



近年来,大型语言模型(LLM)如 GPT-4 和 Claude 已在多种任务中展现出强大能力,但面对需要专业知识和多步推理的复杂任务时,单一模型仍显不足。为此,研究者将 LLM 嵌入Agent系统中,赋予其记忆、工具使用和反馈机制,形成“Agent”。更进一步,“自我进化Agent”应运而生——它们能通过迭代学习自主提升能力。然而,现有方法多局限于提示词改写或错误重试,缺乏系统性的能力积累与转化。

- 论文:Alita-G: Self-Evolving Generative Agent for Agent Generation
- 链接:https://arxiv.org/pdf/2510.23601
本文提出的 ALITA-G 框架,正是为了解决这一痛点。它通过一种新颖的自我进化机制,将通用Agent转化为领域专家。具体来说,ALITA-G 能自动生成、抽象并管理一种称为“模型上下文协议(MCP)”的工具,形成可复用的“MCP 盒子”。在推理时,Agent通过检索增强生成(RAG)技术动态选择并执行最相关的 MCP,显著提升任务准确率和计算效率。实验表明,ALITA-G 在多个权威基准测试中刷新了性能记录,同时降低了资源消耗,为实现“通用人工智能到领域专家”的转变提供了可行路径。
一、研究动机与问题定义
当前自我进化Agent存在两大局限:进化范围狭窄和进化机制浅薄。多数系统仅在单一任务或有限领域内优化,缺乏跨任务的能力迁移;进化方式也多停留在参数微调或错误修复,未实现端到端的架构适应。
ALITA-G 的目标是:给定一组领域任务,自动合成一个专用Agent,使其在该领域内的表现显著优于通用Agent。用数学语言描述:假设任务集合为 ,其中 是任务描述, 是期望输出。ALITA-G 的目标是构建一个专用Agent ,满足:
这里, 是目标任务分布, 是基线Agent。ALITA-G 通过系统化的工具生成与检索机制,实现从“通才”到“专才”的转变。
二、ALITA-G 方法详解
任务驱动的 MCP 生成
ALITA-G 的核心是 Model Context Protocol (MCP) ,可理解为一种标准化、可调用的工具模块。生成过程如下:
- 主Agent(Master Agent) 多次执行目标任务,每次生成一个推理轨迹 ,包含推理步骤、行动(如调用 MCP)和环境观察。
- Agent被提示将复杂子任务模块化为可复用的 MCP,每个 MCP 包括代码、功能描述和使用案例。
- 仅从成功执行的任务中收集 MCP,形成原始池 ,确保工具质量。
MCP 抽象与盒子构建
原始 MCP 往往与具体任务绑定,缺乏通用性。ALITA-G 使用 LLM 对它们进行抽象:
抽象过程包括:
- 参数泛化:将硬编码值改为可配置参数。
- 上下文去除:移除任务特定引用,保留核心功能。
- 接口标准化:遵循 FastMCP 协议,确保兼容性。
- 文档增强:添加详细说明和类型注释。
最终构建出 MCP 盒子,作为可复用的工具库。
RAG 增强的 MCP 选择机制
面对新任务时,ALITA-G 通过 RAG 动态选择最相关的 MCP:
- 将每个 MCP 的描述和使用案例拼接为上下文 。
- 使用嵌入模型 计算查询和 MCP 的语义向量,通过余弦相似度评分 。
- 支持两种选择策略:
- 阈值选择:选取相似度超过阈值 的 MCP。
- Top-k 选择:选取前 个最相似的 MCP。
这两种策略平衡了工具质量与计算开销,适应不同任务需求。
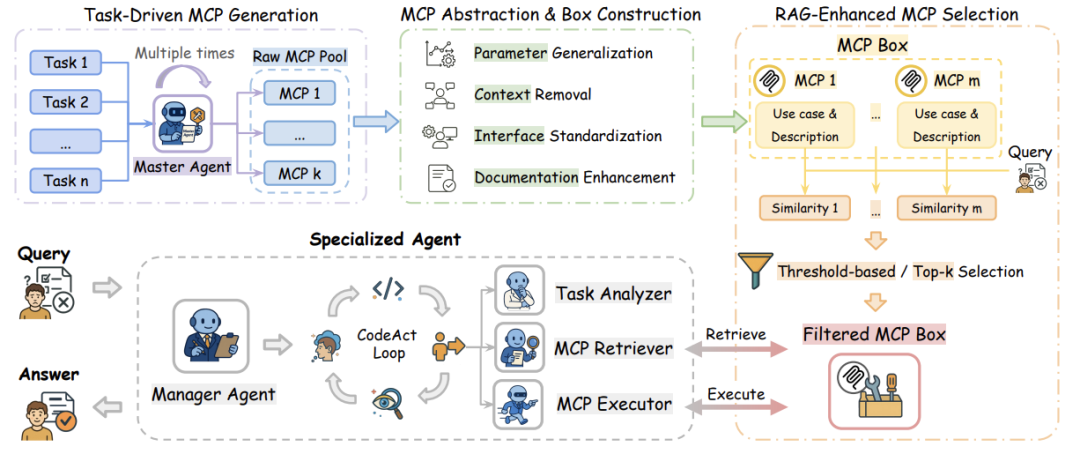
ALITA-G 的整体工作流程,从任务执行、MCP 抽象到推理阶段的工具检索与执行。
专用Agent架构
专用Agent 由三个组件构成:
- 任务分析器:解析输入任务并生成嵌入表示。
- MCP 检索器:执行 RAG 算法,筛选相关工具。
- MCP 执行器:动态调用选定 MCP,并管理执行流程。
Agent在推理时遵循结构化管道(如算法1所示),实现端到端的问题解决。
三、实验设置与结果分析
基准测试与基线方法
论文在三个挑战性基准上评估 ALITA-G:
- GAIA:通用 AI 助手测试,涵盖 466 个真实世界问题。
- PathVQA:医学视觉问答,需专业领域知识。
- HLE:人类终极考试,测试复杂推理与多模态理解。
基线方法包括:
- Octotools:工具增强Agent框架。
- ODR-smolagents:通用Agent实现。
- 原始Agent系统:未使用 MCP 盒子的主Agent。
性能比较:准确率与效率提升
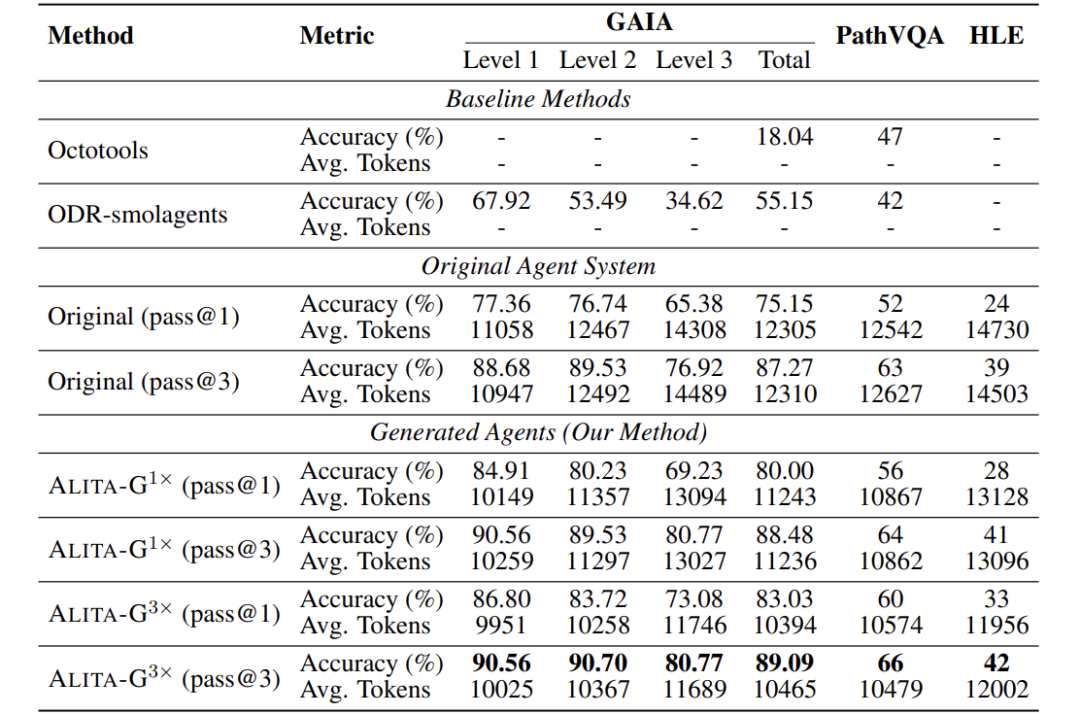
综合对比各方法在准确率和平均令牌消耗上的表现。
关键发现:
- ALITA-G(3×)在 GAIA 上达到 83.03% pass@1 和 89.09% pass@3,显著优于基线(如 ODR-smolagents 的 55.15%)。
- 计算效率提升:ALITA-G(3×)在 GAIA 上平均令牌数降至 10,394,比原始Agent(12,305)降低约 15.5%。
- MCP 盒子质量与性能正相关:三次生成的 MCP 盒子比单次生成带来明显提升(如 GAIA 从 80.00% 升至 83.03%)。
这些结果验证了 ALITA-G 在提升准确率的同时,显著降低计算成本。
四、深入分析:机制与组件验证
RAG 内容组件分析

比较使用不同文本内容(描述、使用案例、两者结合)进行 RAG 检索的效果
结果:结合描述和使用案例的检索效果最佳(平均准确率 83.03%),仅使用描述次之(81.82%),仅使用案例最差(77.57%)。说明 MCP 描述提供更通用的语义信息,而使用案例在结合时能补充上下文。
MCP 盒子可扩展性研究

随着生成迭代次数增加,MCP 盒子规模、聚类数量和性能的变化。
关键洞察:
- 性能在迭代 3 次后趋于饱和,平均准确率从 80.00%(k=1)升至 83.03%(k=3),之后增长缓慢。
- 相似性分析显示,随着 MCP 数量增加,冗余度上升(聚类数增长放缓),解释性能平台期的出现。
MCP 选择策略比较
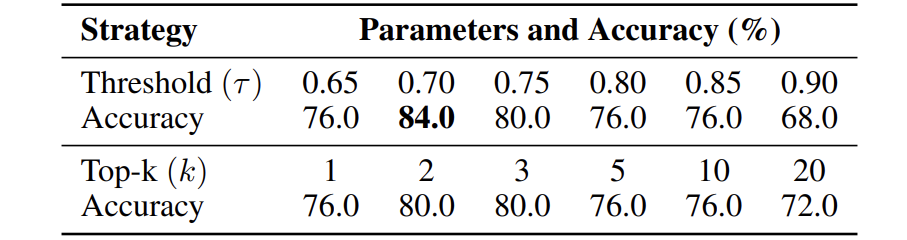
对比阈值选择和 Top-k 选择在不同参数下的表现
结果:阈值选择(τ=0.7)效果最优(准确率 84%),优于所有 Top-k 设置。说明动态调整工具数量比固定数量更适应任务多样性。
嵌入编码器的影响

不同嵌入模型对 RAG 检索效果的影响
结果:OpenAI 的 text-embedding-3-large 表现最佳(准确率 84%),凸显高质量编码器对工具检索的重要性。
MCP 行为与使用模式
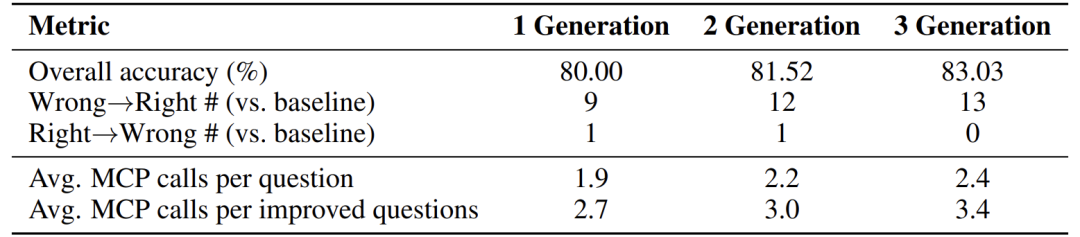
分析 MCP 调用次数与任务正确率的关系
发现:
- 改进的问题(从错误变正确)平均调用 MCP 次数更高(如 3.4 次 vs. 整体 2.4 次)。
- MCP 盒子集成后,错误转正确的数量显著增加(如 13 个),而正确转错误极少(0 个),证明方法稳健。
五、案例研究:从抽象到推理的实际应用
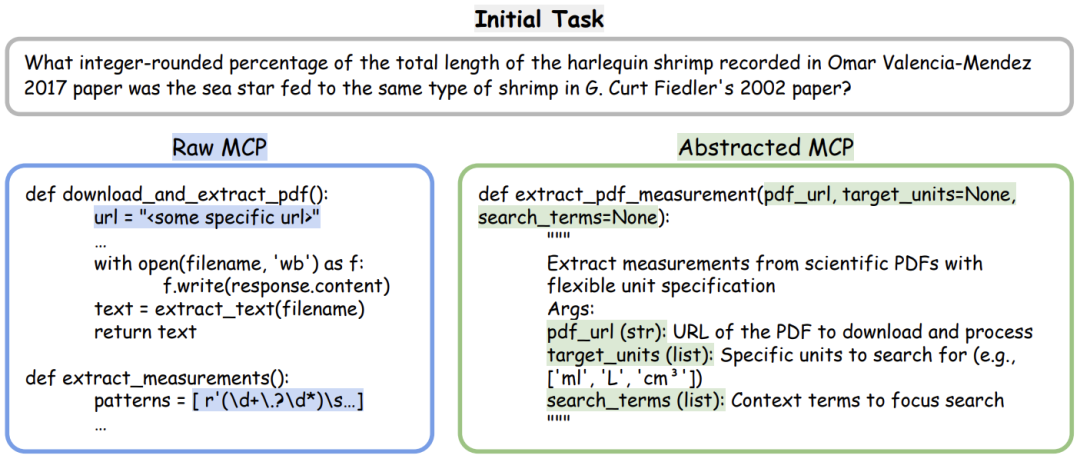
图2
图2展示了一个具体示例:在海洋生物学文献任务中,原始 MCP 被抽象为可复用的 extract_pdf_measurement 工具,参数化并标准化接口。

图3
图3对比了基线Agent与专用Agent在热力学问题上的表现:基线因无法提取精确数据而错误预测(20 mL),专用Agent通过检索并执行抽象后的 MCP,正确解答(55 mL)。
案例说明:
- 抽象是关键:将临时工具转化为通用组件,扩大应用范围。
- MCP 盒子提升性能:通过精准检索,实现“即插即用”的领域能力。
六、结论与未来展望
ALITA-G 通过 任务驱动的 MCP 生成、抽象与盒子构建 以及 RAG 增强的工具选择,实现了自我进化Agent从通用到领域的转变。其核心贡献包括:
- 提出并验证了一个端到端的Agent生成框架。
- 首次将 MCP 抽象与 MCP 级 RAG 结合,提升准确率与效率。
- 在多项基准测试中确立新的性能标杆。
研究价值:ALITA-G 为 AI Agent的自动化、专业化发展提供了可行路径,尤其适用于医疗、学术、工程等需要深度领域知识的场景。
未来展望:可扩展自进化维度(如多Agent协作、跨领域迁移),进一步降低人工干预,实现更强大的自主能力。
如何高效转型Al大模型领域?
作为一名在一线互联网行业奋斗多年的老兵,我深知持续学习和进步的重要性,尤其是在复杂且深入的Al大模型开发领域。为什么精准学习如此关键?
- 系统的技术路线图:帮助你从入门到精通,明确所需掌握的知识点。
- 高效有序的学习路径:避免无效学习,节省时间,提升效率。
- 完整的知识体系:建立系统的知识框架,为职业发展打下坚实基础。
AI大模型从业者的核心竞争力
- 持续学习能力:Al技术日新月异,保持学习是关键。
- 跨领域思维:Al大模型需要结合业务场景,具备跨领域思考能力的从业者更受欢迎。
- 解决问题的能力:AI大模型的应用需要解决实际问题,你的编程经验将大放异彩。
以前总有人问我说:老师能不能帮我预测预测将来的风口在哪里?
现在没什么可说了,一定是Al;我们国家已经提出来:算力即国力!
未来已来,大模型在未来必然走向人类的生活中,无论你是前端,后端还是数据分析,都可以在这个领域上来,我还是那句话,在大语言AI模型时代,只要你有想法,你就有结果!只要你愿意去学习,你就能卷动的过别人!
现在,你需要的只是一份清晰的转型计划和一群志同道合的伙伴。作为一名热心肠的互联网老兵,我决定把宝贵的AI知识分享给大家。 至于能学习到多少就看你的学习毅力和能力了 。

第一阶段(10天):初阶应用
该阶段让大家对大模型 AI有一个最前沿的认识,对大模型 AI 的理解超过 95% 的人,可以在相关讨论时发表高级、不跟风、又接地气的见解,别人只会和 AI 聊天,而你能调教 AI,并能用代码将大模型和业务衔接。
- 大模型 AI 能干什么?
- 大模型是怎样获得「智能」的?
- 用好 AI 的核心心法
- 大模型应用业务架构
- 大模型应用技术架构
- 代码示例:向 GPT-3.5 灌入新知识
- 提示工程的意义和核心思想
- Prompt 典型构成
- 指令调优方法论
- 思维链和思维树
- Prompt 攻击和防范
- …
第二阶段(30天):高阶应用
该阶段我们正式进入大模型 AI 进阶实战学习,学会构造私有知识库,扩展 AI 的能力。快速开发一个完整的基于 agent 对话机器人。掌握功能最强的大模型开发框架,抓住最新的技术进展,适合 Python 和 JavaScript 程序员。
- 为什么要做 RAG
- 搭建一个简单的 ChatPDF
- 检索的基础概念
- 什么是向量表示(Embeddings)
- 向量数据库与向量检索
- 基于向量检索的 RAG
- 搭建 RAG 系统的扩展知识
- 混合检索与 RAG-Fusion 简介
- 向量模型本地部署
- …
第三阶段(30天):模型训练
恭喜你,如果学到这里,你基本可以找到一份大模型 AI相关的工作,自己也能训练 GPT 了!通过微调,训练自己的垂直大模型,能独立训练开源多模态大模型,掌握更多技术方案。
到此为止,大概2个月的时间。你已经成为了一名“AI小子”。那么你还想往下探索吗?
- 为什么要做 RAG
- 什么是模型
- 什么是模型训练
- 求解器 & 损失函数简介
- 小实验2:手写一个简单的神经网络并训练它
- 什么是训练/预训练/微调/轻量化微调
- Transformer结构简介
- 轻量化微调
- 实验数据集的构建
- …
第四阶段(20天):商业闭环
对全球大模型从性能、吞吐量、成本等方面有一定的认知,可以在云端和本地等多种环境下部署大模型,找到适合自己的项目/创业方向,做一名被 AI 武装的产品经理。
- 硬件选型
- 带你了解全球大模型
- 使用国产大模型服务
- 搭建 OpenAI 代理
- 热身:基于阿里云 PAI 部署 Stable Diffusion
- 在本地计算机运行大模型
- 大模型的私有化部署
- 基于 vLLM 部署大模型
- 案例:如何优雅地在阿里云私有部署开源大模型
- 部署一套开源 LLM 项目
- 内容安全
- 互联网信息服务算法备案
- …
学习是一个过程,只要学习就会有挑战。天道酬勤,你越努力,就会成为越优秀的自己。
如果你能在15天内完成所有的任务,那你堪称天才。然而,如果你能完成 60-70% 的内容,你就已经开始具备成为一名大模型 AI 的正确特征了。
这份完整版的大模型 AI 学习资料已经上传优快云,朋友们如果需要可以微信扫描下方优快云官方认证二维码免费领取【保证100%免费】


















 1100
1100

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









