



Hugging Face发布了《The Smol Training Playbook:The Secrets to Building World-Class LLMs》模型训练秘诀。

这份详尽的指南,由12位Hugging Face的顶尖工程师团队打造,记录了他们训练模型的全部心路历程,可以说是一份真正意义上的手把手实战指南,将Hugging Face团队约4年来构建最先进(SOTA)模型和数据集的所有经验,毫无保留地公之于众。
官方推荐2~4天读完。
这本手册,让这个过去被神秘光环笼罩的过程,变得透明、可及、高效。它适合所有对AI训练抱有热忱的人,无论你是初学者、研究员,还是身处一线的工程师。
1.最好别训练模型
手册开篇就提出了一个颠覆性的观点。
在投入数百万美元计算资源之前,必须回答一个最根本的问题:为什么需要训练一个新模型?

Hugging Face的经验表明,99%的情况下,你根本不应该从头开始训练。
为了避免无谓的资源消耗,他们设计了一个名为训练指南针的决策框架。这个框架像一位经验丰富的老船长,在你准备扬帆出海烧钱远航之前,冷静地帮你审视航行的必要性。
决策的逻辑链条异常清晰。

你有一个需求。
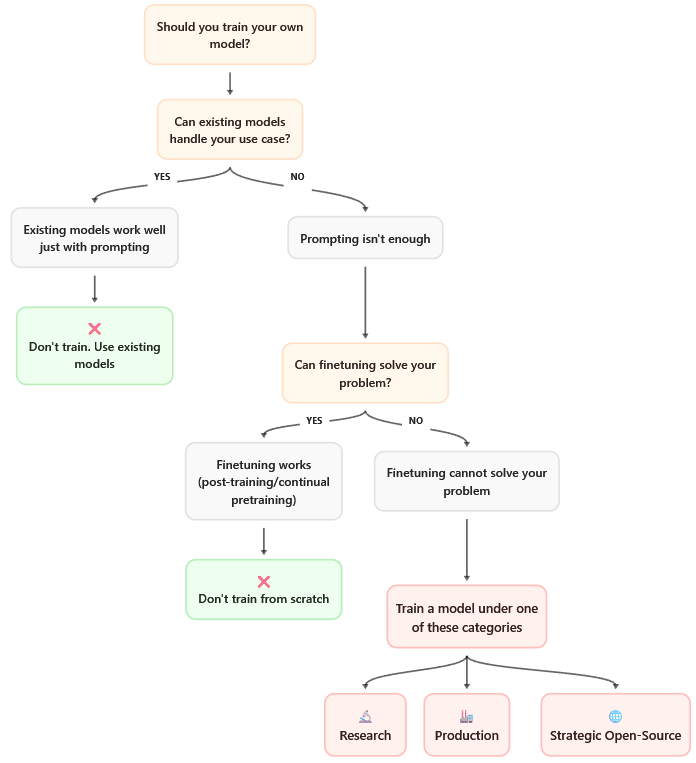
这个需求能通过提示工程(Prompt Engineering)解决吗?
如果不行,能通过检索增强生成(RAG)解决吗?
如果还不行,能通过微调(Fine-tuning)一个现有模型解决吗?
如果微调也不够,审视一下,现有的开源模型真的无法满足你的要求吗?
走完这一系列拷问,你才能触及那仅存的1%的正当训练理由。
Hugging Face将其归纳为三类。
一是前沿研究(Frontier Research)。
比如你正在探索一种全新的网络架构,试图替代Transformer,或者发明了一种新的注意力机制。这种探索未知边界的行为,值得开启一次全新的训练。
二是特定的生产需求(Production Specificity)。
当你的应用场景极端特殊,现有模型无法胜任时。例如,为一种罕见方言构建模型,或者在对延迟要求严苛到毫秒级的边缘设备上部署,再或者为医疗、法律等高度专业化的领域打造专用模型。
三是战略性开源(Strategic Open-Source)。
当你发现整个开源生态系统中存在一个明显的空白,需要有人去填补。Hugging Face自家的StarCoder模型就是如此,当时市面上缺乏一个足够强大的代码生成开源模型。SmolLM系列同样出于此目的,旨在探索小尺寸模型配合海量高质量数据的性能极限,为社区提供一个能在特定规模上挑战闭源模型的选项。
倘若你的理由不属于这三者中的任何一种,指南针会明确指向停止的方向。如果属于,那么恭喜你,准备开启一段昂贵但目标明确的旅程。
确定要训练后,下一个问题是,训练一个什么样的模型?
这并非一个越大越好的简单游戏,而是在参数规模、数据总量、计算预算和预期性能这四个变量之间,寻找一个微妙的平衡点。
规模定律(Scaling Laws)是重要的参考,但绝非不可违背的圣经。
SmolLM3团队的实践发现,当数据质量达到某个阈值后,模型的性能可以突破传统规模定律预测的上限。换言之,用更优质的数据喂养,一个较小的模型也能爆发出惊人的能量。
对SmolLM3而言,这个平衡点被定格在30亿参数。这个规模不大不小,恰到好处。它足够强大,足以展现出一些复杂能力;又足够小巧,可以在单张消费级显卡上流畅运行推理,极大地降低了部署门槛。
上下文长度则采用渐进式策略,从4K起步,逐步扩展至16K以上,这需要在位置编码方式与训练成本之间做出权衡。多语言能力的设计从一开始就融入数据混合策略,而不是等到训练后期再通过微调打补丁。
最后是如何训练。
这部分构成了手册的主体,但在决策阶段就需要确立核心哲学:先用极小的成本进行消融实验,再进行中等规模的验证,最后才投入全规模训练。每个阶段都必须有可靠、可量化的评估指标作为导航,同时对存储、网络、节点故障率等基础设施成本有清醒的认识。
2.魔鬼藏在架构与参数的细节里
一旦进入模型设计的深水区,每一个微小的组件选择都可能对最终结果产生深远影响。Hugging Face的工程师们像钟表匠一样,对模型的每一个零件进行了数十次甚至上百次的拆解、测试与重组。
这个过程的核心原则是小规模上验证一切。
直觉是廉价的,而GPU时间是昂贵的。
SmolLM3团队运行了数百个消融实验,每一个实验都在为一个关键决策去风险。这些实验遵循黄金法则:每次只改变一个变量,用10亿到100亿(token)的小规模数据快速迭代,并确保评估指标足够敏感,能够捕捉到不同配置间的细微差异。
以注意力机制为例,这是Transformer模型的心脏。团队系统性地评估了四种方案。
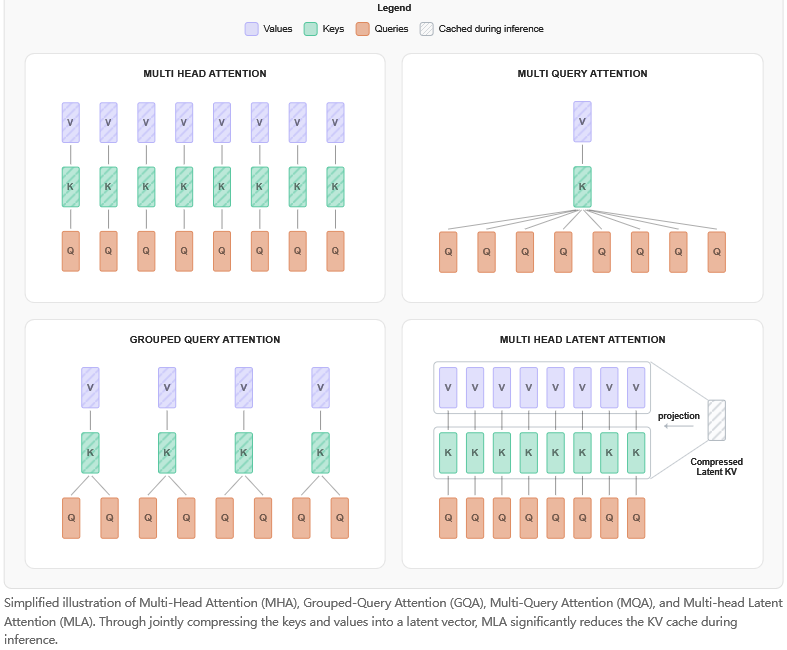
标准多头注意力(MHA)效果最好,但它的键值缓存(KV Cache)在推理时会占用大量内存,对于追求极致性能且不计较部署成本的场景是首选。
多查询注意力(MQA)则走向另一个极端,多个查询头共享一个键值头,内存占用最小,推理速度最快,但会带来2%到3%的质量损失,更适合资源受限的边缘设备。
分组查询注意力(GQA)是前两者之间的完美妥协。它将查询头分组,每组共享一套键值头,内存占用减半,质量损失却不到1%。在10亿到30亿参数规模的模型上,GQA是数据驱动下得出的最佳平衡点。SmolLM3最终选择了它。
还有一种新兴的潜在多头注意力(MLA),它通过低秩投影压缩键值,在处理长上下文时效率极高。团队在小规模测试后发现,在30亿参数的规模下,MLA带来的收益尚不明显,但它被作为未来版本的潜在升级选项保留了下来。
选择的背后并非一帆风顺。GQA的实现有一个巨大的陷阱。
在进行张量并行(Tensor Parallelism)时,如果权重划分不当,可能导致同一个张量并行组内的不同GPU分配到错误的键值头,使得GQA在功能上退化为MQA。SmolLM3团队就曾因此遭遇过一次训练到1万亿(token)后被迫重启的重大事故。
位置编码是模型理解序列顺序、处理长上下文的基石。
旋转位置编码(RoPE)是当前的主流选择。它的关键在于基值(base)的选择。基值越大,模型向更长上下文外推的能力就越强,但训练的稳定性也可能随之下降。SmolLM3采用10万作为基值,在4K长度上训练后,模型可以很好地外推到16K的上下文。
线性偏置注意力(ALiBi)是另一个选项,它在长文本上的泛化能力很好,实现也更简单,但在短文本上的表现略逊于RoPE。
令人惊讶的是,无位置编码(NoPE)在某些特定设置下竟然也行得通。但SmolLM3的消融实验表明,在30亿参数规模上,放弃位置编码会导致多任务语言理解(MMLU)评估分数下降约2%,这个代价是无法接受的。
一个关键的创新是文档内掩码(IntraDoc Masking)。传统的因果掩码在不同文档的边界处会阻断注意力,使得模型无法在打包的序列中跨文档学习。文档内掩码则允许模型在保持因果性的前提下,在文档之间建立联系,显著提升了模型对长篇文档的理解能力。
嵌入层与归一化层的设计同样充满了细节。
输入和输出嵌入层共享权重,这个看似简单的技巧可以减少15%到20%的参数量。在30亿参数规模上,SmolLM3的实验证明这种做法对性能没有任何损失,因此成为必选项。
归一化层的位置,前置归一化(Pre-norm)在超过20次的消融实验中,因其优越的稳定性和收敛速度而胜出,尽管理论上它的表达能力略弱于后置归一化(Post-norm)。
归一化的类型,均方根层归一化(RMSNorm)相比层归一化(LayerNorm)计算更快、内存占用更少,且效果相当,因此被全程采用。
查询键归一化(QK-Norm)是在查询和键进行点积后增加一个归一化步骤。这个操作至关重要,它能有效防止注意力分数在长上下文或半精度(FP16)训练时发生爆炸,是稳定训练的守护神。
优化器和超参数的选择,看似枯燥,却往往是决定成败的致命环节。
团队测试了多种优化器,包括Adam、Lion、Sophia等。
结论清晰而明确:AdamW至今仍是大规模语言模型训练的黄金标准。其配置细节也经过了微调:β1为0.9,β2为0.95(而非更常见的0.999,较低的β2更适合长序列训练),权重衰减为0.1。
学习率调度策略是另一个深奥的领域。
最流行的余弦(Cosine)调度策略并不适合超长序列的训练,因为它通常在训练总步数的30%后就开始衰减,过早地降低了学习率。SmolLM3的测试发现,在训练了8万亿(token)后,使用余弦调度的模型性能便陷入停滞。
手册中着重介绍了一种名为WSD(Warmup-Stable-Decay,预热-稳定-衰减)的调度器,这是模型能够成功训练11万亿(token)的关键。
它先用一小部分步数预热到峰值学习率,然后在长达70%的训练时间内将学习率保持在峰值(稳定阶段),确保模型有充分的时间学习,最后再进行线性衰减。
SmolLM3的WSD参数设置为:前1000亿(token)从0预热到3e-4的学习率;在1000亿到10万亿(token)之间,学习率稳定在3e-4;最后1万亿(token)线性衰减至3e-5。
一个创新性的技巧是批量大小预热(Batch Size Warmup)。训练初期使用较小的批量(例如100万token),然后逐步增大到硬件能承受的最大值(400万token)。这种做法能有效稳定训练早期的损失函数,避免发散。
3.数据决定了模型的上限
手册用最醒目的方式强调了一个原则:数据质量是提升模型性能最大的杠杆,没有之一。
模型架构的创新带来的性能提升可能不到5%,而数据质量的改善则能带来超过20%的飞跃。
Hugging Face的数据哲学是一条严谨的工业流水线。
原始文本首先经过严格的过滤,然后进行细致的去重,接着由模型进行质量评分,最后按照精心设计的比例进行混合。每一个环节都有可量化的指标进行监控。
以他们开源的FineWeb数据集为例,其过滤流程包括:
使用FastText进行语言检测,只保留置信度超过90%的样本。
使用一个小型语言模型对文本质量进行打分,淘汰低分样本。
通过MinHashLSH算法在文档级别进行去重,防止模型背诵重复内容,也避免了评估集数据的泄露。
利用Perspective API等工具过滤掉有毒或不安全的内容。
代码数据的处理则更为特殊。只保留在GitHub上星标数超过10的仓库,通过语法解析器检查代码的有效性,并将去重做到函数级别,以防止许可证污染。
数学数据则通过从学术论文网站arXiv提取LaTeX源码并渲染成文本,再结合使用GPT-4等大模型合成新的数学问答对来进行增强。
数据混合的配比,是真正的炼丹术。
SmolLM3的目标是成为一个兼具多语言、推理和代码能力的全能模型。团队的初始混合配比是50%的网页文本,30%的代码,以及20%的多语言数据。
然而,消融实验的结果令人意外。
将代码比例从30%提升到40%,代码评估基准HumanEval的分数竟提升了8%。
将多语言数据从20%提升到30%,通用知识评估MMLU的分数不仅没有下降,反而因跨语言知识的迁移而有所上升。
网页文本的质量远比数量重要,经过更严格的过滤后,即便比例从50%降至35%,模型性能也毫无损失。
最终,SmolLM3的数据配方演变为:35%高质量英语网页文本,15%覆盖20种语言的多语言文本,40%的代码(其中Python占一半),以及10%专门用于数学和推理的数据。
课程学习(Curriculum Learning)的有效性也得到了验证。训练的前1万亿(token),模型只学习相对简单的内容,比如短文本和高置信度的干净数据。随后,长文档、复杂代码等高难度数据才被逐步引入。这种由易到难的学习路径,不仅稳定了训练初期的收敛过程,还为最终性能带来了2%到3%的额外提升。
分词策略同样关键。SmolLM3的词表大小从常见的32K扩展到了64K,专门增补了大量代码关键字和多语言的子词。一个重要的警告是:训练中途绝对不要修改词表,这会破坏嵌入空间的连续性,导致灾难性的后果。
4.当理论撞上384块GPU的现实
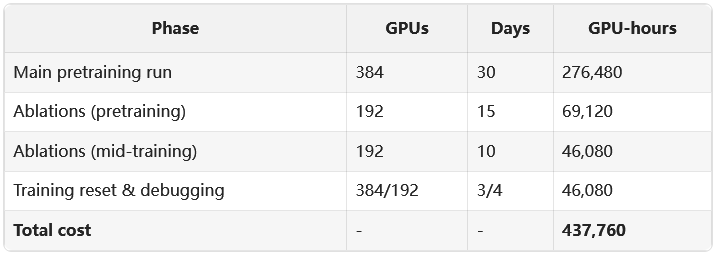
理论设计得再完美,当它运行在由384块H100 GPU组成的庞大集群上时,现实的复杂性便会显露无疑。
SmolLM3长达3周、消耗11万亿(token)的训练过程,就是一场与意外搏斗的马拉松。
存储系统曾因并行写入请求超过IOPS上限而崩溃,导致检查点(checkpoint)保存失败。
网络在夜间维护时段发生拥塞,导致节点间的AllReduce通信超时。
损失函数曲线上会随机出现无法解释的尖峰。
平均每天都有一到两块H100 GPU发生故障,故障率约为0.5%。
其中最惊心动魄的,是那次发生在训练进行到1万亿(token)后的重启事件。
当时,团队发现模型的各项评估指标,如MMLU和HumanEval,都显著低于小规模实验的预期。他们首先怀疑是数据混合出了问题,但反复检查后排除了这个可能。
排查过程如同一部侦探小说。数据加载器正常,梯度同步正常,损失计算正常。最后,当他们检查到系统的随机性时,发现了那个隐藏至深的Bug:在同一个张量并行组内的所有GPU,竟然共享了同一个随机种子。
根本原因在于,初始化GQA的键值头时,代码错误地使用了全局种子而非与每个GPU绑定的本地种子。这导致在一个由8块GPU组成的张量并行组内,所有键值头的初始化状态完全相同。模型的注意力头多样性被人为地削减了,学习能力因此受到严重抑制。
虽然Bug被修复了,但已经消耗掉的1万亿(token)的训练成果无法挽回。
团队面临一个艰难的抉择:是基于当前有缺陷的模型继续训练,还是壮士断腕,从头开始?他们选择了后者。这个决定意味着大约15万美元的计算成本打了水漂,但它换来的是最终模型能够达到SOTA级别的性能。
这次事件的最大教训是,必须对每一个组件进行系统性的单元测试。正是因为其他部分都经过了严格的消融验证,团队才能在众多可能性中迅速定位到问题根源。
吞吐量优化是另一场战斗。理论上,384块H100能提供380 PFLOPS的算力,但实际利用率峰值只有45%左右。通过性能剖析,团队发现数据加载、通信开销、计算内核效率和中央处理器(CPU)瓶颈是四大性能杀手。
他们通过使用Ray Data并行化数据加载、调整AllReduce的通信桶大小、升级到最新版的CUDA和FlashAttention内核、用Numba编译Python预处理代码等一系列手段,将实际吞-吐量提升到了一个可接受的水平。序列打包(Sequence Packing)和动态批大小等技巧也被用来减少计算资源的浪费。
损失尖峰是训练中常见的杂音,但SmolLM3遇到的尖峰频率异常之高。通过细致的排查,团队发现这并非单一原因所致。
一部分尖峰是由数据引起的,代码数据的平均长度远超文本,其梯度也更大,容易导致梯度爆炸。解决方案是为代码数据设置一个更低的梯度裁剪阈值。
另一部分则源于优化器,AdamW中β2参数设为0.999导致二阶矩更新过慢,对梯度尖峰不够敏感。将其调整为0.95后,尖峰的幅度显著降低。
甚至硬件也可能是元凶。监控系统发现,某节点的HBM显存温度一度超过95摄氏度,导致GPU自动降频。调整数据中心的空调流向后问题解决。
5.从一块璞玉到一件称手工具
预训练完成的基础模型,本质上只是一个高级的自动补全工具。要让它变成能与人对话、遵循指令的智能助手,还需要经历细致的后训练过程。
监督微调(SFT)是第一步。其核心在于构建高质量的指令数据集。团队采用了拒绝采样的方法,让模型对同一个提示生成多个回答,然后由人工挑选出最佳答案。数据混合同样关键,最终配比为50%的通用指令,30%的代码指令和20%的对话数据。
SFT阶段的超参数也充满了惊喜。最佳学习率是预训练的十分之一(1e-5),并且训练两个周期(epoch)效果最好,更多周期反而会导致过拟合。有趣的是,流行的低秩适配(LoRA)微调方法在SFT阶段效果不佳,全参数微调的表现要好得多。
偏好优化,如基于人类反馈的强化学习(RLHF),并非所有模型的必需品。只有当模型需要抑制有害内容、对齐人类审美或强化特定格式遵循时,它才显得尤为重要。
Hugging Face在SmolLM3上测试了一种更稳定的偏好优化算法APO(自适应偏好优化)。它不需要训练额外的价值网络,简化了架构,在有益且无害的评估中,为模型带来了5%的提升。
对于数学推理能力,团队开发了一种名为GRPO(分组相对策略优化)的创新方法。
它让模型对每个问题生成多个候选答案,然后用自动化的规则(如代码是否可运行、数学答案是否正确)来筛选和排序这些答案,并据此更新模型策略。这个方法的效果是惊人的,它将模型在GSM8k数学基准上的得分从62%一举提升到了84%。关键在于,这个过程完全自动化,无需昂贵的人工标注。
最终,SmolLM3被打造成了一个双模式推理模型。它既可以直接回答问题的快速模式,也具备先生成思考链条再给出答案的思考模式。这种设计是通过在SFT数据中混入思维链(Chain-of-Thought)样本,并用特殊标记来控制模式切换实现的。
这一切的背后,是庞大而复杂的基础设施支撑。
在GPU选型上,Hugging Face的经验是,对于小规模的消融实验(小于1000亿token),使用4090消费级显卡集群的性价比远超昂贵的H100。他们用这种方式完成了绝大多数的早期实验,节省了约80%的成本。
存储系统是另一个常被忽略的瓶颈。
一个完整的模型检查点大小可达300GB,频繁的保存会产生巨大的I/O压力。解决方案包括使用NVMe固态硬盘阵列作为本地缓存、对检查点进行分片保存,以及采用Apache Arrow格式加速数据加载。
网络通信是多节点训练的黑暗艺术。
PCIe与NVLink拓扑不匹配、NCCL缓冲区大小设置不当、TCP与RDMA协议选择错误等问题,都可能严重拖慢训练速度。精细的配置和监控是保障通信效率的关键。
最后是故障恢复。
在一个拥有数百块GPU的集群中,节点故障是必然事件。一个健壮的训练系统必须具备自动化故障恢复的能力,包括心跳检测、故障节点隔离、动态重配置集群以及从最近的检查点快速回滚。PyTorch的弹性训练框架为此提供了强大的支持。
《Smol Training Playbook》最终沉淀出了两条结晶。
第一是团队对迭代速度的痴迷。
顶级团队的标志不是单次实验的规模有多大,而是单位时间内能完成多少次实验。并行化实验、建立快速失败机制、将一切流程自动化,是提升迭代速度的核心。Hugging Face的内部指标是,每个研究员每周要进行15到20个消融实验,从一个想法诞生到看到初步结果,平均只需要18小时。其中90%的实验会失败,但正是这些失败的实验,为最终的成功指明了方向。
第二是团队对高质量数据的偏执。
这句话被反复强调:架构带来的提升是小步快跑,而数据带来的提升是跨越式发展。对数据多样性、准确性和信息密度的追求,应该近乎于一种信仰。
这本手册的终极价值,不在于提供了一份可以按图索骥的菜谱,而是揭示了SOTA模型诞生的本质:它是一场工程、科学与艺术的完美结合。
它不需要神来之笔,需要的是系统性地消除风险,是永不停歇的快速迭代,是对数据质量的极致尊重,以及在凌晨两点调试数据加载器时那份坚韧不拔。
训练世界级模型没有秘密,只有千次实验后的直觉,万次失败后的洞察,和永不妥协的质量追求。
如何高效转型Al大模型领域?
作为一名在一线互联网行业奋斗多年的老兵,我深知持续学习和进步的重要性,尤其是在复杂且深入的Al大模型开发领域。为什么精准学习如此关键?
- 系统的技术路线图:帮助你从入门到精通,明确所需掌握的知识点。
- 高效有序的学习路径:避免无效学习,节省时间,提升效率。
- 完整的知识体系:建立系统的知识框架,为职业发展打下坚实基础。
AI大模型从业者的核心竞争力
- 持续学习能力:Al技术日新月异,保持学习是关键。
- 跨领域思维:Al大模型需要结合业务场景,具备跨领域思考能力的从业者更受欢迎。
- 解决问题的能力:AI大模型的应用需要解决实际问题,你的编程经验将大放异彩。
以前总有人问我说:老师能不能帮我预测预测将来的风口在哪里?
现在没什么可说了,一定是Al;我们国家已经提出来:算力即国力!
未来已来,大模型在未来必然走向人类的生活中,无论你是前端,后端还是数据分析,都可以在这个领域上来,我还是那句话,在大语言AI模型时代,只要你有想法,你就有结果!只要你愿意去学习,你就能卷动的过别人!
现在,你需要的只是一份清晰的转型计划和一群志同道合的伙伴。作为一名热心肠的互联网老兵,我决定把宝贵的AI知识分享给大家。 至于能学习到多少就看你的学习毅力和能力了 。

第一阶段(10天):初阶应用
该阶段让大家对大模型 AI有一个最前沿的认识,对大模型 AI 的理解超过 95% 的人,可以在相关讨论时发表高级、不跟风、又接地气的见解,别人只会和 AI 聊天,而你能调教 AI,并能用代码将大模型和业务衔接。
- 大模型 AI 能干什么?
- 大模型是怎样获得「智能」的?
- 用好 AI 的核心心法
- 大模型应用业务架构
- 大模型应用技术架构
- 代码示例:向 GPT-3.5 灌入新知识
- 提示工程的意义和核心思想
- Prompt 典型构成
- 指令调优方法论
- 思维链和思维树
- Prompt 攻击和防范
- …
第二阶段(30天):高阶应用
该阶段我们正式进入大模型 AI 进阶实战学习,学会构造私有知识库,扩展 AI 的能力。快速开发一个完整的基于 agent 对话机器人。掌握功能最强的大模型开发框架,抓住最新的技术进展,适合 Python 和 JavaScript 程序员。
- 为什么要做 RAG
- 搭建一个简单的 ChatPDF
- 检索的基础概念
- 什么是向量表示(Embeddings)
- 向量数据库与向量检索
- 基于向量检索的 RAG
- 搭建 RAG 系统的扩展知识
- 混合检索与 RAG-Fusion 简介
- 向量模型本地部署
- …
第三阶段(30天):模型训练
恭喜你,如果学到这里,你基本可以找到一份大模型 AI相关的工作,自己也能训练 GPT 了!通过微调,训练自己的垂直大模型,能独立训练开源多模态大模型,掌握更多技术方案。
到此为止,大概2个月的时间。你已经成为了一名“AI小子”。那么你还想往下探索吗?
- 为什么要做 RAG
- 什么是模型
- 什么是模型训练
- 求解器 & 损失函数简介
- 小实验2:手写一个简单的神经网络并训练它
- 什么是训练/预训练/微调/轻量化微调
- Transformer结构简介
- 轻量化微调
- 实验数据集的构建
- …
第四阶段(20天):商业闭环
对全球大模型从性能、吞吐量、成本等方面有一定的认知,可以在云端和本地等多种环境下部署大模型,找到适合自己的项目/创业方向,做一名被 AI 武装的产品经理。
- 硬件选型
- 带你了解全球大模型
- 使用国产大模型服务
- 搭建 OpenAI 代理
- 热身:基于阿里云 PAI 部署 Stable Diffusion
- 在本地计算机运行大模型
- 大模型的私有化部署
- 基于 vLLM 部署大模型
- 案例:如何优雅地在阿里云私有部署开源大模型
- 部署一套开源 LLM 项目
- 内容安全
- 互联网信息服务算法备案
- …
学习是一个过程,只要学习就会有挑战。天道酬勤,你越努力,就会成为越优秀的自己。
如果你能在15天内完成所有的任务,那你堪称天才。然而,如果你能完成 60-70% 的内容,你就已经开始具备成为一名大模型 AI 的正确特征了。
这份完整版的大模型 AI 学习资料已经上传优快云,朋友们如果需要可以微信扫描下方优快云官方认证二维码免费领取【保证100%免费】


















 656
656

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









