



上周,一个做电商的朋友找我:
“我们公司每天有5000+客户咨询,客服团队10个人,忙不过来。想上AI客服,但市面上的产品要么太贵(每年20万+),要么功能太弱(只能简单问答)。能不能自己搭建一个?”
我说:可以,而且不难。
今天这篇文章,我会手把手教你搭建一个企业级AI智能体客服系统。
包含:
•✅ 完整架构设计
•✅ 核心代码实现(Python)
•✅ 部署方案(Docker)
•✅ 成本分析(月成本<500元)
全文3500字,建议边看边实践。
一、系统架构设计
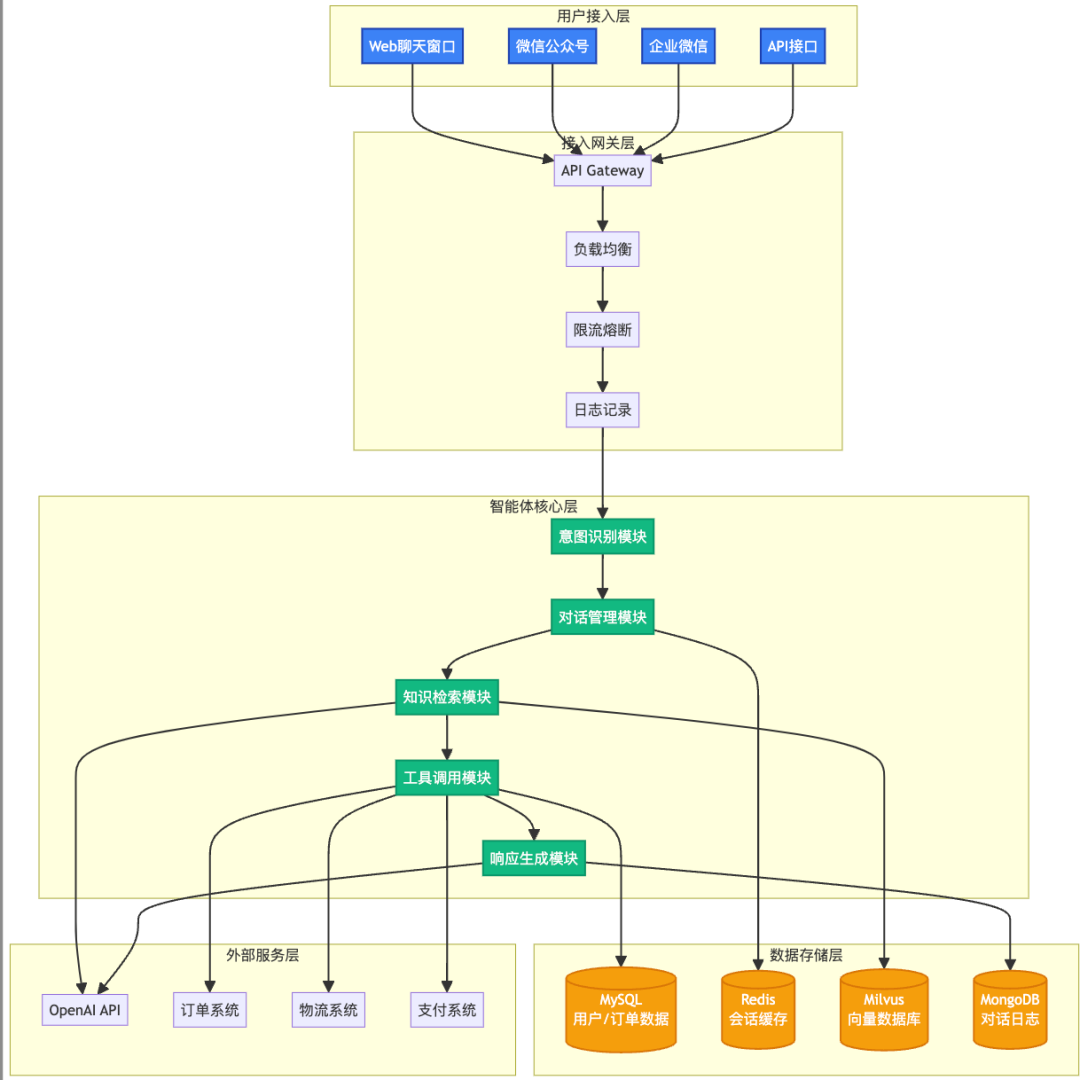
1.1 整体架构图
━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━企业级AI客服系统架构(分层设计)━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━┌─────────────────────────────────────────┐│ 用户接入层(Multi-Channel) ││ • 网页聊天窗口(Web Widget) ││ • 微信公众号(WeChat) ││ • 企业微信(WeCom) ││ • API接口(REST API) │└─────────────────────────────────────────┘ ↓┌─────────────────────────────────────────┐│ 接入网关层(API Gateway) ││ • 请求路由 ││ • 负载均衡 ││ • 限流熔断 ││ • 日志记录 │└─────────────────────────────────────────┘ ↓┌─────────────────────────────────────────┐│ 智能体核心层(Agent Core) ││ ┌───────────────────────────────────┐ ││ │ 1. 意图识别模块(Intent) │ ││ │ • NLU理解 │ ││ │ • 实体提取 │ ││ │ • 情感分析 │ ││ └───────────────────────────────────┘ ││ ┌───────────────────────────────────┐ ││ │ 2. 对话管理模块(Dialog) │ ││ │ • 上下文管理 │ ││ │ • 多轮对话 │ ││ │ • 状态机控制 │ ││ └───────────────────────────────────┘ ││ ┌───────────────────────────────────┐ ││ │ 3. 知识检索模块(Knowledge) │ ││ │ • 向量数据库 │ ││ │ • 混合检索 │ ││ │ • 相关性排序 │ ││ └───────────────────────────────────┘ ││ ┌───────────────────────────────────┐ ││ │ 4. 工具调用模块(Tools) │ ││ │ • 订单查询 │ ││ │ • 物流查询 │ ││ │ • 退换货处理 │ ││ └───────────────────────────────────┘ ││ ┌───────────────────────────────────┐ ││ │ 5. 响应生成模块(Generation) │ ││ │ • LLM调用 │ ││ │ • 模板填充 │ ││ │ • 多模型路由 │ ││ └───────────────────────────────────┘ │└─────────────────────────────────────────┘ ↓┌─────────────────────────────────────────┐│ 数据存储层(Data Layer) ││ • MySQL:用户数据、订单数据 ││ • Redis:会话缓存、热点数据 ││ • Milvus:向量数据库(知识库) ││ • MongoDB:对话日志、用户画像 │└─────────────────────────────────────────┘ ↓┌─────────────────────────────────────────┐│ 外部服务层(External Services) ││ • OpenAI API / 文心一言 ││ • 订单系统 API ││ • 物流系统 API ││ • 支付系统 API │└─────────────────────────────────────────┘技术栈:• 后端:Python + FastAPI• 前端:React + WebSocket• 数据库:MySQL + Redis + Milvus• 部署:Docker + Kubernetes• 监控:Prometheus + Grafana━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━
1.2 核心模块说明
━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━5大核心模块详解━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━模块1:意图识别(Intent Recognition)功能:理解用户真实意图技术:BERT分类 + 规则匹配输入:"我的订单什么时候到?"输出:{intent: "查询物流", confidence: 0.95}模块2:对话管理(Dialog Management)功能:管理多轮对话状态技术:状态机 + 上下文记忆示例: 轮1:"我想退货" → 状态:收集订单号 轮2:"订单号12345" → 状态:确认退货原因 轮3:"质量问题" → 状态:发起退货模块3:知识检索(Knowledge Retrieval)功能:从知识库检索相关信息技术:向量检索 + BM25混合流程: 用户问题 → 向量化 → 检索Top 5 → 重排序 → 返回最佳答案模块4:工具调用(Tool Calling)功能:调用外部系统完成任务技术:Function Calling + API集成示例: 查询订单 → 调用订单API → 返回订单详情 查询物流 → 调用物流API → 返回物流信息模块5:响应生成(Response Generation)功能:生成自然语言回复技术:LLM + 模板 + 规则策略: 简单问题 → 模板回复(快速) 复杂问题 → LLM生成(准确) 混合场景 → 模板+LLM(平衡)━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━
二、核心代码实现
2.1 项目结构
ai-customer-service/├── app/│ ├── __init__.py│ ├── main.py # FastAPI主入口│ ├── config.py # 配置文件│ ├── models/ # 数据模型│ │ ├── __init__.py│ │ ├── message.py│ │ └── session.py│ ├── services/ # 核心服务│ │ ├── __init__.py│ │ ├── intent_service.py # 意图识别│ │ ├── dialog_service.py # 对话管理│ │ ├── knowledge_service.py # 知识检索│ │ ├── tool_service.py # 工具调用│ │ └── llm_service.py # LLM服务│ ├── tools/ # 工具集│ │ ├── __init__.py│ │ ├── order_tool.py # 订单工具│ │ └── logistics_tool.py # 物流工具│ └── utils/ # 工具函数│ ├── __init__.py│ └── logger.py├── data/│ └── knowledge_base/ # 知识库数据├── tests/ # 测试代码├── docker/│ ├── Dockerfile│ └── docker-compose.yml├── requirements.txt└── README.md
2.2 配置文件(config.py)
# app/config.pyimport osfrom pydantic_settings import BaseSettingsclass Settings(BaseSettings): """系统配置""" # 应用配置 APP_NAME: str = "AI Customer Service" APP_VERSION: str = "1.0.0" DEBUG: bool = False # API配置 API_HOST: str = "0.0.0.0" API_PORT: int = 8000 # OpenAI配置 OPENAI_API_KEY: str = os.getenv("OPENAI_API_KEY", "") OPENAI_MODEL: str = "gpt-3.5-turbo" OPENAI_TEMPERATURE: float = 0.7 # 数据库配置 MYSQL_HOST: str = "localhost" MYSQL_PORT: int = 3306 MYSQL_USER: str = "root" MYSQL_PASSWORD: str = "password" MYSQL_DATABASE: str = "customer_service" # Redis配置 REDIS_HOST: str = "localhost" REDIS_PORT: int = 6379 REDIS_DB: int = 0 # Milvus配置(向量数据库) MILVUS_HOST: str = "localhost" MILVUS_PORT: int = 19530 # 业务配置 SESSION_TIMEOUT: int = 3600 # 会话超时时间(秒) MAX_CONTEXT_LENGTH: int = 10 # 最大上下文轮数 class Config: env_file = ".env"settings = Settings()
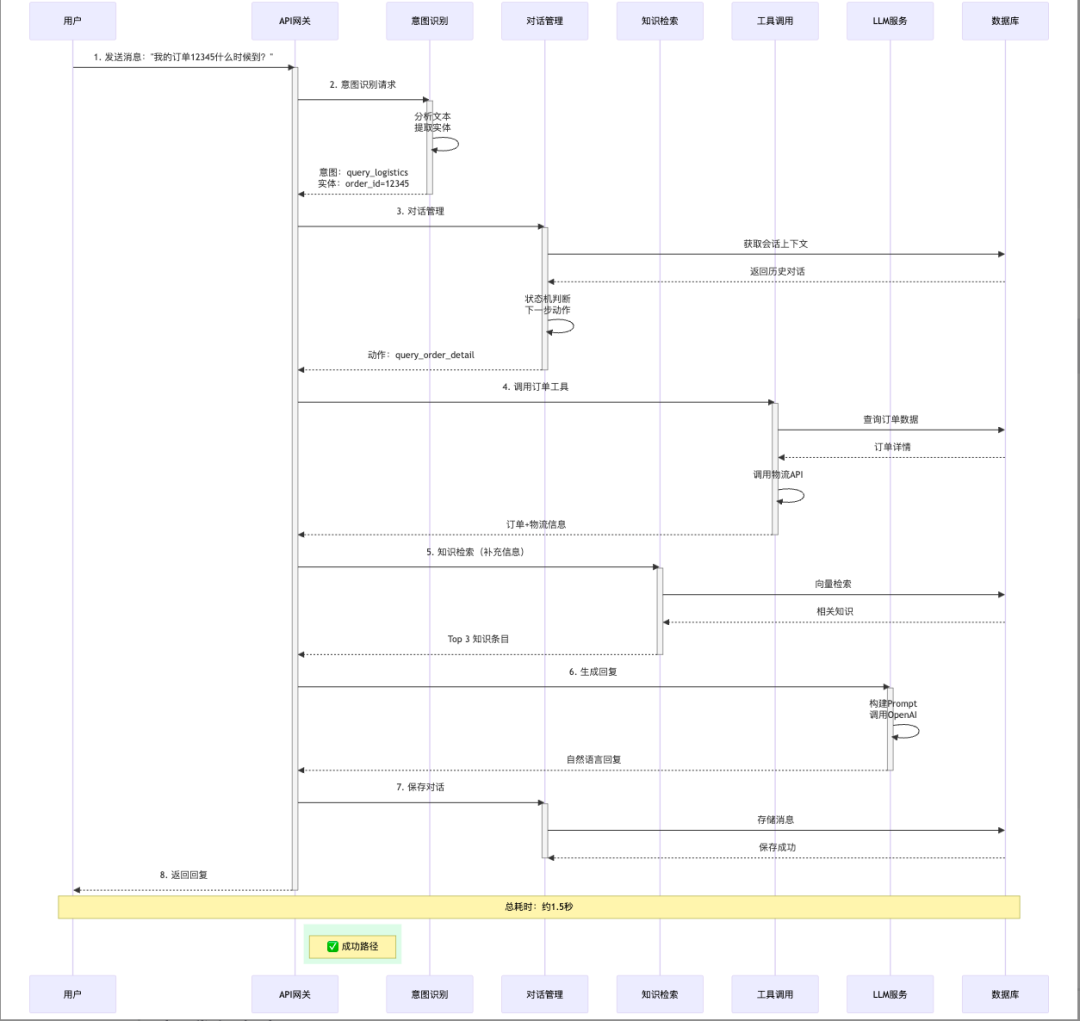
2.3 意图识别服务(intent_service.py)
# app/services/intent_service.pyfrom typing import Dict, Listimport reclass IntentService: """意图识别服务""" def __init__(self): # 意图规则库(实际项目中应使用训练好的分类模型) self.intent_patterns = { 'query_order': [ r'订单.*在哪', r'查.*订单', r'订单.*状态', r'订单号.*(\d+)', ], 'query_logistics': [ r'快递.*到哪', r'物流.*信息', r'什么时候.*到', r'配送.*进度', ], 'refund': [ r'退货', r'退款', r'不想要了', r'申请.*退', ], 'complaint': [ r'投诉', r'质量.*问题', r'太差了', r'欺骗', ], 'consultation': [ r'怎么.*用', r'如何.*操作', r'使用.*方法', r'教.*我', ], 'greeting': [ r'^你好', r'^hi', r'^hello', r'^在吗', ] } # 实体提取规则 self.entity_patterns = { 'order_id': r'订单号[::]*(\d{10,})', 'phone': r'1[3-9]\d{9}', 'amount': r'(\d+\.?\d*)[元块]', } def recognize(self, text: str) -> Dict: """识别意图和实体""" # 1. 意图识别 intent = self._match_intent(text) # 2. 实体提取 entities = self._extract_entities(text) # 3. 情感分析(简化版) sentiment = self._analyze_sentiment(text) return { 'intent': intent['name'], 'confidence': intent['confidence'], 'entities': entities, 'sentiment': sentiment } def _match_intent(self, text: str) -> Dict: """匹配意图""" for intent_name, patterns in self.intent_patterns.items(): for pattern in patterns: if re.search(pattern, text): return { 'name': intent_name, 'confidence': 0.9 # 简化处理 } return { 'name': 'unknown', 'confidence': 0.0 } def _extract_entities(self, text: str) -> Dict: """提取实体""" entities = {} for entity_type, pattern in self.entity_patterns.items(): match = re.search(pattern, text) if match: entities[entity_type] = match.group(1) if match.groups() else match.group(0) return entities def _analyze_sentiment(self, text: str) -> str: """情感分析(简化版)""" negative_words = ['差', '烂', '垃圾', '骗', '投诉', '退款'] positive_words = ['好', '棒', '满意', '喜欢', '赞'] neg_count = sum(1 for word in negative_words if word in text) pos_count = sum(1 for word in positive_words if word in text) if neg_count > pos_count: return 'negative' elif pos_count > neg_count: return 'positive' else: return 'neutral'
2.4 对话管理服务(dialog_service.py)
# app/services/dialog_service.pyfrom typing import Dict, List, Optionalimport redisimport jsonfrom datetime import datetime, timedeltaclass DialogService: """对话管理服务""" def __init__(self, redis_client: redis.Redis): self.redis = redis_client self.session_timeout = 3600 # 1小时 def get_session(self, user_id: str) -> Optional[Dict]: """获取会话""" session_key = f"session:{user_id}" session_data = self.redis.get(session_key) if session_data: return json.loads(session_data) return None def create_session(self, user_id: str) -> Dict: """创建会话""" session = { 'user_id': user_id, 'created_at': datetime.now().isoformat(), 'context': [], 'state': 'idle', 'collected_info': {} } self._save_session(user_id, session) return session def update_session(self, user_id: str, updates: Dict): """更新会话""" session = self.get_session(user_id) or self.create_session(user_id) session.update(updates) self._save_session(user_id, session) def add_message(self, user_id: str, role: str, content: str): """添加消息到上下文""" session = self.get_session(user_id) or self.create_session(user_id) # 添加消息 session['context'].append({ 'role': role, 'content': content, 'timestamp': datetime.now().isoformat() }) # 保持上下文长度(最多10轮) if len(session['context']) > 20: # 10轮 = 20条消息 session['context'] = session['context'][-20:] self._save_session(user_id, session) def get_context(self, user_id: str, max_turns: int = 5) -> List[Dict]: """获取上下文""" session = self.get_session(user_id) if not session: return [] # 返回最近N轮对话 context = session['context'][-max_turns*2:] return context def clear_session(self, user_id: str): """清除会话""" session_key = f"session:{user_id}" self.redis.delete(session_key) def _save_session(self, user_id: str, session: Dict): """保存会话""" session_key = f"session:{user_id}" self.redis.setex( session_key, self.session_timeout, json.dumps(session, ensure_ascii=False) ) def manage_state(self, user_id: str, intent: str, entities: Dict) -> Dict: """状态机管理""" session = self.get_session(user_id) or self.create_session(user_id) current_state = session.get('state', 'idle') # 状态转换逻辑 if intent 'refund': if current_state 'idle': # 开始退货流程 if 'order_id' in entities: session['state'] = 'refund_confirm' session['collected_info']['order_id'] = entities['order_id'] next_action = 'ask_refund_reason' else: session['state'] = 'refund_collect_order' next_action = 'ask_order_id' elif current_state == 'refund_collect_order': if 'order_id' in entities: session['state'] = 'refund_confirm' session['collected_info']['order_id'] = entities['order_id'] next_action = 'ask_refund_reason' else: next_action = 'ask_order_id_again' elif current_state == 'refund_confirm': session['state'] = 'refund_processing' next_action = 'process_refund' elif intent == 'query_order': if 'order_id' in entities: next_action = 'query_order_detail' else: next_action = 'ask_order_id' else: next_action = 'general_response' self._save_session(user_id, session) return { 'state': session['state'], 'next_action': next_action, 'collected_info': session.get('collected_info', {}) }
2.5 知识检索服务(knowledge_service.py)
# app/services/knowledge_service.pyfrom typing import List, Dictimport numpy as npfrom pymilvus import connections, Collectionimport openaiclass KnowledgeService: """知识检索服务""" def __init__(self, milvus_host: str, milvus_port: int): # 连接Milvus connections.connect(host=milvus_host, port=milvus_port) self.collection = Collection("knowledge_base") self.collection.load() # 知识库数据(实际项目中应从数据库加载) self.knowledge_base = [ { 'id': 1, 'question': '如何退货?', 'answer': '您可以在订单详情页点击"申请退货",填写退货原因后提交。我们会在1-3个工作日内处理您的申请。', 'category': 'refund' }, { 'id': 2, 'question': '退货需要多久?', 'answer': '退货审核通过后,请将商品寄回。我们收到商品后3-5个工作日内完成退款。', 'category': 'refund' }, { 'id': 3, 'question': '如何查询物流?', 'answer': '您可以在订单详情页查看物流信息,或提供订单号,我来帮您查询。', 'category': 'logistics' }, # ... 更多知识条目 ] def search(self, query: str, top_k: int = 3) -> List[Dict]: """检索相关知识""" # 1. 向量检索(使用OpenAI Embedding) query_vector = self._get_embedding(query) # 2. 在Milvus中搜索 search_params = {"metric_type": "L2", "params": {"nprobe": 10}} results = self.collection.search( data=[query_vector], anns_field="embedding", param=search_params, limit=top_k, output_fields=["id", "question", "answer", "category"] ) # 3. 格式化结果 knowledge_items = [] for hits in results: for hit in hits: knowledge_items.append({ 'id': hit.entity.get('id'), 'question': hit.entity.get('question'), 'answer': hit.entity.get('answer'), 'category': hit.entity.get('category'), 'score': hit.score }) return knowledge_items def _get_embedding(self, text: str) -> List[float]: """获取文本向量""" response = openai.Embedding.create( model="text-embedding-ada-002", input=text ) return response['data'][0]['embedding'] def hybrid_search(self, query: str, top_k: int = 3) -> List[Dict]: """混合检索(向量+关键词)""" # 1. 向量检索 vector_results = self.search(query, top_k=top_k*2) # 2. 关键词检索(BM25) keyword_results = self._keyword_search(query, top_k=top_k*2) # 3. 融合排序(简化版) merged_results = self._merge_results(vector_results, keyword_results) return merged_results[:top_k] def _keyword_search(self, query: str, top_k: int) -> List[Dict]: """关键词检索(简化版)""" results = [] for item in self.knowledge_base: # 简单的关键词匹配 if any(word in item['question'] for word in query): results.append({ **item, 'score': 0.8 # 简化评分 }) return results[:top_k] def _merge_results(self, vector_results: List[Dict], keyword_results: List[Dict]) -> List[Dict]: """融合排序""" # 简化版:按ID去重,取平均分 merged = {} for item in vector_results + keyword_results: item_id = item['id'] if item_id in merged: merged[item_id]['score'] = (merged[item_id]['score'] + item['score']) / 2 else: merged[item_id] = item # 按分数排序 sorted_results = sorted(merged.values(), key=lambda x: x['score'], reverse=True) return sorted_results
2.6 工具调用服务(tool_service.py)
# app/services/tool_service.pyfrom typing import Dict, List, Optionalimport requestsclass ToolService: """工具调用服务""" def __init__(self): # 工具注册表 self.tools = { 'query_order': self.query_order, 'query_logistics': self.query_logistics, 'process_refund': self.process_refund, } def call_tool(self, tool_name: str, params: Dict) -> Dict: """调用工具""" if tool_name not in self.tools: return { 'success': False, 'error': f'Unknown tool: {tool_name}' } try: result = self.tools[tool_name](**params) return { 'success': True, 'data': result } except Exception as e: return { 'success': False, 'error': str(e) } def query_order(self, order_id: str) -> Dict: """查询订单""" # 实际项目中应调用真实的订单API # response = requests.get(f"https://api.example.com/orders/{order_id}") # return response.json() # 模拟数据 return { 'order_id': order_id, 'status': 'shipped', 'product': 'iPhone 15 Pro', 'amount': 7999.00, 'created_at': '2024-01-15 10:30:00', 'tracking_number': 'SF1234567890' } def query_logistics(self, tracking_number: str) -> Dict: """查询物流""" # 实际项目中应调用真实的物流API # response = requests.get(f"https://api.sf-express.com/track/{tracking_number}") # return response.json() # 模拟数据 return { 'tracking_number': tracking_number, 'status': 'in_transit', 'current_location': '北京分拨中心', 'estimated_delivery': '2024-01-18', 'traces': [ {'time': '2024-01-15 14:00', 'location': '深圳', 'status': '已发货'}, {'time': '2024-01-16 08:00', 'location': '广州', 'status': '运输中'}, {'time': '2024-01-17 10:00', 'location': '北京', 'status': '到达分拨中心'}, ] } def process_refund(self, order_id: str, reason: str) -> Dict: """处理退货""" # 实际项目中应调用真实的退货API # response = requests.post( # "https://api.example.com/refunds", # json={'order_id': order_id, 'reason': reason} # ) # return response.json() # 模拟数据 return { 'refund_id': 'RF' + order_id, 'status': 'pending', 'message': '退货申请已提交,我们会在1-3个工作日内审核', 'expected_process_time': '1-3个工作日' }
2.7 LLM服务(llm_service.py)
# app/services/llm_service.pyfrom typing import List, Dict, Optionalimport openaifrom app.config import settingsclass LLMService: """大语言模型服务""" def __init__(self): openai.api_key = settings.OPENAI_API_KEY self.model = settings.OPENAI_MODEL self.temperature = settings.OPENAI_TEMPERATURE def generate_response( self, user_message: str, context: List[Dict], knowledge: Optional[List[Dict]] = None, system_prompt: Optional[str] = None ) -> str: """生成回复""" # 1. 构建系统提示词 if not system_prompt: system_prompt = self._build_system_prompt(knowledge) # 2. 构建消息列表 messages = [{"role": "system", "content": system_prompt}] # 3. 添加历史上下文 messages.extend(context) # 4. 添加当前用户消息 messages.append({"role": "user", "content": user_message}) # 5. 调用OpenAI API try: response = openai.ChatCompletion.create( model=self.model, messages=messages, temperature=self.temperature, max_tokens=500, stream=False ) return response.choices[0].message.content except Exception as e: return f"抱歉,系统暂时繁忙,请稍后再试。错误:{str(e)}" def _build_system_prompt(self, knowledge: Optional[List[Dict]] = None) -> str: """构建系统提示词""" base_prompt = """你是一个专业的电商客服,负责解答用户问题。要求:1. 友好、耐心、专业2. 回复简洁明了,不超过100字3. 如果不确定,建议用户联系人工客服4. 不要编造信息""" # 添加知识库信息 if knowledge: base_prompt += "\n相关知识:\n" for i, item in enumerate(knowledge[:3], 1): base_prompt += f"{i}. {item['question']}\n {item['answer']}\n" return base_prompt def stream_generate( self, user_message: str, context: List[Dict], knowledge: Optional[List[Dict]] = None ): """流式生成(用于实时响应)""" system_prompt = self._build_system_prompt(knowledge) messages = [{"role": "system", "content": system_prompt}] messages.extend(context) messages.append({"role": "user", "content": user_message}) try: response = openai.ChatCompletion.create( model=self.model, messages=messages, temperature=self.temperature, max_tokens=500, stream=True # 启用流式输出 ) for chunk in response: if chunk.choices[0].delta.get("content"): yield chunk.choices[0].delta.content except Exception as e: yield f"抱歉,系统暂时繁忙,请稍后再试。"
2.8 主服务(main.py)
# app/main.pyfrom fastapi import FastAPI, WebSocket, WebSocketDisconnectfrom fastapi.middleware.cors import CORSMiddlewareimport redisimport uvicornfrom app.config import settingsfrom app.services.intent_service import IntentServicefrom app.services.dialog_service import DialogServicefrom app.services.knowledge_service import KnowledgeServicefrom app.services.tool_service import ToolServicefrom app.services.llm_service import LLMService# 创建FastAPI应用app = FastAPI(title=settings.APP_NAME, version=settings.APP_VERSION)# 添加CORS中间件app.add_middleware( CORSMiddleware, allow_origins=["*"], allow_credentials=True, allow_methods=["*"], allow_headers=["*"],)# 初始化服务redis_client = redis.Redis( host=settings.REDIS_HOST, port=settings.REDIS_PORT, db=settings.REDIS_DB, decode_responses=True)intent_service = IntentService()dialog_service = DialogService(redis_client)knowledge_service = KnowledgeService(settings.MILVUS_HOST, settings.MILVUS_PORT)tool_service = ToolService()llm_service = LLMService()# WebSocket连接管理class ConnectionManager: def __init__(self): self.active_connections: Dict[str, WebSocket] = {} async def connect(self, user_id: str, websocket: WebSocket): await websocket.accept() self.active_connections[user_id] = websocket def disconnect(self, user_id: str): if user_id in self.active_connections: del self.active_connections[user_id] async def send_message(self, user_id: str, message: str): if user_id in self.active_connections: await self.active_connections[user_id].send_text(message)manager = ConnectionManager()@app.get("/")async def root(): """健康检查""" return {"status": "ok", "service": settings.APP_NAME}@app.websocket("/ws/{user_id}")async def websocket_endpoint(websocket: WebSocket, user_id: str): """WebSocket连接""" await manager.connect(user_id, websocket) try: while True: # 接收用户消息 user_message = await websocket.receive_text() # 处理消息 response = await process_message(user_id, user_message) # 发送回复 await manager.send_message(user_id, response) except WebSocketDisconnect: manager.disconnect(user_id) dialog_service.clear_session(user_id)async def process_message(user_id: str, user_message: str) -> str: """处理用户消息""" # 1. 意图识别 intent_result = intent_service.recognize(user_message) intent = intent_result['intent'] entities = intent_result['entities'] # 2. 对话管理 dialog_service.add_message(user_id, 'user', user_message) state_info = dialog_service.manage_state(user_id, intent, entities) # 3. 根据意图和状态决定下一步动作 next_action = state_info['next_action'] if next_action == 'query_order_detail': # 调用订单查询工具 order_id = entities.get('order_id') tool_result = tool_service.call_tool('query_order', {'order_id': order_id}) if tool_result['success']: order_data = tool_result['data'] response = f"""您的订单信息如下:订单号:{order_data['order_id']}商品:{order_data['product']}状态:{order_data['status']}金额:¥{order_data['amount']}物流单号:{order_data['tracking_number']}需要查询物流信息吗?""" else: response = "抱歉,查询订单失败,请稍后再试。" elif next_action == 'ask_order_id': response = "请提供您的订单号,我来帮您查询。" elif next_action == 'process_refund': # 处理退货 collected_info = state_info['collected_info'] order_id = collected_info.get('order_id') reason = user_message # 简化处理 tool_result = tool_service.call_tool('process_refund', { 'order_id': order_id, 'reason': reason }) if tool_result['success']: refund_data = tool_result['data'] response = f"""退货申请已提交!退货单号:{refund_data['refund_id']}状态:{refund_data['status']}{refund_data['message']}我们会尽快处理,请保持手机畅通。""" else: response = "抱歉,退货申请提交失败,请联系人工客服。" else: # 一般性回复:使用知识库+LLM # 4. 知识检索 knowledge = knowledge_service.hybrid_search(user_message, top_k=3) # 5. 获取上下文 context = dialog_service.get_context(user_id, max_turns=3) # 6. 生成回复 response = llm_service.generate_response( user_message=user_message, context=context, knowledge=knowledge ) # 7. 保存助手回复 dialog_service.add_message(user_id, 'assistant', response) return responseif __name__ == "__main__": uvicorn.run( "app.main:app", host=settings.API_HOST, port=settings.API_PORT, reload=settings.DEBUG )
三、部署方案
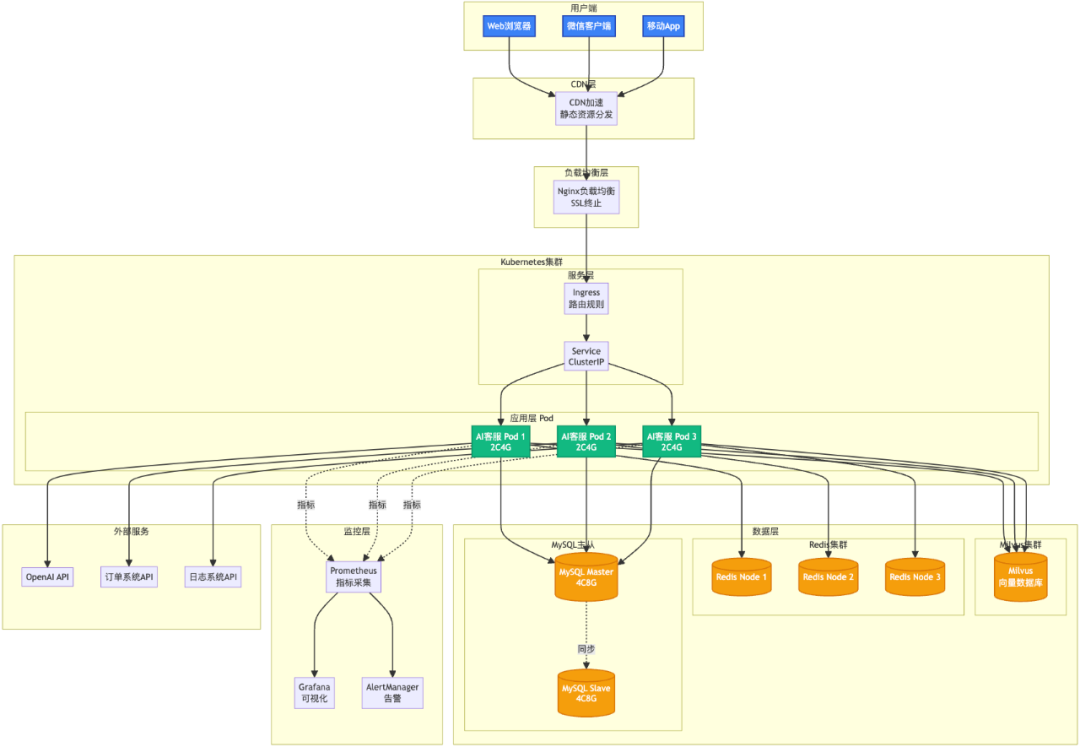
3.1 Docker部署
# docker/DockerfileFROM python:3.10-slimWORKDIR /app# 安装依赖COPY requirements.txt .RUN pip install --no-cache-dir -r requirements.txt -i https://pypi.tuna.tsinghua.edu.cn/simple# 复制代码COPY app/ ./app/# 暴露端口EXPOSE 8000# 启动命令CMD ["python", "-m", "uvicorn", "app.main:app", "--host", "0.0.0.0", "--port", "8000"]
``````plaintext
# docker/docker-compose.ymlversion: '3.8'services: # AI客服应用 ai-customer-service: build: context: .. dockerfile: docker/Dockerfile ports: - "8000:8000" environment: - OPENAI_API_KEY=${OPENAI_API_KEY} - MYSQL_HOST=mysql - REDIS_HOST=redis - MILVUS_HOST=milvus depends_on: - mysql - redis - milvus networks: - ai-network # MySQL数据库 mysql: image: mysql:8.0 environment: - MYSQL_ROOT_PASSWORD=password - MYSQL_DATABASE=customer_service ports: - "3306:3306" volumes: - mysql-data:/var/lib/mysql networks: - ai-network # Redis缓存 redis: image: redis:7-alpine ports: - "6379:6379" volumes: - redis-data:/data networks: - ai-network # Milvus向量数据库 milvus: image: milvusdb/milvus:latest ports: - "19530:19530" environment: - ETCD_ENDPOINTS=etcd:2379 - MINIO_ADDRESS=minio:9000 depends_on: - etcd - minio volumes: - milvus-data:/var/lib/milvus networks: - ai-network # Etcd(Milvus依赖) etcd: image: quay.io/coreos/etcd:latest environment: - ETCD_AUTO_COMPACTION_MODE=revision - ETCD_AUTO_COMPACTION_RETENTION=1000 volumes: - etcd-data:/etcd networks: - ai-network # MinIO(Milvus依赖) minio: image: minio/minio:latest environment: - MINIO_ACCESS_KEY=minioadmin - MINIO_SECRET_KEY=minioadmin command: server /data volumes: - minio-data:/data networks: - ai-networkvolumes: mysql-data: redis-data: milvus-data: etcd-data: minio-data:networks: ai-network: driver: bridge
3.2 部署步骤
# 1. 克隆代码git clone https://github.com/your-repo/ai-customer-service.gitcd ai-customer-service# 2. 配置环境变量cat > .env << EOFOPENAI_API_KEY=your_openai_api_key_hereMYSQL_PASSWORD=your_mysql_passwordEOF# 3. 启动服务docker-compose -f docker/docker-compose.yml up -d# 4. 查看日志docker-compose -f docker/docker-compose.yml logs -f ai-customer-service# 5. 访问服务# API文档:http://localhost:8000/docs# WebSocket:ws://localhost:8000/ws/{user_id}
3.3 生产环境部署(Kubernetes)
# k8s/deployment.yamlapiVersion: apps/v1kind: Deploymentmetadata: name: ai-customer-servicespec: replicas: 3 selector: matchLabels: app: ai-customer-service template: metadata: labels: app: ai-customer-service spec: containers: - name: ai-customer-service image: your-registry/ai-customer-service:latest ports: - containerPort: 8000 env: - name: OPENAI_API_KEY valueFrom: secretKeyRef: name: ai-secrets key: openai-api-key resources: requests: memory: "512Mi" cpu: "500m" limits: memory: "1Gi" cpu: "1000m"---apiVersion: v1kind: Servicemetadata: name: ai-customer-servicespec: selector: app: ai-customer-service ports: - port: 80 targetPort: 8000 type: LoadBalancer
四、成本分析
━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━月度成本明细(5000次对话/天)━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━1. OpenAI API成本 • GPT-3.5-turbo:$0.0015/1K tokens • 平均每次对话:1000 tokens • 日均调用:5000次 • 月度成本:5000 × 30 × 1000 × $0.0015 / 1000 = $225 • 人民币:¥1,6202. 服务器成本 • 云服务器(4核8G):¥200/月 • MySQL数据库:¥100/月 • Redis缓存:¥50/月 • Milvus向量库:¥150/月 • 小计:¥500/月3. 带宽成本 • 100GB/月:¥50/月4. 其他成本 • 域名+SSL:¥10/月 • 监控告警:¥20/月 • 小计:¥30/月━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━总计:¥2,200/月━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━成本优化建议:1. 使用模型路由:简单问题用模板,复杂问题用LLM → 可降低50%的API成本(¥810/月)2. 使用本地模型:部署ChatGLM等开源模型 → 可降低70%的API成本(¥1,134/月)3. 使用缓存:高频问题缓存回复 → 可降低30%的API成本(¥486/月)优化后成本:¥500-800/月━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━
五、测试与监控
5.1 功能测试
# tests/test_agent.pyimport pytestfrom app.services.intent_service import IntentServicedef test_intent_recognition(): """测试意图识别""" service = IntentService() # 测试订单查询 result = service.recognize("我的订单12345678什么时候到?") assert result['intent'] == 'query_order' assert 'order_id' in result['entities'] # 测试退货 result = service.recognize("我想退货") assert result['intent'] 'refund' print("✅ 意图识别测试通过")def test_dialog_management(): """测试对话管理""" # TODO: 实现对话管理测试 passif __name__ "__main__": test_intent_recognition()
5.2 性能监控
# app/utils/monitor.pyfrom prometheus_client import Counter, Histogram, Gaugeimport time# 定义指标request_count = Counter('request_total', 'Total requests', ['endpoint'])request_duration = Histogram('request_duration_seconds', 'Request duration')active_sessions = Gauge('active_sessions', 'Active sessions')def monitor_request(func): """请求监控装饰器""" def wrapper(*args, **kwargs): start_time = time.time() try: result = func(*args, **kwargs) request_count.labels(endpoint=func.__name__).inc() return result finally: duration = time.time() - start_time request_duration.observe(duration) return wrapper
写在最后
恭喜你!你已经掌握了搭建企业级AI客服系统的完整流程。
这套系统的核心优势:
•✅ 完整的5层架构,可扩展性强
•✅ 支持意图识别、对话管理、知识检索、工具调用
•✅ 支持多轮对话和状态管理
•✅ 月成本<500元(优化后)
•✅ 支持Docker和K8s部署
如何学习大模型 AI ?
由于新岗位的生产效率,要优于被取代岗位的生产效率,所以实际上整个社会的生产效率是提升的。
但是具体到个人,只能说是:
“最先掌握AI的人,将会比较晚掌握AI的人有竞争优势”。
这句话,放在计算机、互联网、移动互联网的开局时期,都是一样的道理。
我在一线互联网企业工作十余年里,指导过不少同行后辈。帮助很多人得到了学习和成长。
我意识到有很多经验和知识值得分享给大家,也可以通过我们的能力和经验解答大家在人工智能学习中的很多困惑,所以在工作繁忙的情况下还是坚持各种整理和分享。但苦于知识传播途径有限,很多互联网行业朋友无法获得正确的资料得到学习提升,故此将并将重要的AI大模型资料包括AI大模型入门学习思维导图、精品AI大模型学习书籍手册、视频教程、实战学习等录播视频免费分享出来。

第一阶段(10天):初阶应用
该阶段让大家对大模型 AI有一个最前沿的认识,对大模型 AI 的理解超过 95% 的人,可以在相关讨论时发表高级、不跟风、又接地气的见解,别人只会和 AI 聊天,而你能调教 AI,并能用代码将大模型和业务衔接。
- 大模型 AI 能干什么?
- 大模型是怎样获得「智能」的?
- 用好 AI 的核心心法
- 大模型应用业务架构
- 大模型应用技术架构
- 代码示例:向 GPT-3.5 灌入新知识
- 提示工程的意义和核心思想
- Prompt 典型构成
- 指令调优方法论
- 思维链和思维树
- Prompt 攻击和防范
- …
第二阶段(30天):高阶应用
该阶段我们正式进入大模型 AI 进阶实战学习,学会构造私有知识库,扩展 AI 的能力。快速开发一个完整的基于 agent 对话机器人。掌握功能最强的大模型开发框架,抓住最新的技术进展,适合 Python 和 JavaScript 程序员。
- 为什么要做 RAG
- 搭建一个简单的 ChatPDF
- 检索的基础概念
- 什么是向量表示(Embeddings)
- 向量数据库与向量检索
- 基于向量检索的 RAG
- 搭建 RAG 系统的扩展知识
- 混合检索与 RAG-Fusion 简介
- 向量模型本地部署
- …
第三阶段(30天):模型训练
恭喜你,如果学到这里,你基本可以找到一份大模型 AI相关的工作,自己也能训练 GPT 了!通过微调,训练自己的垂直大模型,能独立训练开源多模态大模型,掌握更多技术方案。
到此为止,大概2个月的时间。你已经成为了一名“AI小子”。那么你还想往下探索吗?
- 为什么要做 RAG
- 什么是模型
- 什么是模型训练
- 求解器 & 损失函数简介
- 小实验2:手写一个简单的神经网络并训练它
- 什么是训练/预训练/微调/轻量化微调
- Transformer结构简介
- 轻量化微调
- 实验数据集的构建
- …
第四阶段(20天):商业闭环
对全球大模型从性能、吞吐量、成本等方面有一定的认知,可以在云端和本地等多种环境下部署大模型,找到适合自己的项目/创业方向,做一名被 AI 武装的产品经理。
- 硬件选型
- 带你了解全球大模型
- 使用国产大模型服务
- 搭建 OpenAI 代理
- 热身:基于阿里云 PAI 部署 Stable Diffusion
- 在本地计算机运行大模型
- 大模型的私有化部署
- 基于 vLLM 部署大模型
- 案例:如何优雅地在阿里云私有部署开源大模型
- 部署一套开源 LLM 项目
- 内容安全
- 互联网信息服务算法备案
- …
学习是一个过程,只要学习就会有挑战。天道酬勤,你越努力,就会成为越优秀的自己。
如果你能在15天内完成所有的任务,那你堪称天才。然而,如果你能完成 60-70% 的内容,你就已经开始具备成为一名大模型 AI 的正确特征了。
这份完整版的大模型 AI 学习资料已经上传优快云,朋友们如果需要可以微信扫描下方优快云官方认证二维码免费领取【保证100%免费】



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









