 用LLM打造专属SQL助手
用LLM打造专属SQL助手




如何高效的利用数据库里面的相关信息,十分重要,“Text-to-SQL”是从数据库中获取知识的重要手段。
具体代码参考如下(建议大家在沙箱中运行):
我们正在做的事情的快速演示
1. 所需技术栈
先列出我们自定义智能体所需的全部依赖,并不多:
- Llama-index:负责编排、文档索引与检索
- SQLAlchemy:用于创建本地 SQL 数据库
- LLM 服务——如果你没有本地部署的大模型,可直接调用 OpenAI、Claude 等 API;若已自建服务,更好!本文采用 API 调用方式,方便大家复现。
- 向量数据库——本智能体既要查 SQL 引擎,又要查向量数据库(RAG),因此需要存放文档。如果你嫌麻烦,直接用 LlamaCloud!创建索引、上传文档,一步到位,无需复杂配置。
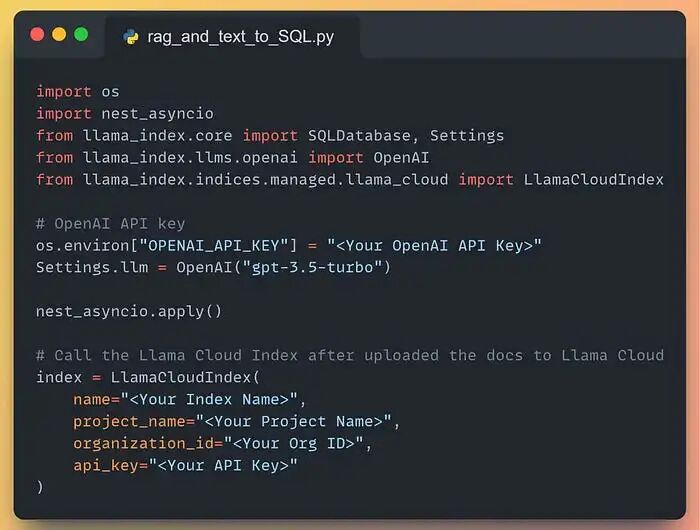
设置 API 与 LlamaCloud 索引
2. 开始构建
在贴代码之前,先给出整体思路。下图展示了智能体的工作流程:
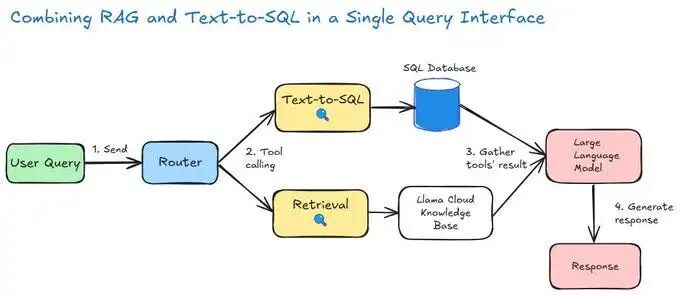
智能体功能概览
- 用户提问——例如:“洛杉矶的历史名称是什么?”
- 路由决策——智能体分析问题,决定调用哪些工具
- 信息收集——按需查询 SQL 数据库、向量数据库(通过 LlamaCloud)或两者
- 返回答案——最终向用户输出简洁准确的结果
够直观吧?下面逐块拆解。
2.1 创建示例 SQL 数据库
示例中,我们在内存里建一张极简表,包含三列:
- 城市名称
- 城市人口
- 所在州
若你已有一套数据库(甚至整库整服务器),直接替换连接配置即可。
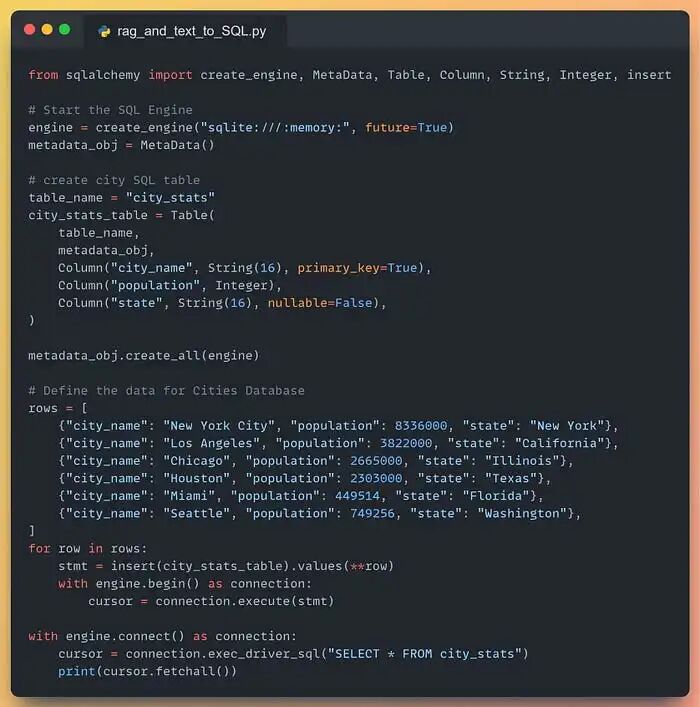
示例内存数据库
2.2 工具(最有趣的部分!)
没有工具的智能体就像没有厨具的厨师——毫无用处。
我们准备两大工具:
- 工具 #1:SQL 查询工具,可访问数据库引擎
- 工具 #2:RAG 检索工具,可访问 LlamaCloud 索引
然后将二者合并为一个统一查询引擎工具,灵活取数。看图:
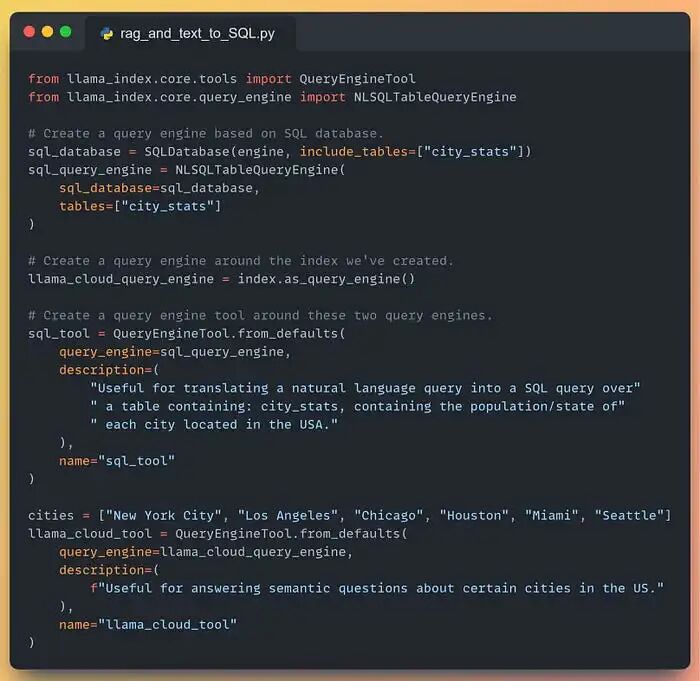
工具
2.3 围绕查询引擎构建智能体
现在需要一个工作流充当智能体的大脑,它使用四个关键事件:
**GatherToolsEvent**:收集需调用的工具(由 LLM 决定)**ToolCallEvent**:单个工具调用事件,可并发触发多次**ToolCallEventResult**:捕获工具调用结果**GatherEvent**:由调度器返回,触发ToolCallEvent
工作流运行步骤:
步骤 1 — chat():将用户消息加入对话历史,与可用工具一起喂给 LLM,由 LLM 决定调用哪些工具,返回 GatherToolsEvent。
步骤 2 — dispatch_calls():通过 send_event() 为 LLM 选中的每个工具触发 ToolCallEvent,返回包含工具总数的 GatherEvent。
步骤 3 — call_tool():执行单个工具调用,如有多个工具则多次执行,并将结果追加到对话历史,返回 ToolCallEventResult。
步骤 4 — gather():使用 collect_events() 收集全部工具结果,等待全部完成后,将完整对话历史(含工具结果)再次喂给 LLM 生成最终答案。
from typing importDict, List, Any, Optionalfrom llama_index.core.tools import BaseToolfrom llama_index.core.llms import ChatMessagefrom llama_index.core.llms.llm import ToolSelection, LLMfrom llama_index.core.workflow import ( Workflow, Event, StartEvent, StopEvent, step,)from llama_index.core.base.response.schema import Responsefrom llama_index.core.tools import FunctionToolclassInputEvent(Event): """输入事件。"""classGatherToolsEvent(Event): """收集工具事件""" tool_calls: AnyclassToolCallEvent(Event): """工具调用事件""" tool_call: ToolSelectionclassToolCallEventResult(Event): """工具调用结果事件。""" msg: ChatMessageclassRouterOutputAgentWorkflow(Workflow): """自定义路由输出智能体工作流。""" def__init__(self, tools: List[BaseTool], timeout: Optional[float] = 10.0, disable_validation: bool = False, verbose: bool = False, llm: Optional[LLM] = None, chat_history: Optional[List[ChatMessage]] = None, ): """构造函数。""" super().__init__(timeout=timeout, disable_validation=disable_validation, verbose=verbose) self.tools: List[BaseTool] = tools self.tools_dict: Optional[Dict[str, BaseTool]] = {tool.metadata.name: tool for tool inself.tools} self.llm: LLM = llm or OpenAI(temperature=0, model="gpt-3.5-turbo") self.chat_history: List[ChatMessage] = chat_history or [] defreset(self) -> None: """重置对话历史。""" self.chat_history = [] @step() asyncdefprepare_chat(self, ev: StartEvent) -> InputEvent: message = ev.get("message") if message isNone: raise ValueError("'message' 字段必填。") # 将消息加入对话历史 chat_history = self.chat_history chat_history.append(ChatMessage(role="user", content=message)) return InputEvent() @step() asyncdefchat(self, ev: InputEvent) -> GatherToolsEvent | StopEvent: """将消息加入对话历史,然后获取工具调用。""" # 将消息与工具一起送入 LLM chat_res = awaitself.llm.achat_with_tools( self.tools, chat_history=self.chat_history, verbose=self._verbose, allow_parallel_tool_calls=True ) tool_calls = self.llm.get_tool_calls_from_response(chat_res, error_on_no_tool_call=False) ai_message = chat_res.message self.chat_history.append(ai_message) ifself._verbose: print(f"对话消息: {ai_message.content}") # 无工具调用,直接返回对话消息 ifnot tool_calls: return StopEvent(result=ai_message.content) return GatherToolsEvent(tool_calls=tool_calls) @step(pass_context=True) asyncdefdispatch_calls(self, ctx: Context, ev: GatherToolsEvent) -> ToolCallEvent: """调度调用。""" tool_calls = ev.tool_calls await ctx.set("num_tool_calls", len(tool_calls)) # 触发工具调用事件 for tool_call in tool_calls: ctx.send_event(ToolCallEvent(tool_call=tool_call)) returnNone @step() asyncdefcall_tool(self, ev: ToolCallEvent) -> ToolCallEventResult: """调用工具。""" tool_call = ev.tool_call # 获取工具 ID 与函数调用 id_ = tool_call.tool_id ifself._verbose: print(f"调用函数 {tool_call.tool_name},参数 {tool_call.tool_kwargs}") # 调用函数并将结果封装为对话消息 tool = self.tools_dict[tool_call.tool_name] output = await tool.acall(**tool_call.tool_kwargs) msg = ChatMessage( name=tool_call.tool_name, content=str(output), role="tool", additional_kwargs={ "tool_call_id": id_, "name": tool_call.tool_name } ) return ToolCallEventResult(msg=msg) @step(pass_context=True) asyncdefgather(self, ctx: Context, ev: ToolCallEventResult) -> StopEvent | None: """收集工具调用结果。""" # 等待所有工具调用事件完成 tool_events = ctx.collect_events(ev, [ToolCallEventResult] * await ctx.get("num_tool_calls")) ifnot tool_events: returnNone for tool_event in tool_events: # 将工具调用消息追加到对话历史 self.chat_history.append(tool_event.msg) # 所有工具调用完成后,将输入事件传回,重启智能体循环 return InputEvent()
完成!
下图序列图可帮助你可视化流程:
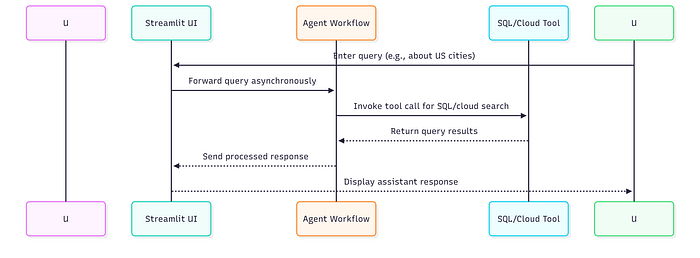
智能体整体流程
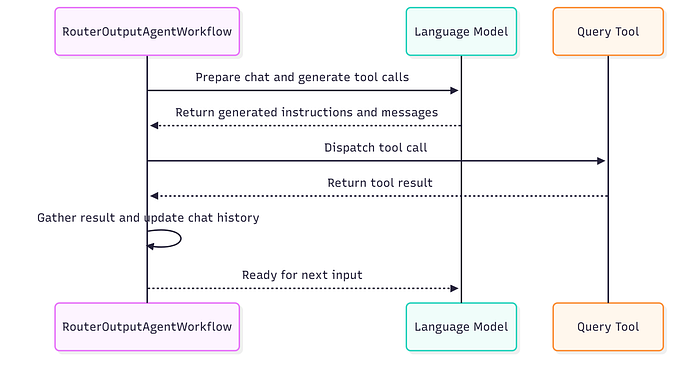
智能体内的工具调用
测试时刻:
启动智能体并跑几个查询:
# 创建工作流实例wf = RouterOutputAgentWorkflow(tools=[sql_tool, llama_cloud_tool], verbose=True, timeout=120)# 测试流程from IPython.display import display, Markdownresult = await wf.run(message="Which city has the highest population?")display(Markdown(result))
如何高效转型Al大模型领域?
作为一名在一线互联网行业奋斗多年的老兵,我深知持续学习和进步的重要性,尤其是在复杂且深入的Al大模型开发领域。为什么精准学习如此关键?
- 系统的技术路线图:帮助你从入门到精通,明确所需掌握的知识点。
- 高效有序的学习路径:避免无效学习,节省时间,提升效率。
- 完整的知识体系:建立系统的知识框架,为职业发展打下坚实基础。
AI大模型从业者的核心竞争力
- 持续学习能力:Al技术日新月异,保持学习是关键。
- 跨领域思维:Al大模型需要结合业务场景,具备跨领域思考能力的从业者更受欢迎。
- 解决问题的能力:AI大模型的应用需要解决实际问题,你的编程经验将大放异彩。
以前总有人问我说:老师能不能帮我预测预测将来的风口在哪里?
现在没什么可说了,一定是Al;我们国家已经提出来:算力即国力!
未来已来,大模型在未来必然走向人类的生活中,无论你是前端,后端还是数据分析,都可以在这个领域上来,我还是那句话,在大语言AI模型时代,只要你有想法,你就有结果!只要你愿意去学习,你就能卷动的过别人!
现在,你需要的只是一份清晰的转型计划和一群志同道合的伙伴。作为一名热心肠的互联网老兵,我决定把宝贵的AI知识分享给大家。 至于能学习到多少就看你的学习毅力和能力了 。

第一阶段(10天):初阶应用
该阶段让大家对大模型 AI有一个最前沿的认识,对大模型 AI 的理解超过 95% 的人,可以在相关讨论时发表高级、不跟风、又接地气的见解,别人只会和 AI 聊天,而你能调教 AI,并能用代码将大模型和业务衔接。
- 大模型 AI 能干什么?
- 大模型是怎样获得「智能」的?
- 用好 AI 的核心心法
- 大模型应用业务架构
- 大模型应用技术架构
- 代码示例:向 GPT-3.5 灌入新知识
- 提示工程的意义和核心思想
- Prompt 典型构成
- 指令调优方法论
- 思维链和思维树
- Prompt 攻击和防范
- …
第二阶段(30天):高阶应用
该阶段我们正式进入大模型 AI 进阶实战学习,学会构造私有知识库,扩展 AI 的能力。快速开发一个完整的基于 agent 对话机器人。掌握功能最强的大模型开发框架,抓住最新的技术进展,适合 Python 和 JavaScript 程序员。
- 为什么要做 RAG
- 搭建一个简单的 ChatPDF
- 检索的基础概念
- 什么是向量表示(Embeddings)
- 向量数据库与向量检索
- 基于向量检索的 RAG
- 搭建 RAG 系统的扩展知识
- 混合检索与 RAG-Fusion 简介
- 向量模型本地部署
- …
第三阶段(30天):模型训练
恭喜你,如果学到这里,你基本可以找到一份大模型 AI相关的工作,自己也能训练 GPT 了!通过微调,训练自己的垂直大模型,能独立训练开源多模态大模型,掌握更多技术方案。
到此为止,大概2个月的时间。你已经成为了一名“AI小子”。那么你还想往下探索吗?
- 为什么要做 RAG
- 什么是模型
- 什么是模型训练
- 求解器 & 损失函数简介
- 小实验2:手写一个简单的神经网络并训练它
- 什么是训练/预训练/微调/轻量化微调
- Transformer结构简介
- 轻量化微调
- 实验数据集的构建
- …
第四阶段(20天):商业闭环
对全球大模型从性能、吞吐量、成本等方面有一定的认知,可以在云端和本地等多种环境下部署大模型,找到适合自己的项目/创业方向,做一名被 AI 武装的产品经理。
- 硬件选型
- 带你了解全球大模型
- 使用国产大模型服务
- 搭建 OpenAI 代理
- 热身:基于阿里云 PAI 部署 Stable Diffusion
- 在本地计算机运行大模型
- 大模型的私有化部署
- 基于 vLLM 部署大模型
- 案例:如何优雅地在阿里云私有部署开源大模型
- 部署一套开源 LLM 项目
- 内容安全
- 互联网信息服务算法备案
- …
学习是一个过程,只要学习就会有挑战。天道酬勤,你越努力,就会成为越优秀的自己。
如果你能在15天内完成所有的任务,那你堪称天才。然而,如果你能完成 60-70% 的内容,你就已经开始具备成为一名大模型 AI 的正确特征了。
这份完整版的大模型 AI 学习资料已经上传优快云,朋友们如果需要可以微信扫描下方优快云官方认证二维码免费领取【保证100%免费】



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









