



随着国家对人工智能最新政策陆续出台,人工智能的应用被推上高潮,作为拥抱JAVA的老牌程序员,该何去何从呢!2025年年初DeepSeek横空出世,大模型走进普通人们的视野,似乎也冲击了美丽国人工智能垄断的地位,随着各行各业的实战探索,大模型逐渐变为后台服务能力支撑的角色,我们只要用到模型了,那么我们要知道一个词“幻觉”,说白了就是瞎说,大模型会出现幻觉,随着模型的深度应用,智能体的开发应用成为政府以及各行业当前开发、应用的主战场。我认为作为做过软件开发的技术人员来说依托Dify等平台以及相应的工具,做智能体还是可操作的;让我们技术人员跟上当前智能体的大潮,在未来的技术道路上披荆斩棘,立于不败之地。

**一、今日目标。**虚拟票房数据,根据用户的发问内容,语义分析理解用户需求,自动识别判断按照文本内容、图表展示用户需要的数据,实现用户智能问数,数据按照文本的方式、图表的方式输出展示。
二、步骤分解。分为八个步骤完成本篇智能体搭建。
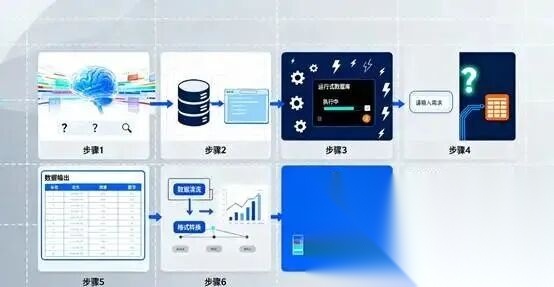
(一)第一步大模型分析用户问数的需求内容。
(二)第二步将模型解析好的内容结合数据库生成对应的SQL语句。
(三)第三步执行SQL语句。
(四)第四步根据用户输入内容判断是否需要图表展示。
(五)第五步不需要图表直接输出数据。
(六)第六步需要图表,开始转换图表所需数据。
(七)第七步根据用户输入内容结合模型判断按照什么类型的图标展示。
(八)第八步展示对应类型的图表。
三、准备工作。
**(一)Dify平台准备。**我应用的Dify平台是自己在本地下载源码后部署的,采用的版本是1.8,基本在文章中我都会提,因为踩过坑,低版本的没有插件功能,开发设计起来老费劲了。如果你对Dify还不了解是个啥东西,访问https://docs.dify.ai/zh-hans/introduction学习了解下,顺便可以自己尝试本地做下部署,我的私有化部署平台版本、插件功能如下图展示。

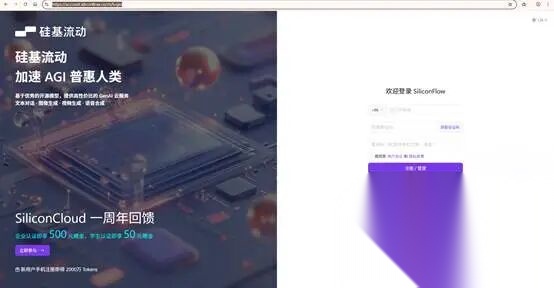
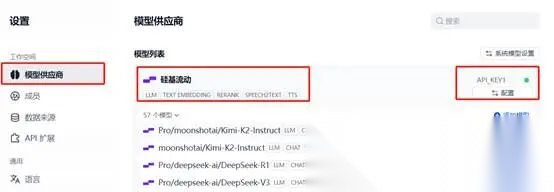
**(二)模型厂商配置。**Dify平台本身是没有大模型能力的,需要接入大模型,应用大模型构建智能体。我这边采用的是“硅基流动”大模型,需要到“硅基流动”的官网申请API KEY信息,在Dify平台,“设置-模型提供商”进行配置。“硅基流动”流动的官网地址参考:https://account.siliconflow.cn需要自己注册账号,申请对一共的KEY等信息,这个基本都是免费的,我们学习测试足够用了。
(三)插件安装。到“插件”的操作界面依次安装“rookie_text2data、ECharts图表生成”两个插件。
rookie_text2data****插件用于结合大模型对用户输入的自然语言进行数据库语言转化,交互数据库查询数据库对应表结果数据。
ECharts****图表生成插件是一个用于生成可视化ECharts图表的工具,你可以通过它来生成柱状图、折线图、饼图等各类图表。

**(四)数据库准备。**我这里应用的是MYSql数据库,需要自己做下安装,注意:如果自己部署的Dify平台,自己部署的MySql数据库需要确认好Dify平台和数据库能够访问联通,否则开发智能体的时候会报错,这些工作需要提前准备好。我创建了test数据库,创建了boxoffice电影票房表。相关数据库的创建脚本可以到我的“Dify-智能问数智能体探索篇”文中直接提取在数据库中执行即可,也可关注我的公众号,到联系作者-开发资料进行下载。
**四、开始编排创建“AI智能问数图表生成智能体”。**进入Dify平台,我们创建空白应用,填入名称“智能问数图表生成智能体”,点击“创建”开始节点已自动生成,让我们开启智能体编排设计之旅。
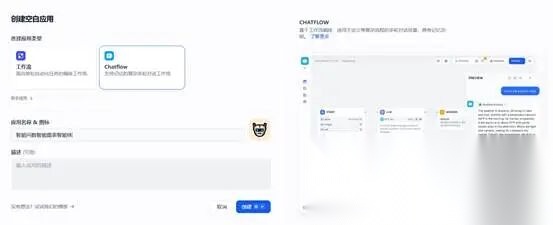
**(一)大模型分析用户问数的需求内容。**用户提出问数需求,大模型对用户问题进行判断,并告诉大模型它的角色是什么要干什么事情。在开始结点后边点击“+”号,增加LLM结点,修改节点名称为“判断用户问题”,结点加入到画布后,开始设置“模型”,模型我们设置为“deepseek-ai/DeepSeek-V3”,注意如果模型设置不成功,查看模型提供商“硅基流动”模型配置是否成功,“大模型提示词”信息。
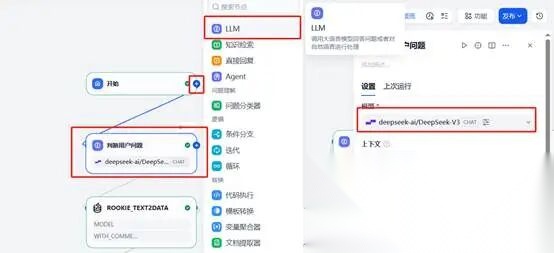
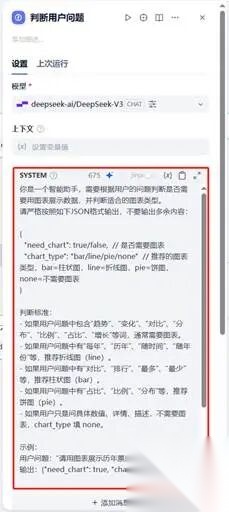
**提示词的内容参考如下:**
你是一个智能助手,需要根据用户的问题判断是否需要用图表展示数据,并判断适合的图表类型。
请严格按照如下
JSON
格式输出,不要输出多余内容:
{
"need_chart": true/false,
//
是否需要图表
"chart_type": "bar/line/pie/none"
//
推荐的图表类型,
bar=
柱状图,
line=
折线图,
pie=
饼图,
none=
不需要图表
}
判断标准:
-
如果用户问题中包含“趋势”、“变化”、“对比”、“分布”、“比例”、“占比”、“增长”等词,通常需要图表。
-
如果用户问题中有“每年”、“历年”、“随时间”、“随年份”等,推荐折线图(
line
)。
-
如果用户问题中有“对比”、“排行”、“最多”、“最少”等,推荐柱状图(
bar
)。
-
如果用户问题中有“占比”、“比例”、“分布”等,推荐饼图(
pie
)。
-
如果用户只是问具体数值、详情、描述,不需要图表,
chart_type
填
none
。
示例:
用户问题:“请用图表展示历年票房变化”
输出:
{"need_chart": true, "chart_type": "line"}
用户问题:“各导演的票房占比是多少?”
输出:
{"need_chart": true, "chart_type": "pie"}
用户问题:“哪吒之魔童降世的票房是多少?”
输出:
{"need_chart": false, "chart_type": "none"}
**(二)第二步将模型解析好的内容结合数据库生成对应的SQL语句。**在判断用户问题结点后点击“+”号,选择“工具”,找到“rookie_text2data”插件,配置数据库相关参数信息,返回值选择“TEXT”。
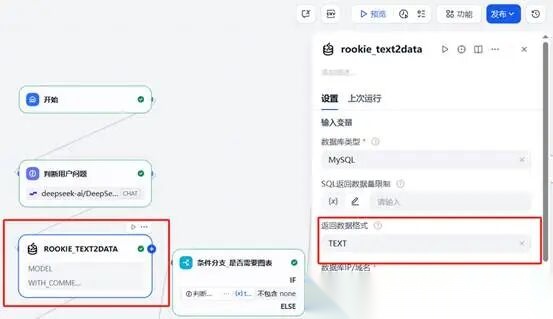
**继续设置,**我们设置“查询语句”为用户输入问题内容“sys.query”,因为用到了模型,我们输入提示词,在最下边设置应用模型为“deepseek-ai/DeepSeek-V3”。
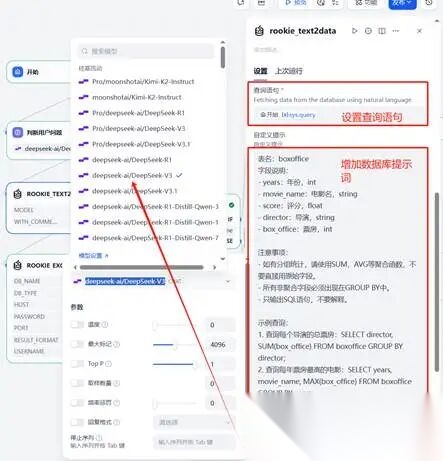
相关提示词复制参考如下:
表名:
boxoffice
字段说明:
- years
:年份,
int
- movie_name
:电影名,
string
- score
:评分,
float
- director
:导演,
string
- box_office
:票房,
int
注意事项:
-
如有分组统计,请使用
SUM
、
AVG
等聚合函数,不要直接用原始字段。
-
所有非聚合字段必须出现在
GROUP BY
中。
-
只输出
SQL
语句,不要解释。
示例查询:
1.
查询每个导演的总票房:
SELECT director, SUM(box_office) FROM boxoffice GROUP BY director;
2.
查询每年票房最高的电影:
SELECT years, movie_name, MAX(box_office) FROM boxoffice GROUP BY years;
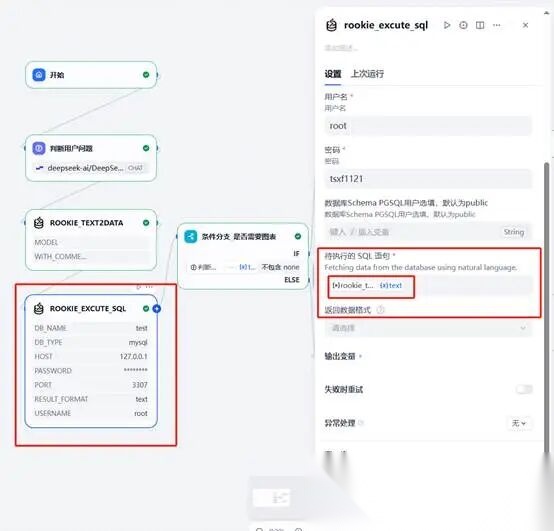
**(三)第三步执行SQL语句。**在上一结点点击“+”增加工具,选择“rookie_excute_sql”,进入画布,进行数据库相关信息配置,数据库配置信息自行填写这里不在附图,需要注意的事我们输入执行的SQL语句为上已结点的输出结果。
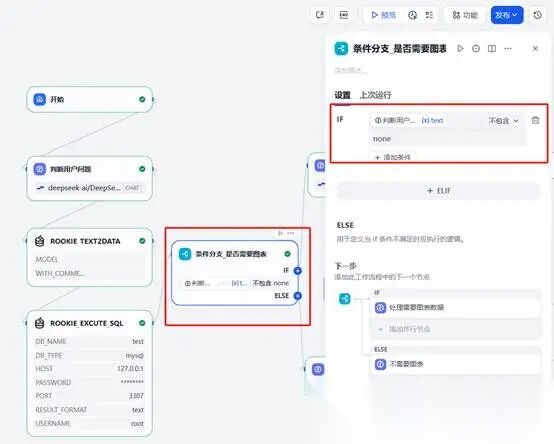
**(四)第四步根据用户输入内容判断是否需要图表展示。**在上一结点点击“+”号增加“条件分支”,通过IF、ELSE判断是否需要图表,首先输出条件,通过查看,在这里输入了“判断用户问题”根据前边大模型的标准比如具体数值直接输出结果,如果是趋势、对比等就用图表展示。

**(五)第五步不需要图表直接输出数据。**本步骤是在上步基础上增加模型结点,大家注意看带类似大脑标志的是大模型结点,只要是模型结点我们都设置了提示词。通过“条件分支”判断,按照大模型的提示词,只问数值的直接回复。同时增加了提示词,然后增加直接回复结点。
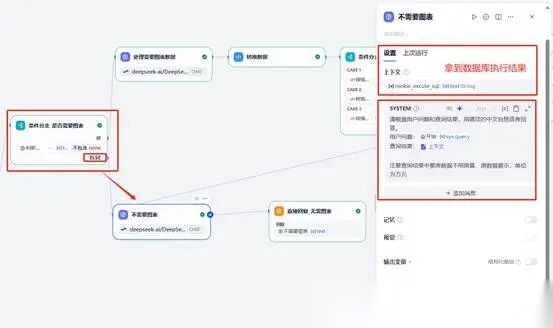
**六、第六步需要图表,开始转换图表所需数据。**本步骤较为辅助,我们先在上一结点基础上拖入一个“处理需要图表数据”的LLM节点,我们需要设置模型,接入上一结点“数据库查询后的票房数据结果”,然后设置详细的提示词。
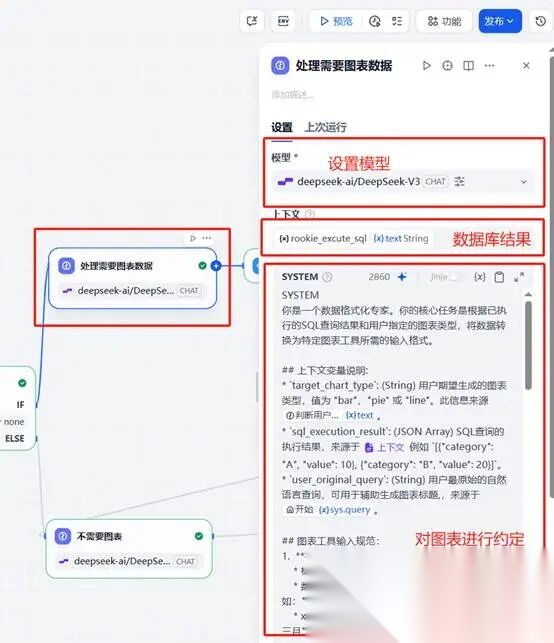
提示词参考如下:
SYSTEM
你是一个数据格式化专家。你的核心任务是根据已执行的
SQL
查询结果和用户指定的图表类型,将数据转换为特定图表工具所需的输入格式。
##
上下文变量说明
:
* `target_chart_type`: (String)
用户期望生成的图表类型,值为
"bar"
、
"pie"
或
"line"
。此信息来源
{{
#1746780564950
.text#}}
。
* `sql_execution_result`: (JSON Array) SQL
查询的执行结果,来源于
{{
#context
#}}
例如
`[{"category": "A", "value": 10}, {"category": "B", "value": 20}]`
。
* `user_original_query`: (String)
用户最原始的自然语言查询,可用于辅助生成图表标题
,
,来源于
{{
#sys
.query#}}
。
##
图表工具输入规范:
1.
**
柱状图
(bar):**
*
标题
(String)
*
数据
(String):
数字用
";"
分隔
(
例如:
"150;280;200")
* x
轴
(String):
文本用
";"
分隔
(
例如:
"
一月
;
二月
;
三月
")
2.
**
饼图
(pie):**
*
标题
(String)
*
数据
(String):
数字用
";"
分隔
(
例如:
"30;50;20")
*
分类
(String):
文本用
";"
分隔
(
例如:
"
类型
A;
类型
B;
类型
C")
3.
**
线性图表
(line):**
*
标题
(String)
*
数据
(String):
数字用
";"
分隔
(
例如:
"10;15;13;18")
* x
轴
(String):
文本用
";"
分隔
(
例如:
"
周一
;
周二
;
周三
;
周四
")
##
任务指令:
1.
**
解析核心数据
**:
*
将输入的
`sql_json_string_result` (
它是一个字符串
) **
作为
JSON
进行解析
**
。解析后的结果可能是单个
JSON
对象(如果
SQL
只返回一行)或一个
JSON
对象数组(如果
SQL
返回多行)。我们将其称为
`core_sql_data`
。
*
例如,如果
`sql_json_string_result`
是字符串
`"[{\"colA\": \"val1\", \"colB\": 10}]"`
,那么
`core_sql_data`
就是实际的数组
`[{"colA": "val1", "colB": 10}]`
。
*
如果
`sql_json_string_result`
是字符串
`"{\"colA\": \"val1\", \"colB\": 10}"`
,那么
`core_sql_data`
就是实际的对象
`{"colA": "val1", "colB": 10}`
。为了统一处理,如果它是单个对象,请将其视为只包含一个元素的数组。
2.
**
生成图表标题
**:
参考
`user_original_query`
,生成一个简洁明了的
`chart_tool_title`
。
3.
**
数据提取与格式化
(
基于
`core_sql_data`)**:
*
分析
`core_sql_data`
。数组中的每个对象代表一个数据点。你需要从中识别出用作标签
/
类别
/x
轴的字段(通常是文本或日期类型)和用作数值
/
数据的字段(通常是数字类型)。
* **
根据
`target_chart_type`
指示的类型进行处理:
**
* **
若为
"bar"**:
*
从
`core_sql_data`
中提取所有对象的数值字段值,用
";"
连接成
`chart_tool_data_string`
。
*
提取所有对象的标签字段值,用
";"
连接成
`chart_tool_label_string` (
对应
x
轴
)
。
* **
若为
"pie"**:
*
从
`core_sql_data`
中提取所有对象的数值字段值,用
";"
连接成
`chart_tool_data_string`
。
*
提取所有对象的标签字段值,用
";"
连接成
`chart_tool_label_string` (
对应分类
)
。
* **
若为
"line"**:
*
从
`core_sql_data`
中提取所有对象的数值字段值,用
";"
连接成
`chart_tool_data_string`
。
*
提取所有对象的标签字段值,用
";"
连接成
`chart_tool_label_string` (
对应
x
轴
).
*
确保
`core_sql_data`
中至少有一个标签
/
类别字段和一个数值字段可供提取。如果字段不明确(例如,多个数字列),优先选择第一个文本
/
日期字段作为标签,第一个数字字段作为数据,或根据
`user_original_query`
中的暗示选择。
4.
**
构建输出
**:
*
以严格的
JSON
对象格式输出以下字段:
* `chart_tool_title` (String)
* `chart_tool_data_string` (String)
* `chart_tool_label_string` (String)
* `chart_type_final` (String,
其值应等于输入的
`target_chart_type`)
##
示例(假设变量已按上述说明传入):
*
若
`target_chart_type` = "bar"
*
若
`sql_json_string_result` (
字符串
) = `"[{\"product_name\": \"
产品
A\", \"total_sales\": 5500}, {\"product_name\": \"
产品
B\", \"total_sales\": 7200}]"`
*
若
`user_original_query` = "
查询产品销售额柱状图
"
期望的输出
JSON:
```json
{
"chart_tool_title": "
产品销售额柱状图
",
"chart_tool_data_string": "5500;7200",
"chart_tool_label_string": "
产品
A;
产品
B",
"chart_type_final": "bar"
}
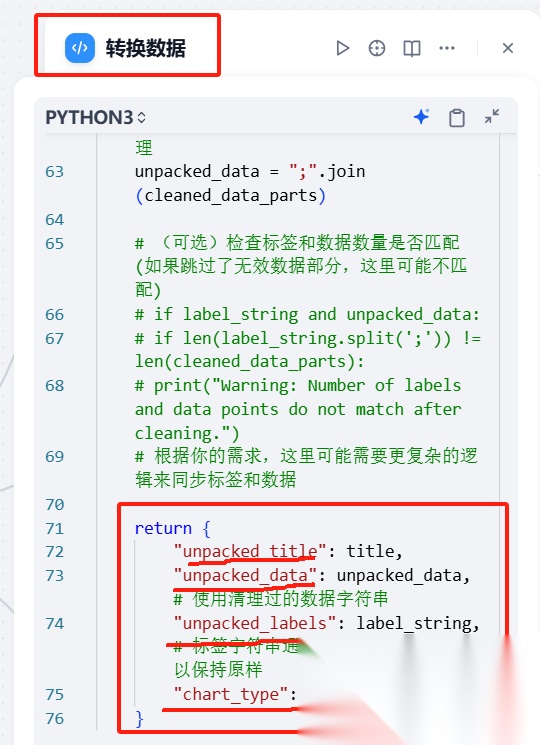
**(七)第七步根据用户输入内容结合模型判断按照什么类型的图标展示。**在上一结点基础上点击“+”号,加入“代码执行”结点,这里我们需要将数据库返回数据进行图表格式数据转化。输入变量接入大模型处理后的数据结构,规定输出变量字段及类型。
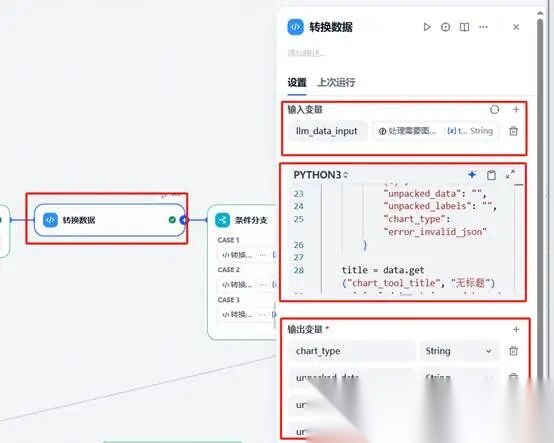
Python****脚本代码参考如下:
import json
import re #
导入正则表达式模块
def main(llm_data_input):
llm_data_str = llm_data_input
# 1.
清理
Markdown
代码块标记
(
保持你现有的健壮清理逻辑
)
llm_data_str = llm_data_str.strip()
if llm_data_str.startswith("```json"):
llm_data_str = llm_data_str[len("```json"):]
elif llm_data_str.startswith("```"):
llm_data_str = llm_data_str[len("```"):]
if llm_data_str.endswith("```"):
llm_data_str = llm_data_str[:-len("```")]
llm_data_str = llm_data_str.strip()
data = {}
try:
data = json.loads(llm_data_str)
except json.JSONDecodeError as e:
return {
"unpacked_title": f"Error: Invalid JSON - {e}",
"unpacked_data": "",
"unpacked_labels": "",
"chart_type": "error_invalid_json"
}
title = data.get("chart_tool_title", "
无标题
")
original_data_string = data.get("chart_tool_data_string", "") #
获取原始数据字符串
label_string = data.get("chart_tool_label_string", "")
chart_type = data.get("chart_type_final")
if chart_type is None:
chart_type = "unknown_type_from_llm"
# 2.
清理和验证
data_string (
这是关键的修改部分
)
cleaned_data_parts = []
if original_data_string: #
只有当原始数据字符串非空时才处理
parts = original_data_string.split(';')
for part in parts:
part = part.strip() #
移除每个部分前后的空格
if part: #
确保部分不是空字符串
try:
#
尝试转换为
float
来验证它是否是有效数字
#
我们仍然以字符串形式保存,因为插件期望分号分隔的字符串
float(part) #
如果这里失败,会抛出
ValueError
cleaned_data_parts.append(part)
except ValueError:
#
如果转换失败,可以选择:
#
a)
跳过这个无效的部分
(
可能会导致数据和标签数量不匹配,需谨慎
)
#
b)
将其替换为一个默认值,如
"0"
#
c)
或者,如果一个无效就认为整个数据有问题,可以返回错误
cleaned_data_parts.append("0") #
方案
b:
替换为
"0"
# print(f"Warning: Invalid data part '{part}' replaced with '0'.")
else:
#
如果部分是空字符串
(
例如来自
";;")
,也替换为
"0"
或跳过
cleaned_data_parts.append("0") #
方案
b:
替换为
"0"
# print(f"Warning: Empty data part replaced with '0'.")
#
重新组合成干净的数据字符串
#
如果
cleaned_data_parts
为空
(
例如原始数据字符串就是空的,或者所有部分都无效且被跳过
)
#
那么
unpacked_data
将是空字符串,这需要图表插件能处理或我们在这里进一步处理
unpacked_data = ";".join(cleaned_data_parts)
#
(可选)检查标签和数据数量是否匹配
(
如果跳过了无效数据部分,这里可能不匹配
)
# if label_string and unpacked_data:
# if len(label_string.split(';')) != len(cleaned_data_parts):
# print("Warning: Number of labels and data points do not match after cleaning.")
#
根据你的需求,这里可能需要更复杂的逻辑来同步标签和数据
return {
"unpacked_title": title,
"unpacked_data": unpacked_data, #
使用清理过的数据字符串
"unpacked_labels": label_string, #
标签字符串通常不需要转为数字,所以保持原样
"chart_type": chart_type
}
(八)第八步展示对应类型的图表。为了保障结果按照我们预想的目标进行输出,我们进行条件判定以及对应图表结点设置。
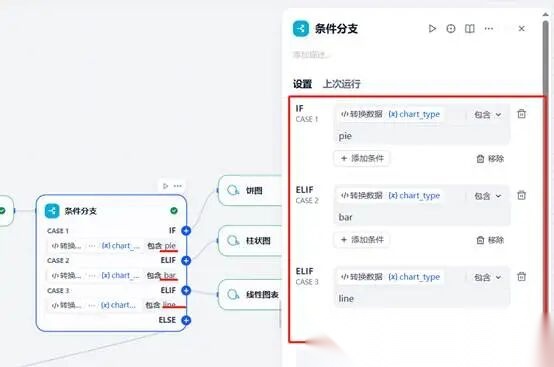
通过“条件分支”判断好图形后,我们开始增加对应的图标插件。
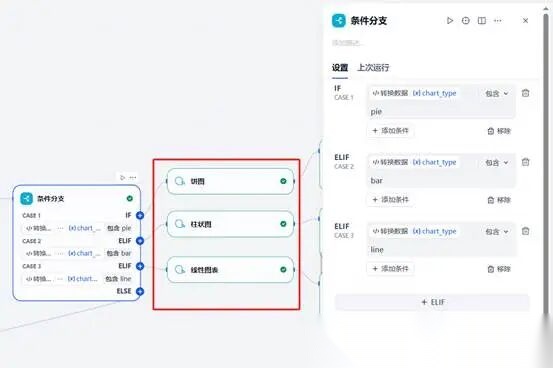
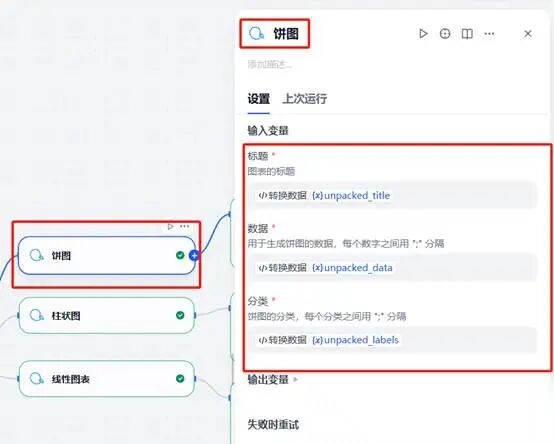
按照“代码执行”结点设定的图标的标题等参数进行参数接入。
然后按照饼图插件结果按照饼图输出结果。
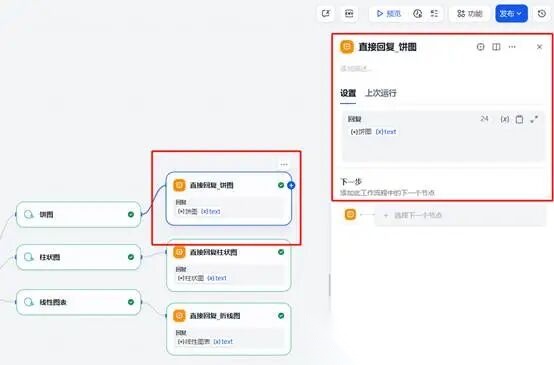
柱状图、线性图插件依次拖入,接入图表相关参数,直接回复。
五、总体编排效果如下展示。

六、整体调试。其实我省掉了很多环节,每个结点增加完后均可调试运行,查看是否达到自己预期结果。
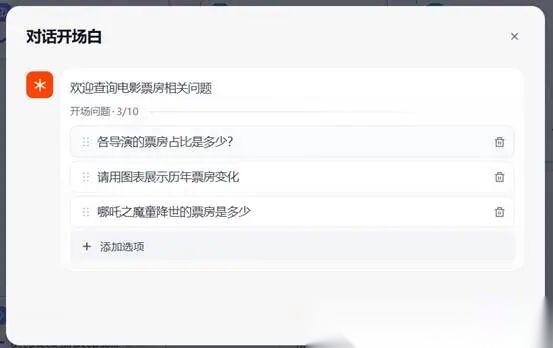
**(一)设置开场白。**我们可以对用户输入的方式进行设置,我们提供两种,第一种,预设三个问题,用户直接提问;第二种,用户结合自己的想法提问。在画布右侧找到“功能”按钮,弹出窗口如下图所示:我们点击开场白设置,并输入内容,我们设计三个内置问题:
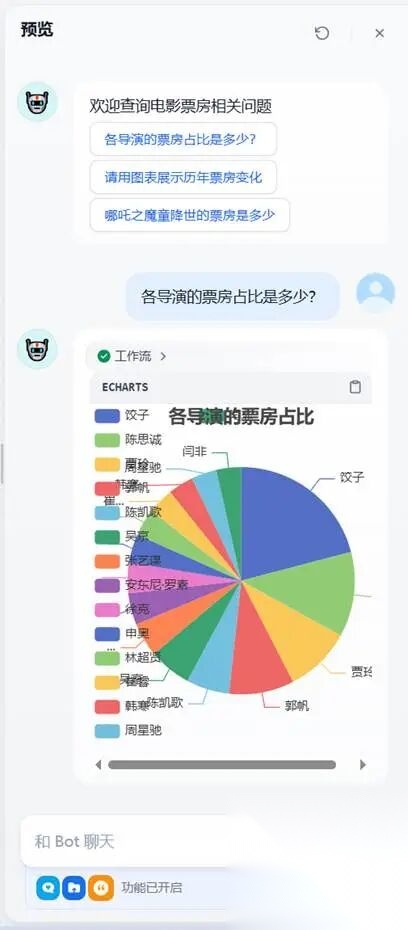
**1.**各导演的票房占比是多少?
**2.**查询历年票房变化?
**3.**查询陈思诚导演的票房总数?
(二)调试“预览”是激动人心的时刻就要来了。
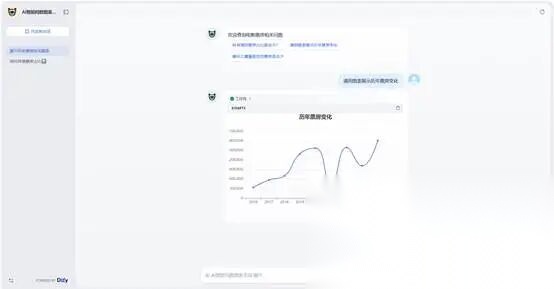
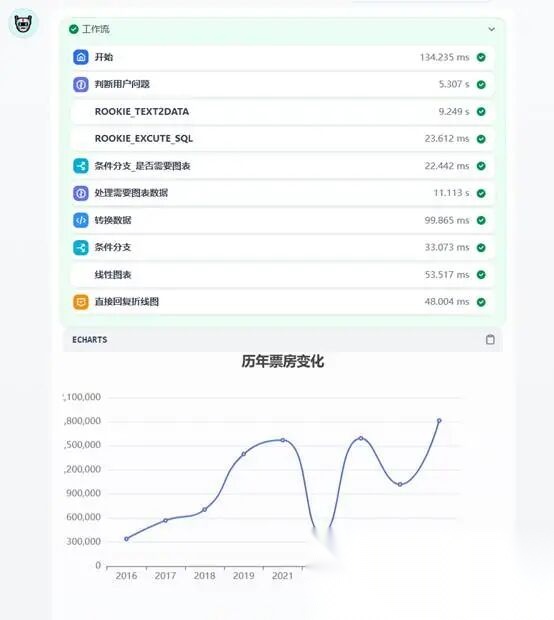
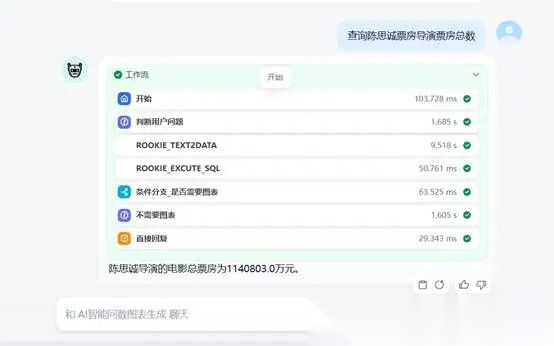
(三)看着调试没有问题我们点击发布,发布后查看效果。发布后我们到Dify平台“探索”中找到我们的智能体。如下图效果,我们点击“票房历年变化”,智能体列出了整个工作流的执行过程。
接下来我们自己做下提问“查看陈思诚导演票房总数情”。结果直接输出了回复,没有用图表输出。
如何学习大模型 AI ?
我国在AI大模型领域面临人才短缺,数量与质量均落后于发达国家。2023年,人才缺口已超百万,凸显培养不足。随着Al技术飞速发展,预计到2025年,这一缺口将急剧扩大至400万,严重制约我国Al产业的创新步伐。加强人才培养,优化教育体系,国际合作并进,是破解困局、推动AI发展的关键。
但是具体到个人,只能说是:
“最先掌握AI的人,将会比较晚掌握AI的人有竞争优势”。
这句话,放在计算机、互联网、移动互联网的开局时期,都是一样的道理。
我在一线互联网企业工作十余年里,指导过不少同行后辈。帮助很多人得到了学习和成长。
我意识到有很多经验和知识值得分享给大家,也可以通过我们的能力和经验解答大家在人工智能学习中的很多困惑,所以在工作繁忙的情况下还是坚持各种整理和分享。但苦于知识传播途径有限,很多互联网行业朋友无法获得正确的资料得到学习提升,故此将重要的AI大模型资料包括AI大模型入门学习思维导图、精品AI大模型学习书籍手册、视频教程、实战学习等录播视频免费分享出来。

2025最新大模型学习路线
明确的学习路线至关重要。它能指引新人起点、规划学习顺序、明确核心知识点。大模型领域涉及的知识点非常广泛,没有明确的学习路线可能会导致新人感到迷茫,不知道应该专注于哪些内容。
对于从来没有接触过AI大模型的同学,我帮大家准备了从零基础到精通学习成长路线图以及学习规划。可以说是最科学最系统的学习路线。

针对以上大模型的学习路线我们也整理了对应的学习视频教程,和配套的学习资料。
大模型经典PDF书籍
新手必备的大模型学习PDF书单来了!全是硬核知识,帮你少走弯路!

配套大模型项目实战
所有视频教程所涉及的实战项目和项目源码等

博主介绍+AI项目案例集锦
MoPaaS专注于Al技术能力建设与应用场景开发,与智学优课联合孵化,培养适合未来发展需求的技术性人才和应用型领袖。


这份完整版的大模型 AI 学习资料已经上传优快云,朋友们如果需要可以微信扫描下方优快云官方认证二维码免费领取【保证100%免费】

为什么要学习大模型?
2025人工智能大模型的技术岗位与能力培养随着人工智能技术的迅速发展和应用 , 大模型作为其中的重要组成部分 , 正逐渐成为推动人工智能发展的重要引擎 。大模型以其强大的数据处理和模式识别能力, 广泛应用于自然语言处理 、计算机视觉 、 智能推荐等领域 ,为各行各业带来了革命性的改变和机遇 。

适合人群
- 在校学生:包括专科、本科、硕士和博士研究生。学生应具备扎实的编程基础和一定的数学基础,有志于深入AGI大模型行业,希望开展相关的研究和开发工作。
- IT行业从业人员:包括在职或失业者,涵盖开发、测试、运维、产品经理等职务。拥有一定的IT从业经验,至少1年以上的编程工作经验,对大模型技术感兴趣或有业务需求,希望通过课程提升自身在IT领域的竞争力。
- IT管理及技术研究领域人员:包括技术经理、技术负责人、CTO、架构师、研究员等角色。这些人员需要跟随技术发展趋势,主导技术创新,推动大模型技术在企业业务中的应用与改造。
- 传统AI从业人员:包括算法工程师、机器视觉工程师、深度学习工程师等。这些AI技术人才原先从事机器视觉、自然语言处理、推荐系统等领域工作,现需要快速补充大模型技术能力,获得大模型训练微调的实操技能,以适应新的技术发展趋势。

课程精彩瞬间
大模型核心原理与Prompt:掌握大语言模型的核心知识,了解行业应用与趋势;熟练Python编程,提升提示工程技能,为Al应用开发打下坚实基础。
RAG应用开发工程:掌握RAG应用开发全流程,理解前沿技术,提升商业化分析与优化能力,通过实战项目加深理解与应用。
Agent应用架构进阶实践:掌握大模型Agent技术的核心原理与实践应用,能够独立完成Agent系统的设计与开发,提升多智能体协同与复杂任务处理的能力,为AI产品的创新与优化提供有力支持。
模型微调与私有化大模型:掌握大模型微调与私有化部署技能,提升模型优化与部署能力,为大模型项目落地打下坚实基础。




顶尖师资,深耕AI大模型前沿技术
实战专家亲授,让你少走弯路

一对一学习规划,职业生涯指导
- 真实商业项目实训
- 大厂绿色直通车
人才库优秀学员参与真实商业项目实训
以商业交付标准作为学习标准,具备真实大模型项目实践操作经验可写入简历,支持项目背调
大厂绿色直通车,冲击行业高薪岗位


文中涉及到的完整版的大模型 AI 学习资料已经上传优快云,朋友们如果需要可以微信扫描下方优快云官方认证二维码免费领取【保证100%免费】

















 2071
2071

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









