




 本文介绍了一个Python爬虫项目,详细讲解如何抓取喜马拉雅上的郭德纲相声专辑的所有音频文件,包括找数据、项目难点、源代码分析。通过学习,你可以掌握如何利用开发者工具寻找数据源,以及处理请求头中的关键数据。
本文介绍了一个Python爬虫项目,详细讲解如何抓取喜马拉雅上的郭德纲相声专辑的所有音频文件,包括找数据、项目难点、源代码分析。通过学习,你可以掌握如何利用开发者工具寻找数据源,以及处理请求头中的关键数据。
目录
很多人学习python,不知道从何学起。
很多人学习python,掌握了基本语法过后,不知道在哪里寻找案例上手。
很多已经做案例的人,却不知道如何去学习更加高深的知识。
那么针对这三类人,我给大家提供一个好的学习平台,免费领取视频教程,电子书籍,以及课程的源代码!
QQ群:101677771
项目需求:抓取专辑所有音频文件。
超详细讲解,按需查看,文末附源代码。关注我们,只涨知识,不掉发。
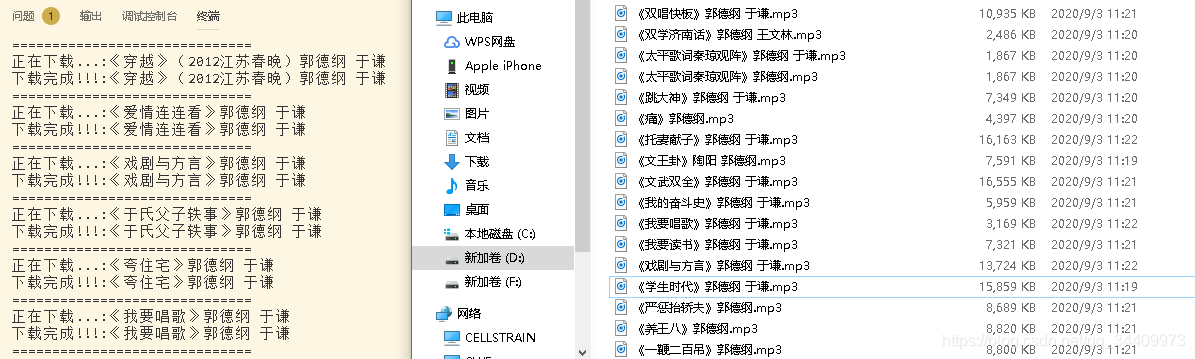
1. 项目截图
2. 找数据
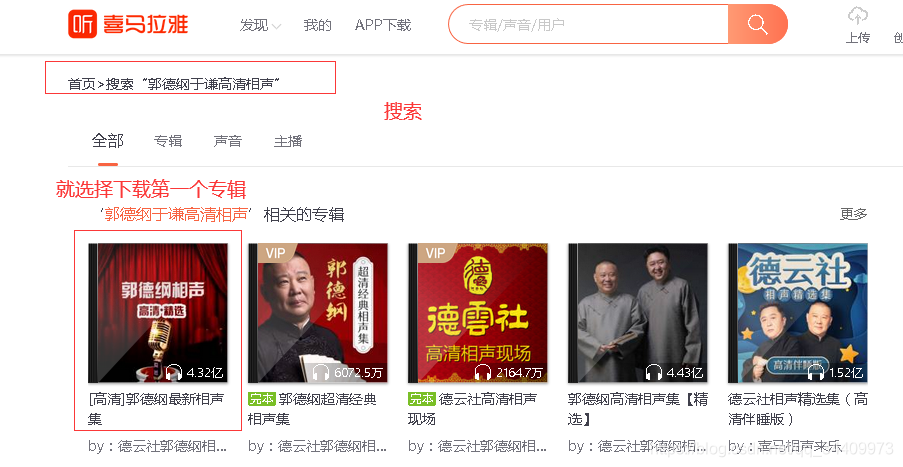
搜索郭德纲相声,选择第一个专辑,点击进入。
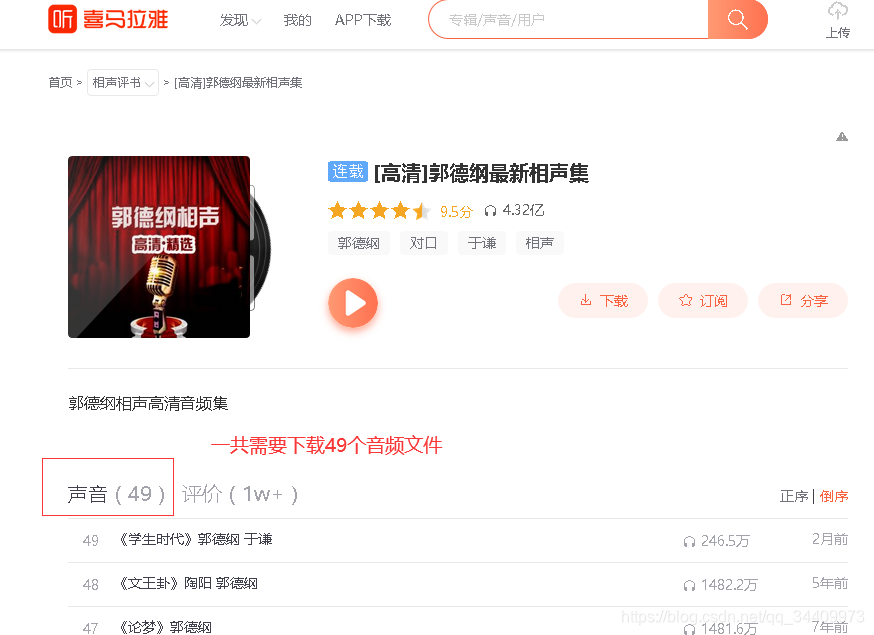
找到我们需要下载的音频文件,一共49个。
这里以谷歌浏览器来演示使用开发者工具(F12)来找数据,找数据小技巧:直接先找xhr分类,如没有数据,再找all里第一个html,一般情况下,批量采集的数据是以json数据格式获取的。
喜马拉雅的音频数据藏在点击播放后的url里。截图中的url正是音频列表的数据了。

接着点开右侧 Preview预览的文件,trackId就是区分每个文件的id。要找到下载数据的地方,就必须找到唯一的关键词。
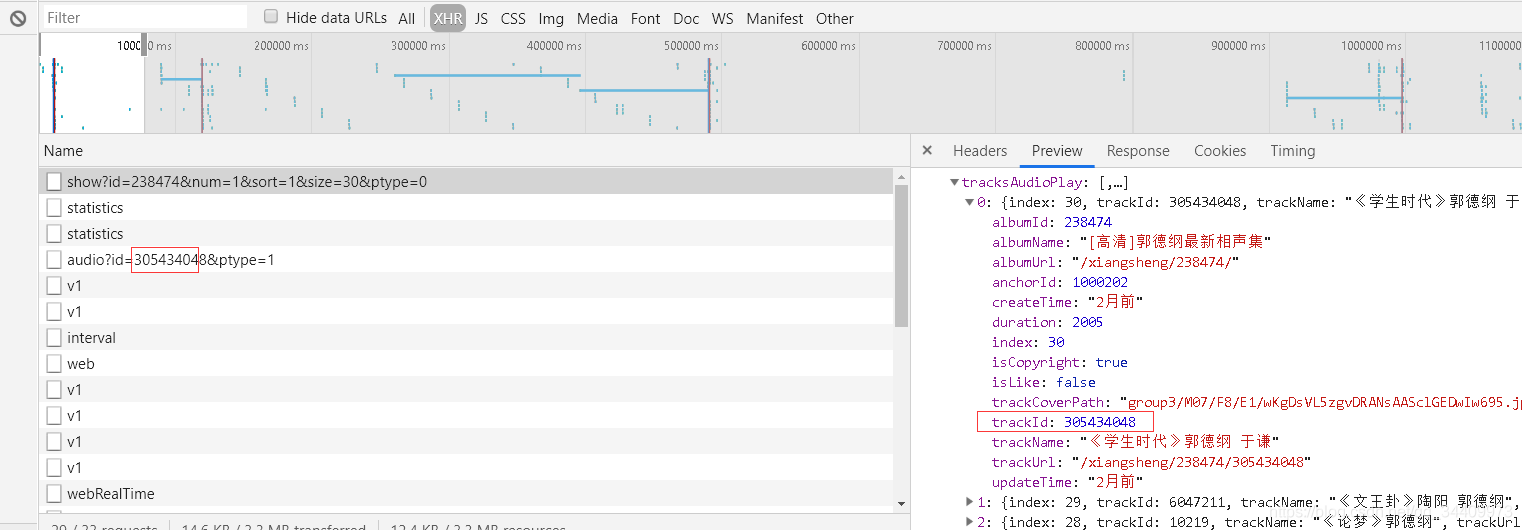
顺着左侧的url查看,发现下面这个url对应的右侧数据,有我们需要的.m4a音频文件数据。
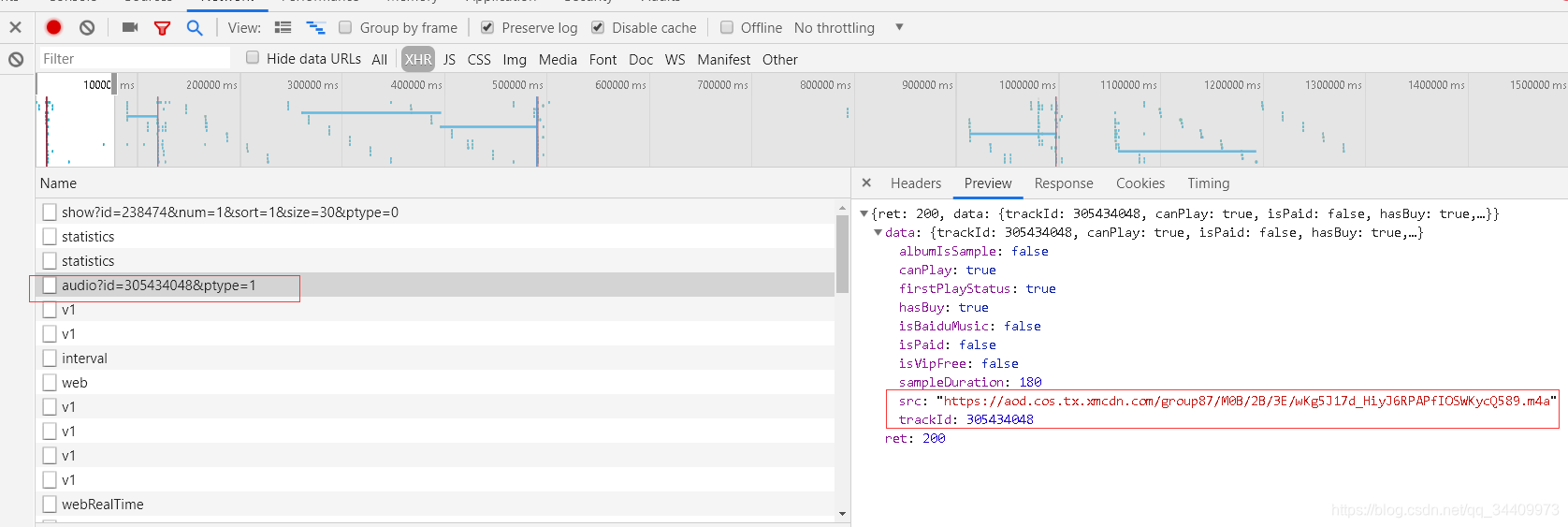
找数据就搞定了,49个音频文件列表数据和对应的音频文件地址数据。
3. 项目难点讲解
经过url的观察,发现请求头里,都会有个xm-sign的数据。没有这个数据,则抓取不到我们要的数据。

那我们就生成xm-sign数据,规则是 md5(himalaya-服务器时间戳)(100以内随机数)服务器时间戳(100以内随机数)现在时间戳。(每次抓取数据的时候,都需要调用该方法,现在时间戳和服务器时间戳相差大到一定值,则获取不到数据)
-
def getServerTime(self): -
""" -
获取喜马拉雅服务器的时间戳 -
:return: -
""" -
# 这个地址就是返回服务器时间戳的接口 -
serverTimeUrl = "https://www.ximalaya.com/revision/time" -
response = requests.get(serverTimeUrl,headers = self.headers) -
return response.text -
def getSign(self,serverTime): -
""" -
生成 xm-sign -
规则是 md5(himalaya-服务器时间戳)(100以内随机数)服务器时间戳(100以内随机数)现在时间戳 -
:param serverTime: -
:return: -
""" -
nowTime = str(round(time.time()*1000)) -
sign = str(hashlib.md5("himalaya-{}".format(serverTime).encode()).hexdigest()) + "({})".format(str(round(random.random()*100))) + serverTime + "({})".format(str(round(random.random()*100))) + nowTime -
# 将xm-sign添加到请求头中 -
self.headers["xm-sign"] = sign -
return sign
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 2249
2249

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









