



📌 一句话总结:
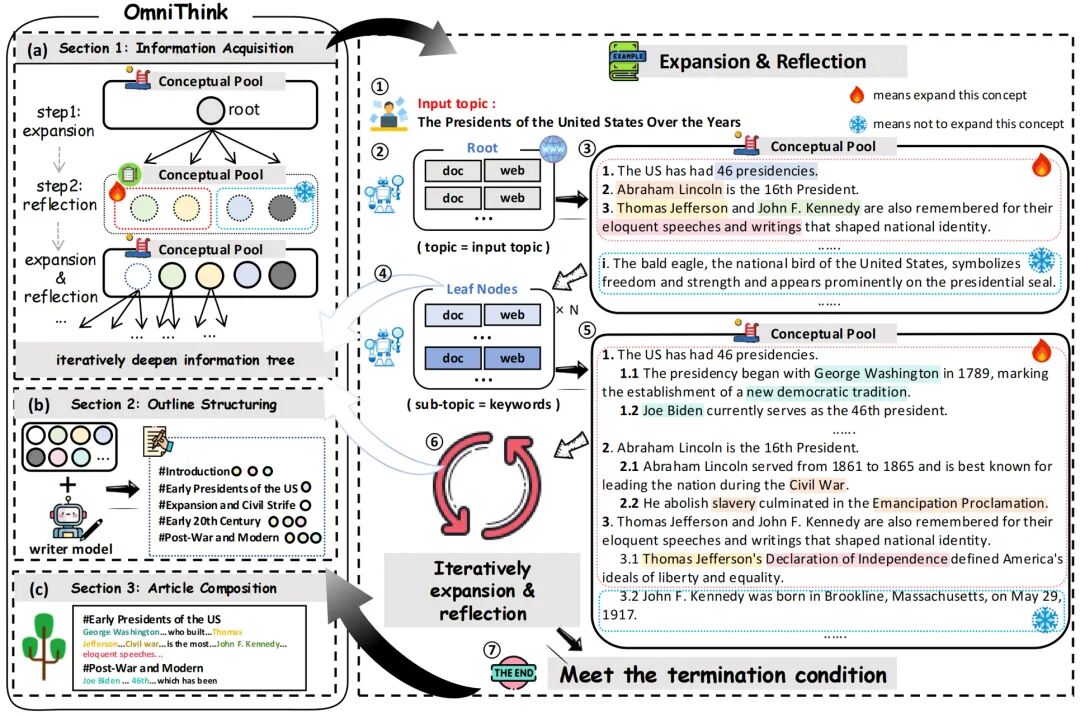
本工作提出 OmniThink,一种模仿人类“慢思考”过程的机器写作框架,通过信息树(Information Tree)与概念池(Conceptual Pool)的迭代扩展与反思机制,突破大模型在生成深度与知识边界上的瓶颈,显著提升长文生成的知识密度(Knowledge Density)与创新性。
🔍 背景问题:
当前基于 LLM 的自动写作系统主要依赖检索增强生成(RAG),但仍存在三个关键缺陷:
1️⃣ 检索信息深度不足,生成内容浅显且重复;
2️⃣ 缺乏“反思”机制,模型难以像人类一样逐步深化认知结构;
3️⃣ 检索策略固定,导致知识边界狭窄,难以生成真正新颖、有洞察力的文章。
OmniThink 受到人类认知科学中“反思性实践”(Reflective Practice)的启发,旨在让模型像人一样,通过不断地“回顾—反思—扩展”,形成更完整的知识认知闭环 。
💡 方法简介:
OmniThink 模拟人类写作的三阶段“思考—构建—生成”流程:
1️⃣ 信息获取(Information Acquisition):
通过搜索引擎检索并构建多层次的信息树,每个节点代表一个子主题;模型在不同节点上不断进行扩展(Expansion)与反思(Reflection),逐步拓展知识边界。
2️⃣ 概念反思(Conceptual Pool Reflection):
模型将不同节点提取的关键信息汇聚成概念池(Conceptual Pool),作为自身的“认知记忆”;反思更新使得模型能重组知识结构、提炼核心洞见。
3️⃣ 文章生成(Outline + Composition):
基于概念池生成结构化大纲,再以信息树中语义最相关的节点为支撑生成文章,并通过统一后处理去除冗余,提升文章的逻辑性与紧凑性。
整个过程形成了一个**“扩展—反思—再生成”的循环**,从而实现机器的“思维深化”与知识融合 。
📊 实验结果:
在 WildSeek 数据集上(涵盖24个开放领域),OmniThink 在多个指标上超越主流方法(RAG、STORM、Co-STORM):
🧩 知识密度(Knowledge Density):提升约 +2.8(22.31 vs. 19.53);
🔍 信息多样性:显著扩大信息边界范围(PCA 可视化显示覆盖最广);
✨ 新颖性(Novelty):提升最明显,反思机制带来更多创新观点;
🧠 文章层次性与逻辑一致性:均高于 STORM 与 Co-STORM。
尤其在 GPT-4o、DeepSeek-R1、Qwen-Plus 等多种模型上均保持稳定优势,显示其**模型无关性(model-agnostic)**和泛化能力 。
📈 核心发现:
反思(Reflection) 决定内容的创新性与思维广度;
扩展(Expansion) 决定知识密度与信息覆盖;
二者共同扩展了模型的 “信息边界” 与 “认知边界”——
使机器不再仅“写出已知的”,而能“思考未知的”。
如何高效转型Al大模型领域?
作为一名在一线互联网行业奋斗多年的老兵,我深知持续学习和进步的重要性,尤其是在复杂且深入的Al大模型开发领域。为什么精准学习如此关键?
- 系统的技术路线图:帮助你从入门到精通,明确所需掌握的知识点。
- 高效有序的学习路径:避免无效学习,节省时间,提升效率。
- 完整的知识体系:建立系统的知识框架,为职业发展打下坚实基础。
AI大模型从业者的核心竞争力
- 持续学习能力:Al技术日新月异,保持学习是关键。
- 跨领域思维:Al大模型需要结合业务场景,具备跨领域思考能力的从业者更受欢迎。
- 解决问题的能力:AI大模型的应用需要解决实际问题,你的编程经验将大放异彩。
以前总有人问我说:老师能不能帮我预测预测将来的风口在哪里?
现在没什么可说了,一定是Al;我们国家已经提出来:算力即国力!
未来已来,大模型在未来必然走向人类的生活中,无论你是前端,后端还是数据分析,都可以在这个领域上来,我还是那句话,在大语言AI模型时代,只要你有想法,你就有结果!只要你愿意去学习,你就能卷动的过别人!
现在,你需要的只是一份清晰的转型计划和一群志同道合的伙伴。作为一名热心肠的互联网老兵,我决定把宝贵的AI知识分享给大家。 至于能学习到多少就看你的学习毅力和能力了 。

第一阶段(10天):初阶应用
该阶段让大家对大模型 AI有一个最前沿的认识,对大模型 AI 的理解超过 95% 的人,可以在相关讨论时发表高级、不跟风、又接地气的见解,别人只会和 AI 聊天,而你能调教 AI,并能用代码将大模型和业务衔接。
- 大模型 AI 能干什么?
- 大模型是怎样获得「智能」的?
- 用好 AI 的核心心法
- 大模型应用业务架构
- 大模型应用技术架构
- 代码示例:向 GPT-3.5 灌入新知识
- 提示工程的意义和核心思想
- Prompt 典型构成
- 指令调优方法论
- 思维链和思维树
- Prompt 攻击和防范
- …
第二阶段(30天):高阶应用
该阶段我们正式进入大模型 AI 进阶实战学习,学会构造私有知识库,扩展 AI 的能力。快速开发一个完整的基于 agent 对话机器人。掌握功能最强的大模型开发框架,抓住最新的技术进展,适合 Python 和 JavaScript 程序员。
- 为什么要做 RAG
- 搭建一个简单的 ChatPDF
- 检索的基础概念
- 什么是向量表示(Embeddings)
- 向量数据库与向量检索
- 基于向量检索的 RAG
- 搭建 RAG 系统的扩展知识
- 混合检索与 RAG-Fusion 简介
- 向量模型本地部署
- …
第三阶段(30天):模型训练
恭喜你,如果学到这里,你基本可以找到一份大模型 AI相关的工作,自己也能训练 GPT 了!通过微调,训练自己的垂直大模型,能独立训练开源多模态大模型,掌握更多技术方案。
到此为止,大概2个月的时间。你已经成为了一名“AI小子”。那么你还想往下探索吗?
- 为什么要做 RAG
- 什么是模型
- 什么是模型训练
- 求解器 & 损失函数简介
- 小实验2:手写一个简单的神经网络并训练它
- 什么是训练/预训练/微调/轻量化微调
- Transformer结构简介
- 轻量化微调
- 实验数据集的构建
- …
第四阶段(20天):商业闭环
对全球大模型从性能、吞吐量、成本等方面有一定的认知,可以在云端和本地等多种环境下部署大模型,找到适合自己的项目/创业方向,做一名被 AI 武装的产品经理。
- 硬件选型
- 带你了解全球大模型
- 使用国产大模型服务
- 搭建 OpenAI 代理
- 热身:基于阿里云 PAI 部署 Stable Diffusion
- 在本地计算机运行大模型
- 大模型的私有化部署
- 基于 vLLM 部署大模型
- 案例:如何优雅地在阿里云私有部署开源大模型
- 部署一套开源 LLM 项目
- 内容安全
- 互联网信息服务算法备案
- …
学习是一个过程,只要学习就会有挑战。天道酬勤,你越努力,就会成为越优秀的自己。
如果你能在15天内完成所有的任务,那你堪称天才。然而,如果你能完成 60-70% 的内容,你就已经开始具备成为一名大模型 AI 的正确特征了。
这份完整版的大模型 AI 学习资料已经上传优快云,朋友们如果需要可以微信扫描下方优快云官方认证二维码免费领取【保证100%免费】



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









