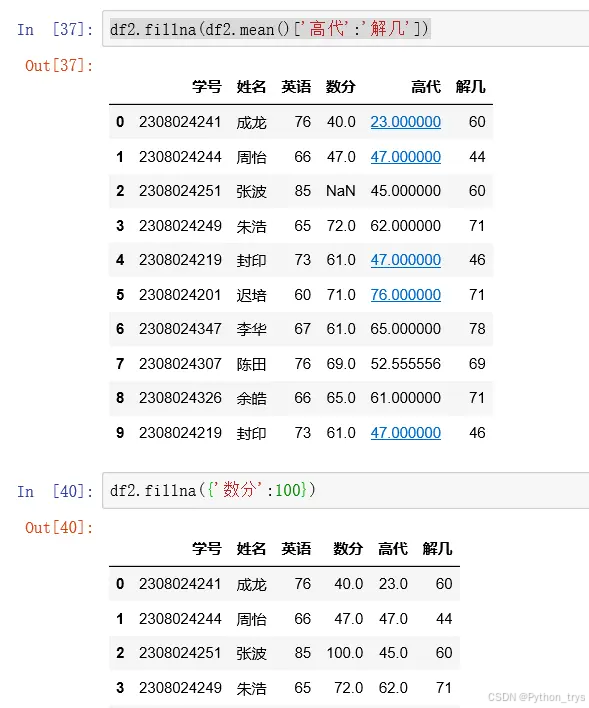
df.fillna(df.mean()) 平均值等替代NaN
df.fillna({‘A’:‘a’,‘B’:‘b’}) 传入一个字典,对A列填充值a
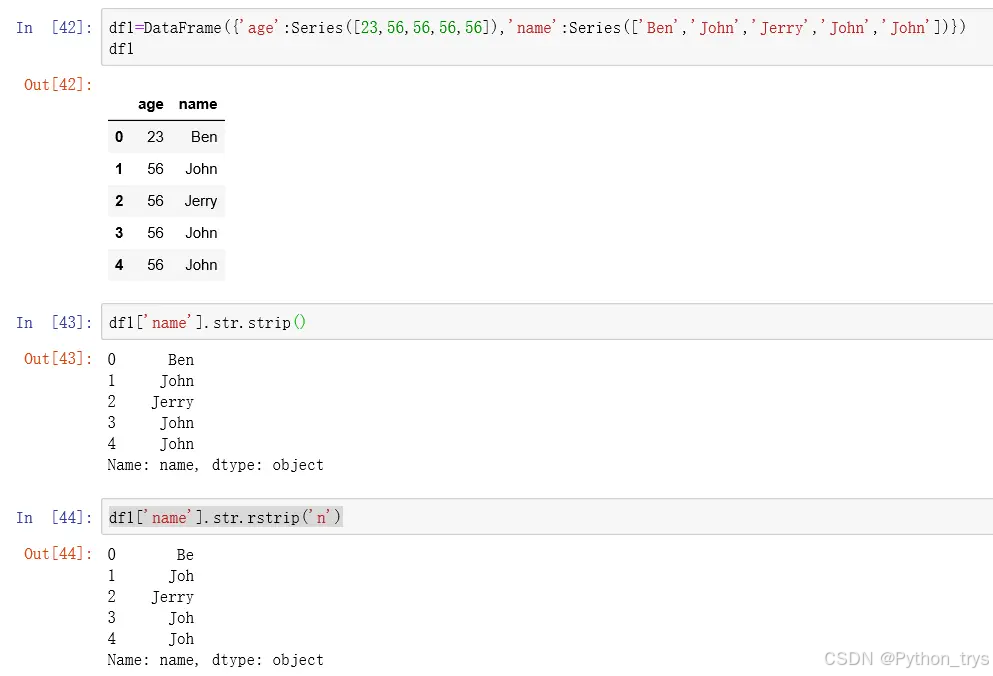
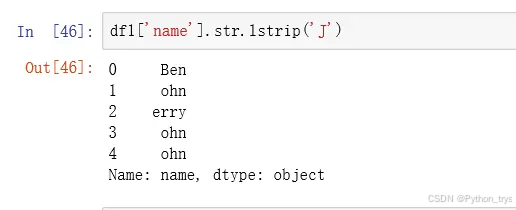
strip() 清除字符型数据左右(首尾)指定字符,默认删除空格
最后,如果你是准备学习Python或者正在学习(想通过Python兼职),下面这些你应该能用得上:
包括:Python安装包、Python web开发,Python爬虫,Python数据分析,人工智能、自动化办公等学习教程。带你从零基础系统性的学好Python!



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









