



01.引言
DeepSeek R1 的整个训练过程不过是在其基础模型(即 deepseek V3)之上使用不同的强化学习方法而已。
从本地运行的微小基础模型开始,我们将使用 DeepSeek R1 技术报告从零开始构建一切,同时在每个步骤中都会介绍相关理论知识。
闲话少说,我们直接开始吧!
02.代码概述
本博客中显示的所有代码都可以在 GitHub 代码库中找到:
Github: https://github.com/FareedKhan-dev/train-deepseek-r1
代码库的组织结构如下:

03 .环境搭建
使用以下命令克隆该代码仓并使用以下命令安装所需的库:
git clone https://github.com/FareedKhan-dev/train-deepseek-r1.git``cd train-deepseek-r1``pip install -r requirements.txt
现在,让我们导入所需的库。
# Import necessary libraries``import logging``import os``import sys``import re``import math``from dataclasses import dataclass, field``from typing import List, Optional``# Import PyTorch and Hugging Face Transformers``import torch``import transformers``from transformers import (` `AutoModelForCausalLM,` `AutoTokenizer,` `HfArgumentParser,` `TrainingArguments,` `set_seed,` `TrainerCallback,` `TrainerControl,` `TrainerState,``)``from transformers.trainer_utils import get_last_checkpoint``# Import dataset utilities``import datasets``from datasets import load_dataset``# Import libraries from TRL (Transformers Reinforcement Learning)``from trl import (` `AutoModelForCausalLMWithValueHead,` `PPOConfig,` `PPOTrainer,` `GRPOTrainer,` `GRPOConfig,` `SFTTrainer``)``# Import math-related utilities``from latex2sympy2_extended import NormalizationConfig``from math_verify import LatexExtractionConfig, parse, verify
04 .训练数据集
虽然论文没有明确说明 RL 预训练的初始数据集,但我们认为它应该以推理为主。因此,为了尽可能接近原始版本,我们将使用这两个HuggingFace上开源的数据集:
NuminaMath-TIR:https://huggingface.co/datasets/AI-MO/NuminaMath-TIR
Bespoke-Stratos-17k:https://huggingface.co/datasets/bespokelabs/Bespoke-Stratos-17k
NuminaMath-TIR 包含 70K 道数学题,其中的信息栏显示了解题背后的 COT(推理链)。该数据集在我们的实验中主要用于训练R1-Zero。我们来看看它的样本:
# Load the "AI-MO/NuminaMath-TIR" dataset from DigitalLearningGmbH``MATH_le = load_dataset("AI-MO/NuminaMath-TIR", "default")` `# Access the first sample in the training set``print(MATH_le['train'][0])``#### OUTPUT ####``{` `'problem': 'What is the degree of the polynomial 4 +5x^3 ... ',` `'solution': 'This polynomial is not written in ...',` `'messages': [{'from': 'user', 'value': 'The problem ...'}]``}``#### OUTPUT ####
Bespoke-Stratos 包含 17K 个数学和代码问题。它的样本是这样的:
# Load the "Bespoke-Stratos-17k" dataset from bespokelabs``bespoke_rl = load_dataset("bespokelabs/Bespoke-Stratos-17k", "default")` `# Access the first sample in the training set``print(bespoke_rl['train'][0])``#### OUTPUT ####``{` `'system': 'Your role as an assistant involves ... ',` `'conversations': [{'from': 'user', 'value': 'Return your ...'}]``}``#### OUTPUT ####
不一定非要选择这些数据集,只要是以推理为重点(一个问题及其逐步解决方案),大家可以选择任何推理类的数据集。
05
DeepSeek-R1训练概述
因此,在介绍技术实现之前,先简单介绍一下 DeepSeek-R1,它并不是从零开始训练的。相反,他们从一个相当聪明的 LLM 开始,他们已经有了 DeepSeek-V3,但他们想让它成为一个推理巨星。
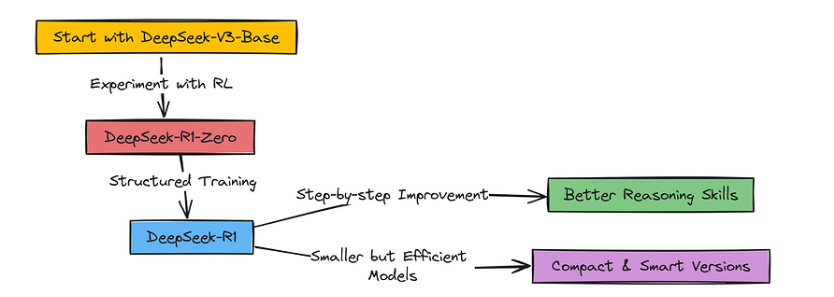
DeepSeek R1 实现概览
为此,他们使用了强化学习(Reinforcement Learning),简称 RL。但这不仅仅是一个简单的训练过程。而是由多个步骤组成的完整流程,他们称之为"流水线式训练"。研究团队最初尝试了纯强化学习(DeepSeek-R1-Zero),想看看模型是否能自主产生推理能力,这更像是一个探索性实验。到了真正的DeepSeek-R1模型时,他们采用了更系统的分阶段训练方法:先通过初始化数据为模型打下基础,接着进行强化学习训练,然后补充更多数据,再进行强化学习优化…整个过程就像打怪升级,循序渐进地提升模型能力!
这样做的目的是让这些语言模型更善于思考问题。好的,这就是在我们深入研究每个步骤的疯狂细节之前的超级简短版本。
06
选择我们的基础模型
DeepSeek团队选择DeepSeek-V3作为创建R1-Zero和R1的基础模型,但其685 GB的巨大容量显然不是我们所能承受的。
为了简单起见,我们将使用更小的基本模型 Qwen/Qwen2.5-0.5B-Instruct(0.9 GB 大小)。如果您的 GPU RAM 较大,甚至可以加载未量化的 LLM,那么您可以使用更大的模型,如 Qwen/Qwen2.5-7B-Instruct。
让我们来看看基础模型的基本信息:
MODEL_NAME = "Qwen/Qwen2.5-0.5B-Instruct"``OUTPUT_DIR = "data/Qwen-GRPO-training" # For saving our trained model``# Create output directory if it doesn't exist``os.makedirs(OUTPUT_DIR, exist_ok=True)``# Initialize tokenizer with chat template``tokenizer = AutoTokenizer.from_pretrained(` `MODEL_NAME,` `trust_remote_code=True,` `padding_side="right"``)``# Set pad token if not set``if tokenizer.pad_token is None:` `tokenizer.pad_token = tokenizer.eos_token``print(f"Vocabulary size: {len(tokenizer)}")``print(f"Model max length: {tokenizer.model_max_length}")``print(f"Pad token: {tokenizer.pad_token}")``print(f"EOS token: {tokenizer.eos_token}")``#### OUTPUT ####``Vocabulary size: 151665``Model max length: 131072``Pad token: <|endoftext|>``EOS token: <|im_end|>``#### OUTPUT ####
上述输出是有关模型的一些基本信息,请看看我们的基础模型共有多少个参数。
# Initialize base model``model = AutoModelForCausalLM.from_pretrained(` `MODEL_NAME,` `trust_remote_code=True,` `torch_dtype=torch.bfloat16``)``print(f"Model parameters: {model.num_parameters():,}")``#### OUTPUT ####``Model parameters: 494,032,768``#### OUTPUT ####
接近 0.5B 的参数,让我们从中打印一个简单问题的回复,然后进入下一步。
# Check CUDA availability``device = torch.device("cuda" if torch.cuda.is_available() else "cpu")``print(f"Using device: {device}")``# Move model to the appropriate device``model.to(device)``# Test basic inference``def test_model_inference(user_input: str):` `"""Test basic model inference with the loaded model and tokenizer."""` `messages = [` `{"role": "system", "content": "You are Qwen, a helpful assistant."},` `{"role": "user", "content": user_input}` `]` `# Apply chat template` `text = tokenizer.apply_chat_template(` `messages,` `tokenize=False,` `add_generation_prompt=True` `)` `# Tokenize and generate` `inputs = tokenizer(text, return_tensors="pt").to(device)` `outputs = model.generate(` `**inputs,` `max_new_tokens=100,` `do_sample=True,` `temperature=0.7` `)` `response = tokenizer.decode(outputs[0], skip_special_tokens=True)` `return response``# Test the model``test_input = "how are you?"``response = test_model_inference(test_input)``print(f"Test Input: {test_input}")``print(f"Model Response: {response}")``#### OUTPUT ####``"Test Input: how are you?``Model Response: As an AI language model I dont have feelings ..."``#### OUTPUT ####
因此,这个小型模型的输出相当可靠,可以用来作为 DeepSeek基础模型进行训练。
07
RL设置中的Policy Model
在选定基础模型后,接下来我们需要理解如何通过基础强化学习(Reinforcement Learning, RL)框架训练大语言模型(LLM)。以DeepSeek R1为例,他们的起点是DeepSeek V3基础模型,而我们的案例将基于Qwen2.5–0.5B-Instruct模型。这里的"起点"是指:在最终版模型发布前,团队会先创建一个初始版本(即DeepSeek R1 Zero),该初始版本存在一些缺陷,需要通过后续优化改进。
具体来说,初始版本(R1 Zero)的创建过程如下:将DeepSeek V3或Qwen2.5–0.5B模型作为强化学习智能体(Actor)——即负责执行决策的实体,通过强化学习算法进行训练。我们首先通过示意图来理解其运作机制:
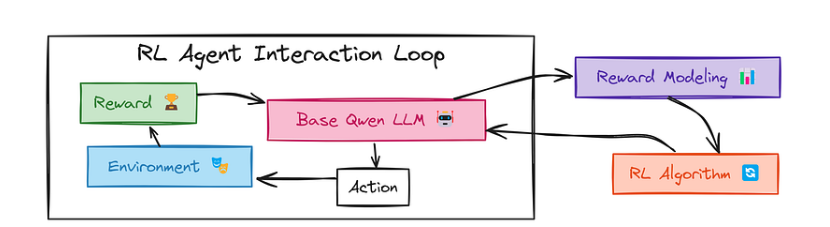
Qwen 2.5 as an agent workflow
强化学习代理(DeepSeek V3/Qwen2–0.5B)首先采取一个动作(Action),即针对给定问题生成答案和相关推理过程,该问题被输入到其所在的环境(Environment)中。在此场景下,环境即指代任务本身的推理过程。
当代理执行动作后,环境会返回一个奖励(Reward)。这种奖励类似于反馈机制,用于告知基础模型(DeepSeek V3/Qwen2–0.5B)其动作的质量。例如,正向奖励表示代理可能给出了正确答案或进行了有效推理;负向奖励则提示存在问题。这一反馈信号会被传回基础模型,帮助其通过学习并调整未来的动作策略,从而优化后续奖励的获取。
08
用于R1-Zero的GRPO算法
我们已经了解了基本的 RL 流程,现在我们需要了解 DeepSeek 在 R1-Zero 中使用的具体 RL 算法。
现有的强化学习(RL)算法种类繁多,但传统RL方法依赖于一个称为"评论家"(critic)的组件来辅助主要决策模块(即actor,如DeepSeek-V3/Qwen2-0.5B)。这种评论家模型通常与执行者模型规模相当且结构复杂,导致计算成本几乎翻倍。然而,DeepSeek团队在训练其初始模型R1-Zero时采用了GRPO(组相对策略优化)算法,该算法通过直接从一组动作的反馈结果中动态计算"基线"(即优质动作的参考标准),从而完全省去了单独的评论家模型。
让我们画出 GRPO 如何用于 R1-Zero 训练的流程图,然后对其进行解读。
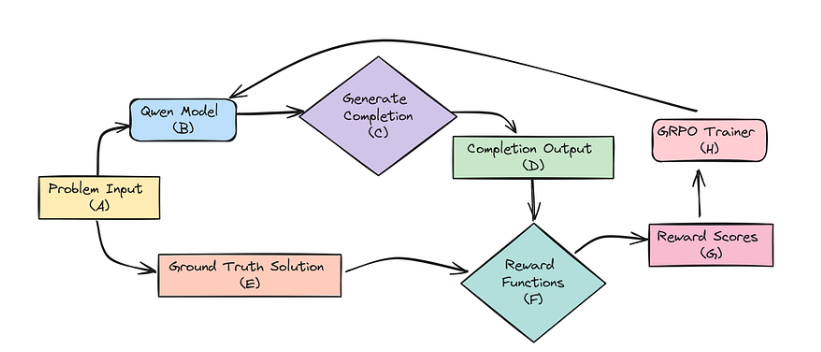
用于 DeepSeek R1-Zero 的 GRPO 流程
让我们来了解DeepSeek中的GRPO如何与我们的基础模型(Qwen2-0.5B)协同工作。首先,将问题输入(A)提供给Qwen模型(B),Qwen会通过生成补全(C)尝试生成答案。最终的完成输出(D)包含位于标签内的推理步骤和在标签中的最终解决方案。
接下来,将问题输入(A)和标准答案(E)输入奖励函数(F),这些函数作为智能评分器发挥作用。它们会将Qwen生成的解答(D)与正确答案进行对比,并从以下多个维度进行评估:
-
Accuracy: 答案是否正确?
-
Format : 标签和标签是否使用得当?
-
Reasoning Steps: 推理逻辑是否清晰
-
Cosine Scaling:回答是否简洁
-
Repetition Penalty :是否存在不必要的重复
这些评估会产生奖励分数(G),随后传递给GRPO训练器(H)。训练器通过梯度调整Qwen模型(B),优化其答案生成机制。这一过程被称为梯度奖励策略优化,其核心在于综合运用梯度计算、奖励反馈和策略调整三要素,持续优化Qwen模型的响应质量,从而实现系统性能的最大化。
在接下来的章节中,我们将开始对训练数据集进行预处理,以便进行 GRPO 训练。
09
提示词模版
我们沿用了DeepSeek中GRPO算法中的思维引导模板来构建R1 Zero系统,如下:
# DeepSeek system prompt for GRPO based training``SYSTEM_PROMPT = (` `"A conversation between User and Assistant. The user asks a question,` `and the Assistant solves it. The assistant "` `"first thinks about the reasoning process in the mind and` `then provides the user with the answer. The reasoning "` `"process and answer are enclosed within <think> </think>` `and <answer> </answer> tags, respectively, i.e., "` `"<think> reasoning process here </think><answer> answer here </answer>"``)
该系统提示词明确定义了基础模型(Qwen2-0.5B)的角色定位:作为智能助手,需在输出答案前执行分步骤推理。
标签和标签被用于构建模型的回答,将其内部推理与最终答案分开,以便更好地进行评估和奖励。
10
预处理训练数据
现在,我们已经准备好了系统提示,需要根据模板转换训练数据。
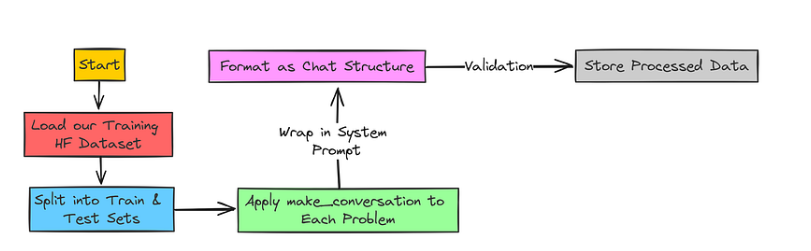
预处理数据集概览
我们需要创建 make_conversation 函数来处理对话。
# Function to structure the training data``def make_conversation(example):` `"""Convert dataset examples into conversation format."""` `return {` `"prompt": [` `{"role": "system", "content": SYSTEM_PROMPT},` `{"role": "user", "content": example["problem"]},` `],` `}
我们将构建专用数据处理函数,该函数将遍历训练数据集,针对每行数据生成包含系统提示词及动态拼接问题陈述的字典结构。现在着手实现这个实现数据集格式化处理的核心功能模块。
# Load and prepare dataset``def load_math_dataset():` `"""Load and prepare the mathematics dataset."""` `dataset = load_dataset(` `"AI-MO/NuminaMath-TIR",` `name="default",` `split=['train', 'test']` `)` `# Convert splits into dictionary` `dataset = {` `'train': dataset[0],` `'test': dataset[1]` `}` `# Apply conversation format` `for split in dataset:` `dataset[split] = dataset[split].map(make_conversation)` `# Remove 'messages' column if exists` `if "messages" in dataset[split].column_names:` `dataset[split] = dataset[split].remove_columns("messages")` `return dataset
一切准备就绪,让我们把训练数据转换成所需的格式,并打印出训练集和测试集的大小。
# Load our training dataset and printing train/test size``dataset = load_math_dataset()``print(f"Train set size: {len(dataset['train'])}")``print(f"Test set size: {len(dataset['test'])}")``#### OUTPUT ####``Train set size: 72441``Test set size: 99``#### OUTPUT ####
既然我们已经拆分了数据集,在进入下一步之前,我们需要对上述功能进行验证(检查user/assistant对话是否存在)。
def validate_dataset(dataset):` `"""Perform basic validation checks on the dataset."""` `# Define the required fields for the dataset` `required_fields = ["problem", "prompt"]` `# Loop through the 'train' and 'test' splits of the dataset` `for split in ['train', 'test']:` `print(f"\nValidating {split} split:")` `# Retrieve column names from the dataset` `fields = dataset[split].column_names` `# Check if any required fields are missing` `missing = [field for field in required_fields if field not in fields]` `if missing:` `print(f"Warning: Missing fields: {missing}") # Warn if fields are missing` `else:` `print("✓ All required fields present") # Confirm all fields are present` `# Retrieve the first sample from the dataset split` `sample = dataset[split][0]` `# Extract the 'prompt' field, which contains a list of messages` `messages = sample['prompt']` `# Validate the prompt format:` `# - It should contain at least two messages` `# - The first message should be from the 'system' role` `# - The second message should be from the 'user' role` `if (len(messages) >= 2 and` `messages[0]['role'] == 'system' and` `messages[1]['role'] == 'user'):` `print("✓ Prompt format is correct") # Confirm correct format` `else:` `print("Warning: Incorrect prompt format") # Warn if format is incorrect``# Validate dataset``validate_dataset(dataset)
输出如下:
Validating train split:``✓ All required fields present``✓ Prompt format is correct``Validating test split:``✓ All required fields present``✓ Prompt format is correct
我们的数据集验证成,这意味着我们已经成功地转换了训练数据集。
11
奖励函数
我们在 GRPO 部分已经看到,它通过五种不同的方式来评估基础模型的回答:
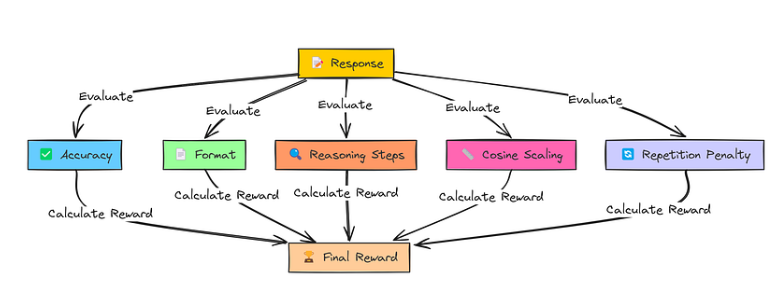
奖励函数
-
Accuracy: 答案是否正确?
-
Format : 标签和标签是否使用得当?
-
Reasoning Steps: 推理逻辑是否清晰
-
Cosine Scaling:回答是否简洁
-
Repetition Penalty :是否存在不必要的重复
每一个函数都会计算每个响应的奖励,我们需要对它们进行编码。所以,让我们先实现这个函数的功能。
12
Accuracy Reward
精度奖励(Accuracy Reward)最容易理解,但需要的代码有点复杂。在这个奖励模型中,我们要检查我们的基础模型在数学上的回答是否等同于真值。
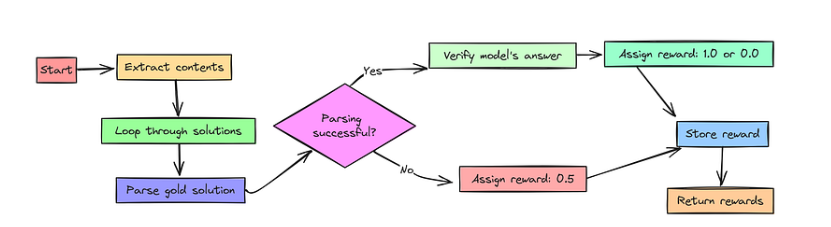
Accuracy Reward
如果模型答案在数学上是正确的,我们会给予 1.0 的奖励。如果答案不正确,奖励则为 0.0。在无法解析真值解决方案的情况下,我们会给予 0.5 的中性奖励,以避免不公平的惩罚。现在,让我们来实现这个功能。
def accuracy_reward(completions, solution, **kwargs):` `"""` `Reward function to check if the model's response is mathematically` `equivalent to the ground truth solution.` `Uses latex2sympy2 for parsing and math_verify for validation.` `"""` `# Extract responses` `contents = [completion[0]["content"] for completion in completions]` `rewards = []` `for content, sol in zip(contents, solution):` `# Parse the ground truth solution` `gold_parsed = parse(sol, extraction_mode="first_match",` `extraction_config=[LatexExtractionConfig()])` `if gold_parsed: # Check if parsing was successful` `# Parse the model's answer with relaxed normalization` `answer_parsed = parse(` `content,` `extraction_config=[` `LatexExtractionConfig(` `normalization_config=NormalizationConfig(` `nits=False,` `malformed_operators=False,` `basic_latex=True,` `equations=True,` `boxed="all",` `units=True,` `),` `boxed_match_priority=0,` `try_extract_without_anchor=False,` `)` `],` `extraction_mode="first_match",` `)` `# Reward 1.0 if correct, 0.0 if incorrect` `reward = float(verify(answer_parsed, gold_parsed))` `else:` `# If ground truth cannot be parsed, assign neutral reward (0.5)` `reward = 0.5` `print("Warning: Failed to parse gold solution:", sol)` `rewards.append(reward)` `return rewards
在此函数中,我们检查模型回答是否等同于正确答案。与比较原始文本不同,我们采用以下策略:
-
使用 latex2sympy2 将解决方案转换为结构化数学格式
-
如果解析失败,则给予 0.5 的中性奖励。
-
提取模型输出并进行归一化处理,以提高稳健性
-
使用 math_verify 检查解析后的响应与解析后的解决方案是否匹配。
-
如果正确则赋值 1,如果不正确则赋值 0
这确保了精度奖励不仅涉及文本相似性,而且涉及真正的数学答案的正确性。
13
Format Reward
格式奖励(Format Reward)的目的是确保我们的模型遵循指令并正确组织输出。我们要求它将推理过程放在标记中,将最终答案放在标记中。这个奖励函数正是要检查这一点!
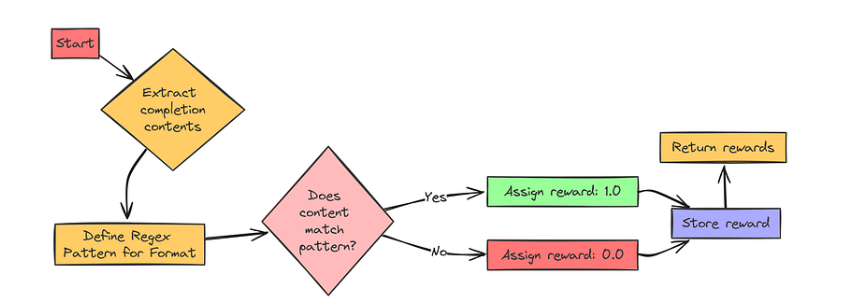
Format Reward
如果模型正确使用了这些标签,我们就给它 1 的奖励!这将鼓励模型关注我们想要的输出结构。我们来编个代码实现该功能:
# Implement Format Reward Function``def format_reward(completions, **kwargs):` `"""` `Reward function to check if the completion has the correct format:` `<think>...</think> <answer>...</answer>.` `"""` `# Define the regex pattern for the desired format` `pattern = r"^<think>.*?</think>\s*<answer>.*?</answer>$"` `# Extract the content from each completion` `completion_contents = [completion[0]["content"] for completion in completions]` `# Check if each completion matches the pattern` `matches = [re.match(pattern, content, re.DOTALL | re.MULTILINE)` `for content in completion_contents]` `# Reward 1.0 for correct format, 0.0 otherwise` `return [1.0 if match else 0.0 for match in matches]
在上述函数中:
-
我们使用正则表达式(regex)定义一个模式。这种模式内容为 “the content should start with , have anything inside until , then some spaces, then , anything inside until , and then end there”。
-
我们从每个模型的输出中获取实际的文本内容。
-
然后我们使用 re.match 来查看每个内容是否完美匹配我们的模式。re.DOTALL 使正则表达式中的 . 也能匹配换行符,而 re.MULTILINE 则让 ^ 和 $ 匹配整个字符串的开头和结尾,而不仅仅是每一行的开头和结尾。
-
最后,如果完全符合格式,我们就奖励 1,不符合则奖励 0。这是对格式正确性的严格开关奖励。
14
Reasoning Steps Reward
推理步骤奖励(Reasoning Steps Reward)有点聪明。我们希望鼓励模型展示其 “思考过程”。因此,我们将对包含类似推理步骤的内容进行奖励:
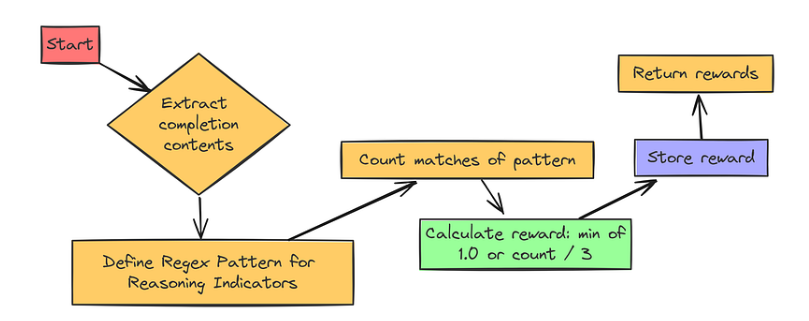
Reasoning Steps Reward
我们将寻找通常出现在逐步推理中的关键词和模式,比如:
-
Step 1, Step 2, etc.
-
Numbered lists like 1, 2
-
项目要点如: - or *
-
过渡词如: First, Second, Next, Finally
其中包含上述内容越多,奖励就越好。让我们来编写这个推理步骤奖励函数的代码:
def reasoning_steps_reward(completions, **kwargs):` `r"""` `Reward function to encourage clear step-by-step reasoning.` `It looks for patterns like "Step 1:", numbered lists, bullet points,` `and transition words.` `"""` `# Regex pattern to find indicators of reasoning steps` `pattern = r"(Step \d+:|^\d+\.|\n-|\n\*|First,|Second,|Next,|Finally,)"` `# Extract completion contents` `completion_contents = [completion[0]["content"] for completion in completions]` `# Count the number of reasoning step indicators in each completion` `matches = [len(re.findall(pattern, content, re.MULTILINE))` `for content in completion_contents]` `# Reward is proportional to the number of reasoning steps, maxing out at 1.0` `# We're using a "magic number" 3 here - encourage at least 3 steps for full reward` `return [min(1.0, count / 3) for count in matches]
我们创建了一个更复杂的 regex 模式。它会查找我们上面列出的所有推理关键词。奖励的计算公式为 min(1.0,count / 3)。这意味着:
-
如果找到 3 个或更多推理指示词(count>= 3),则奖励为 1.0(最大奖励)。
-
如果找到的数量较少(例如,count= 1 或 2),则会得到部分奖励(如 1/3 或 2/3)。
-
如果找不到(count= 0),奖励就是 0.0。
上述代码中,数字3 是一个魔法数字。这意味着是 “以 3 步左右的推理步数为目标,获得满分”,如果您想鼓励更多或更少的步数,可以调整这个数字。
15
Cosine Scaled Reward
余弦缩放奖励(Cosine Scaled Reward)则更先进一些。它鼓励正确答案简明扼要,对较长的错误答案则不太苛刻。
Cosine Scaling Concept
我们可以简单这么理解:
-
对于正确答案:我们希望奖励更简短、更直接的答案,而不是长篇大论的答案。简短、正确的答案往往更好。
-
对于错误答案:简短的错误答案可能比至少尝试推理的较长的错误答案更糟糕。因此,我们希望对简短的错误答案的惩罚比对较长的错误答案的惩罚更重。
让我们来看看实现上述代码:
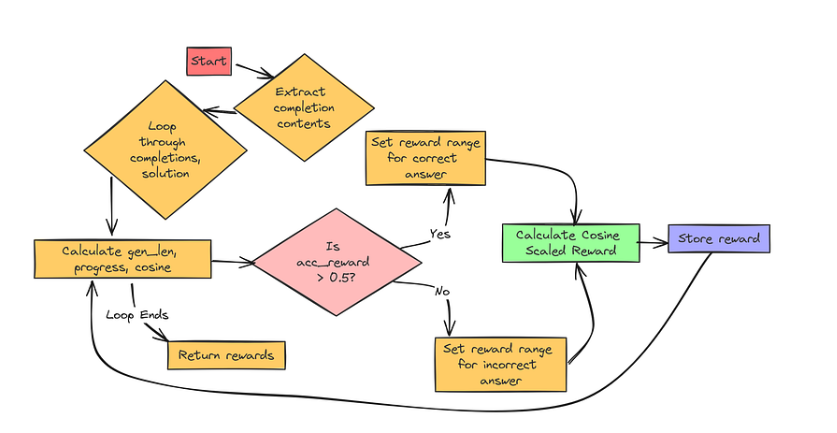
# Implement Cosine Scaled Reward Function``def get_cosine_scaled_reward(` `min_value_wrong: float = -0.5,` `max_value_wrong: float = -0.1,` `min_value_correct: float = 0.8,` `max_value_correct: float = 1.0,` `max_len: int = 1000,``):` `"""` `Returns a cosine scaled reward function. This function scales the accuracy reward` `based on completion length. Shorter correct solutions get higher rewards,` `longer incorrect solutions get less penalty.` `"""` `def cosine_scaled_reward(completions, solution, accuracy_rewards, **kwargs):` `"""` `Cosine scaled reward function that adjusts accuracy rewards based on completion length.` `"""` `contents = [completion[0]["content"] for completion in completions]` `rewards = []` `for content, sol, acc_reward in zip(contents, solution, accuracy_rewards):` `gen_len = len(content) # Length of the generated answer` `progress = gen_len / max_len # How far we are to max length` `cosine = math.cos(progress * math.pi) # Cosine value based on progress` `if acc_reward > 0.5: # Assuming accuracy_reward gives ~1.0 for correct answers` `min_value = min_value_correct` `max_value = max_value_correct` `else: # Incorrect answer` `min_value = max_value_wrong # Note the swap!` `max_value = min_value_wrong` `# Cosine scaling formula!` `reward = min_value + 0.5 * (max_value - min_value) * (1.0 + cosine)` `rewards.append(float(reward))` `return rewards` `return cosine_scaled_reward
上述代码中:
-
get_cosine_scaled_reward(…)会生成一个用于训练的奖励函数, min_value_wrong/max_value_wrong(错误答案的惩罚范围)和 min_value_correct/max_value_correct(正确答案的奖励范围)等参数自定义缩放比例。
-
在 cosine_scaled_reward(…)中,我们根据完成度、解决方案和精度度奖励来计算奖励。
-
它计算 gen_len,将其归一化为 progress = gen_len / max_len,并得出一个余弦值,该值从 1 开始(短答案),一直减小到-1(长答案)。
-
如果 acc_reward > 0.5,则使用正确的奖励范围,否则使用错误的奖励范围,但会交换最小/最大值,以减少对较长的错误答案的惩罚。
16
Repetition Penalty Reward
重复惩罚奖励的目的是阻止我们的模型陷入循环和重复。我们希望它能产生新颖、多样的推理和答案,而不是一遍又一遍地复制粘贴相同的语句!
Repetition Penalty Idea
如果模型使用相同的词语序列(n-grams)的次数过多,该奖励函数就会对模型进行惩罚。我们将在示例中使用大小为 3 的 n-gram,但大家也可以自行调整。
如果模型的回复经常重复,就会得到负奖励(惩罚)。如果模型更加多样化,避免重复,惩罚就会减少。代码如下:
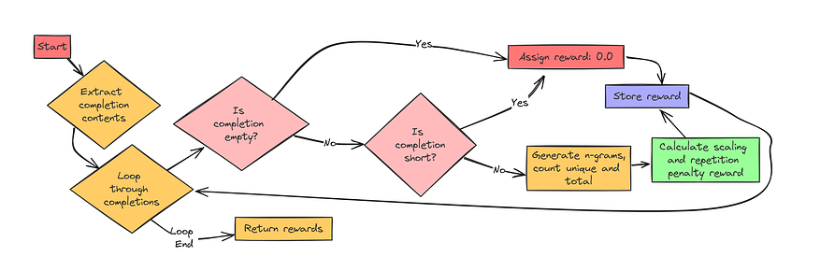
def get_repetition_penalty_reward(ngram_size: int = 3, max_penalty: float = -0.1):` `"""` `Returns a repetition penalty reward function. Penalizes repetitions of n-grams` `in the generated text.` `"""` `if max_penalty > 0:` `raise ValueError(f"max_penalty {max_penalty} should not be positive")` `def zipngram(text: str, ngram_size: int):` `"""Helper function to generate n-grams from text."""` `words = text.lower().split() # Lowercase and split into words` `return zip(*[words[i:] for i in range(ngram_size)]) # Create n-grams` `def repetition_penalty_reward(completions, **kwargs) -> float:` `"""` `Repetition penalty reward function.` `"""` `contents = [completion[0]["content"] for completion in completions]` `rewards = []` `for completion in contents:` `if completion == "": # No penalty for empty completions` `rewards.append(0.0)` `continue` `if len(completion.split()) < ngram_size: # No penalty for short completions` `rewards.append(0.0)` `continue` `ngrams = set() # Use a set to store unique n-grams` `total = 0` `for ng in zipngram(completion, ngram_size): # Generate n-grams` `ngrams.add(ng) # Add n-gram to the set (duplicates are ignored)` `total += 1 # Count total n-grams` `# Calculate scaling factor: more repetition -> higher scaling` `scaling = 1 - len(ngrams) / total` `reward = scaling * max_penalty # Apply penalty based on scaling` `rewards.append(reward)` `return rewards` `return get_repetition_penalty_reward
在上述代码中:
-
我们的 get_repetition_penalty_reward(…)创建了一个奖励函数来惩罚重复,其参数包括 ngram_size(默认值为 3)和 max_penalty(负值,例如-0.1)。
-
zipngram(text,ngram_size)是一个辅助函数,它通过将文本转换为小写、拆分成单词并使用 zip(*[words[i:] for i in range(ngram_size)]) 进行高效提取来生成 n-gram。
-
repetition_penalty_reward(…)计算每次完成的惩罚。如果它是空的或太短,就会得到 0.0 的奖励。
-
惩罚的比例为 scaling = 1-len(ngrams)/total,其中 total 是 n-grams的数量,len(ngrams) 是唯一计数。重复次数越多,缩放比例越接近 1,惩罚也就越大。
-
最终奖励为scaling * max_penalty,这意味着重复次数越少,惩罚越小,而重复次数越多,负奖励越大。
至此,我们已经实现了所有五个奖励函数,下面进入下一阶段,定义我们的训练参数。
17
R1-Zero 训练参数设置
现在,我们要编写一个配置,以便对奖励函数的实际工作方式进行微调。那么,让我们来定义这个配置类:
# Define GRPOScriptArguments for reward function parameters``@dataclass``class GRPOScriptArguments:` `"""` `Script arguments for GRPO training, specifically related to reward functions.` `"""` `reward_funcs: list[str] = field(` `default_factory=lambda: ["accuracy", "format"],` `metadata={` `"help": "List of reward functions. Possible values: 'accuracy', 'format', 'reasoning_steps', 'cosine', 'repetition_penalty'"` `},` `)` `cosine_min_value_wrong: float = field(` `default=-0.5,` `metadata={"help": "Minimum reward for cosine scaling for wrong answers"},` `)` `cosine_max_value_wrong: float = field(` `default=-0.1,` `metadata={"help": "Maximum reward for cosine scaling for wrong answers"},` `)` `cosine_min_value_correct: float = field(` `default=0.8,` `metadata={"help": "Minimum reward for cosine scaling for correct answers"},` `)` `cosine_max_value_correct: float = field(` `default=1.0,` `metadata={"help": "Maximum reward for cosine scaling for correct answers"},` `)` `cosine_max_len: int = field(` `default=1000,` `metadata={"help": "Maximum length for cosine scaling"},` `)` `repetition_n_grams: int = field(` `default=3,` `metadata={"help": "Number of n-grams for repetition penalty reward"},` `)` `repetition_max_penalty: float = field(` `default=-0.1,` `metadata={"help": "Maximum (negative) penalty for for repetition penalty reward"},` `)
上述代码中:
-
装饰器@dataclass 可轻松创建一个用于存储数据的类。而GRPOScriptArguments 类则用于保存奖励设置。
-
reward_funcs 列表决定使用哪些奖励,从[“accuracy”, “format”]开始,但也可以添加更多奖励,如
"reasoning_steps", "cosine","repetition_penalty".等。 -
有些设置可以控制cosine_scaled_reward 和repetition_penalty_reward的工作方式,从而调整奖励的发放方式。
接下来是Transformer库中的 TrainingArguments。这是一个主要的配置对象,几乎控制着训练过程的一切。
# Define TrainingArguments from transformers``training_args = TrainingArguments(` `output_dir=OUTPUT_DIR, # Output directory for checkpoints and logs` `overwrite_output_dir=True,` `num_train_epochs=1, # Total number of training epochs` `per_device_train_batch_size=8, # Batch size per device during training` `per_device_eval_batch_size=16, # Batch size for evaluation` `gradient_accumulation_steps=2, # Accumulate gradients to simulate larger batch size` `learning_rate=5e-5, # Initial learning rate for AdamW optimizer` `warmup_ratio=0.1, # Linear warmup over warmup_ratio fraction of training steps` `weight_decay=0.01, # Apply weight decay to all layers except bias and LayerNorm weights` `logging_steps=10, # Log every X updates steps` `` evaluation_strategy="steps", # Evaluate every `eval_steps` `` `eval_steps=50, # Evaluation and logging steps` `` save_strategy="steps", # Save checkpoint every `save_steps` `` `save_steps=50, # Save checkpoint every X updates steps` `save_total_limit=2, # Limit the total amount of checkpoints. Deletes the older checkpoints.` `dataloader_num_workers=2, # Number of subprocesses to use for data loading` `seed=42, # Random seed for reproducibility` `bf16=True, # Use mixed precision BFP16 training` `push_to_hub=False, # Whether to push the final model to Hugging Face Hub` `gradient_checkpointing=True, # Enable gradient checkpointing` `report_to="none", # Reporting to no one``)
18
R1-Zero 模型参数设置
最后,我们需要一个 ModelConfig。在这里,我们要对模型本身进行特定设置,比如使用哪种预训练模型、使用哪种数据类型(如 bfloat16)等等。
@dataclass``class ModelConfig:` `"""` `Configuration for the model.` `"""` `model_name_or_path: str = field(` `default=MODEL_NAME, metadata={"help": "Path to pretrained model or model identifier from huggingface.co/models"}` `)` `model_revision: Optional[str] = field(` `default="main", metadata={"help": "The specific model version to use (can be a branch name, tag name or commit id)."}` `)` `torch_dtype: Optional[str] = field(` ``default="bfloat16", metadata={"help": "Override the default `torch_dtype` and load the model under this dtype."}`` `)` `trust_remote_code: bool = field(` `default=True, metadata={"help": "Trust remote code when loading model and tokenizer."}` `)` `attn_implementation: Optional[str] = field(` `default="flash_attention_2", metadata={"help": "Attention implementation to use. 'flash_attention_2' or None"}` `)
我们的 ModelConfig 类包含关键设置,包括 model_name_or_path,默认为 Qwen 0.5B Instruct。我们使用 torch_dtype=“bfloat16” 来提高效率,并设置 trust_remote_code=True 来实现安全的远程加载。此外,还启用了 attn_implementation=“flash_attention_2”,以便在支持的情况下加快训练速度。
现在,我们需要实际创建这些配置类的实例,以便使用它们:
# Instantiate configuration objects``script_args = GRPOScriptArguments()``model_args = ModelConfig()
19
配置回调函数
接下来,我们需要获取奖励函数列表以及我们希望在训练中使用的任何 “回调函数”。回调函数就像一个小助手,可以在训练过程的不同阶段做一些事情(如记录进度、保存模型等)。现在,我们只使用一个简单的日志回调。用以将我们的奖励函数集中到一处。
# Utility function to get reward functions based on script arguments``def get_reward_functions(script_args):` `"""` `Returns a list of reward functions based on the script arguments.` `"""` `reward_funcs_list = []` `reward_funcs_registry = {` `"accuracy": accuracy_reward, # Assuming accuracy_reward is defined in previous steps` `"format": format_reward, # Assuming format_reward is defined in previous steps` `"reasoning_steps": reasoning_steps_reward, # Assuming reasoning_steps_reward is defined` `"cosine": get_cosine_scaled_reward( # Assuming get_cosine_scaled_reward is defined` `min_value_wrong=script_args.cosine_min_value_wrong,` `max_value_wrong=script_args.cosine_max_value_wrong,` `min_value_correct=script_args.cosine_min_value_correct,` `max_value_correct=script_args.cosine_max_value_correct,` `max_len=script_args.cosine_max_len,` `),` `"repetition_penalty": get_repetition_penalty_reward( # Assuming get_repetition_penalty_reward is defined` `ngram_size=script_args.repetition_n_grams,` `max_penalty=script_args.repetition_max_penalty,` `),` `}` `for func_name in script_args.reward_funcs:` `if func_name not in reward_funcs_registry:` `raise ValueError(f"Reward function '{func_name}' not found in registry.")` `reward_funcs_list.append(reward_funcs_registry[func_name])` `return reward_funcs_list
我们的回调函数,用于跟踪记录模型训练损失和其他重要信息。
logger = logging.getLogger(__name__)``class LoggingCallback(TrainerCallback):` `"""` `A simple callback for logging training information at specific steps.` `"""` `def on_step_end(self, args: TrainingArguments, state: TrainerState, control: TrainerControl, **kwargs):` `if state.global_step % args.logging_steps == 0:` `logger.info(f"Step {state.global_step}: Loss = {state.log_history[-1].get('loss', None)}, Learning Rate = {state.log_history[-1].get('learning_rate', None)}")``def get_callbacks(training_args, model_args, script_args):` `"""` `Returns a list of callbacks to be used during training.` `For now, it includes only the LoggingCallback. You can extend this to add more callbacks.` `"""` `callbacks = [LoggingCallback()] # Instantiate our LoggingCallback` `return callbacks
最后,初始化这些回调函数。
# Get reward functions and callbacks``reward_functions = get_reward_functions(script_args)``callbacks = get_callbacks(training_args, model_args, script_args)
20
GRPO训练流程
这是实际驱动 GRPO 训练的引擎。我们需要对其进行初始化,为其提供我们准备好的所有组件:模型、奖励函数、训练参数、数据集和回调!
# Create GRPOConfig from TrainingArguments``grpo_config = GRPOConfig(` `**training_args.to_dict(), # Convert TrainingArguments to dictionary and unpack` `**{` `# REMOVED model_init_kwargs here` `# We are passing the instantiated 'model' object, so GRPOTrainer doesn't need model_init_kwargs` `}``)``grpo_trainer = GRPOTrainer(` `model=model, # Our initialized Qwen model` `reward_funcs=reward_functions, # List of reward functions from previous step` `args=grpo_config, # GRPOConfig (created from TrainingArguments)` `train_dataset=dataset['train'], # Training dataset` `eval_dataset=dataset['test'], # Evaluation dataset` `callbacks=callbacks # List of callbacks``)
现在我们可以开始训练循环!只需调用 grpo_trainer 上的 train() 方法即可。
# Start the GRPO Training Loop``train_result = grpo_trainer.train()
运行该单元后,大家将看到训练过程开始。
...``INFO:__main__:Step 10: Loss = ..., Learning Rate = ...``INFO:__main__:Step 20: Loss = ..., Learning Rate = ...``...
训练需要一些时间,但我们设置了 num_train_epochs = 1,而且使用的是一个小型模型,因此这个示例的训练时间应该不会太长。但在实际的 GRPO DeepSeek R1 Zero 训练中,您可能需要训练更多的训练步骤。
21
保存R1-Zero LLM
训练完成后,我们可以保存训练好的模型,用于推理。
# Define the path to your trained model (same as OUTPUT_DIR)``TRAINED_MODEL_PATH = "data/Qwen-GRPO-training"``# Save the tokenizer``tokenizer.save_pretrained(TRAINED_MODEL_PATH)``# Save the trained model``grpo_trainer.save_model(TRAINED_MODEL_PATH)``print(f"GRPO Trained model saved to {TRAINED_MODEL_PATH}")
然后,我们只需使用以下代码加载上述模型:
# Load the tokenizer - make sure to use trust_remote_code=True if needed``tokenizer = AutoTokenizer.from_pretrained(` `TRAINED_MODEL_PATH,` `trust_remote_code=True, # If your model config requires it` `padding_side="right" # Ensure consistent padding side``)``# Set pad token if it wasn't saved or loaded correctly``if tokenizer.pad_token is None:` `tokenizer.pad_token = tokenizer.eos_token``# Load the trained model itself``trained_model = AutoModelForCausalLM.from_pretrained(` `TRAINED_MODEL_PATH,` `trust_remote_code=True, # If your model architecture requires it` `torch_dtype=torch.bfloat16 # Keep the same dtype as training for consistency``)``# Move the loaded model to your device (GPU if available)``trained_model.to(device) # 'device' is still our CUDA device from before
可以将其用于推理:
# Testing Inference with the Trained Model``def test_trained_model_inference(user_input: str):` `"""Test inference with the loaded trained model and tokenizer."""` `messages = [` `{"role": "system", "content": SYSTEM_PROMPT}, # Re-use our system prompt` `{"role": "user", "content": user_input}` `]` `# Apply chat template using our tokenizer` `text = tokenizer.apply_chat_template(` `messages,` `tokenize=False,` `add_generation_prompt=True` `)` `# Tokenize the input text` `inputs = tokenizer(text, return_tensors="pt").to(device)` `# Generate output using our *trained_model*` `outputs = trained_model.generate(` `**inputs,` `max_new_tokens=200, # Maybe generate a bit longer now` `do_sample=True,` `temperature=0.7` `)` `# Decode the generated tokens back to text` `response = tokenizer.decode(outputs[0], skip_special_tokens=True)` `return response
22
R1-Zero 存在的问题
现在,我们已经使用我们的基础模型 Qwen2-0.5B 代替他们的 DeepSeek V3(原始基础模型),完成了 R1-Zero模型的训练。
我们无法确定我们训练的模型存在哪些问题,但 DeepSeek 的研究表明,R1-Zero 模型在推理测试中表现非常出色,甚至在 AIME 2024 等任务中的得分与 OpenAI-01-0912 等更高级的模型相差无几。
这表明,使用强化学习(RL)来激励语言模型中的推理是一种很有前途的方法。但他们也注意到,DeepSeek-R1-Zero 还存在一些关键问题,需要在实际使用和更广泛的研究中加以解决。
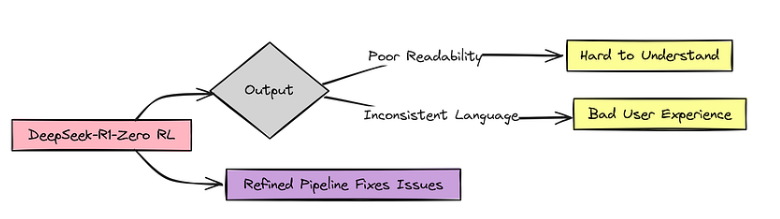
R1-Zero 的问题
DeepSeek 的研究人员指出,该模板简单,结构重点突出。它避免对推理过程本身施加任何特定内容的限制。例如,它没有说:
-
“你必须使用逐步推理法”(它只说 “推理过程”,让模型自己去定义其含义)。
-
“您必须使用特定的问题解决策略”
主要问题在于, 标记内的推理过程难以读取,人类很难跟踪和分析。另一个问题是语言混杂,当被问及多语言问题时,模型有时会在同一回答中混杂多种语言,导致输出结果不一致和混乱
如果你用西班牙语向它提问。突然之间,它的 "思维 "就会变成英语和西班牙语的杂乱混合体,不伦不类!这些问题,混乱的推理和语言的混淆,都是明显的障碍。这就是他们将最初的 R1-Zero模型转变为 R1 的两个主要原因。
23
为SFT准备冷启动数据
因此,为了解决 R1-Zero 问题,并真正让 DeepSeek 正常推理,研究人员进行了冷启动数据采集,并加入了监督微调功能。
你可以把它看作是在真正高强度的 RL 训练之前为模型打下良好的推理基础。基本上,他们想教会 DeepSeek-V3 Base 什么是好的推理,以及如何清晰地展示推理。
冷启动数据的示例之一是 Bespoke-Stratos-17k 数据集,我们之前看到过它,并将使用它创建 R1,但我们需要了解冷数据集是如何创建的,这样才不会跳过实际训练中的任何部分。
24
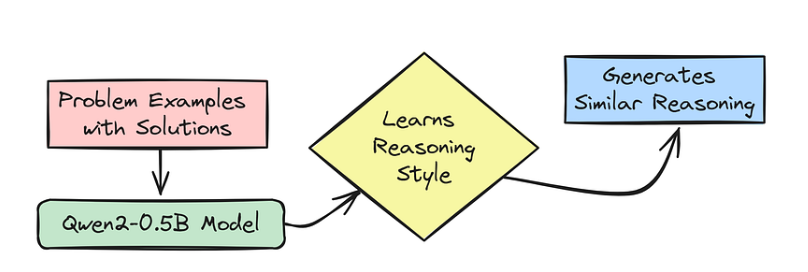
基于Long COT的少样本提示
制作冷启动数据其中一种技术是 “长思维链(CoT)的少样本提示”(Few-shot Prompting with Long Chain-of-Thought),即我们尝试向 DeepSeek-V3 Base(或在我们的案例中,Qwen2-0.5B)展示少量问题示例,并配以超级详细的逐步解决方案。这就是思维链(CoT)。
Long CoT
这种方法的目标是让模型举一反三,开始模仿这种推理方式。
对于我们的例题 “2 + 3 * 4 是多少?”,我们可以创建包含一些已解问题作为示例的提示。让我们看看在 Python 中是如何实现的:
# Loading Model and Tokenizer``MODEL_NAME = "Qwen/Qwen2.5-0.5B-Instruct"``tokenizer = AutoTokenizer.from_pretrained(MODEL_NAME, trust_remote_code=True, padding_side="right")``if tokenizer.pad_token is None:` `tokenizer.pad_token = tokenizer.eos_token``model = AutoModelForCausalLM.from_pretrained(MODEL_NAME, trust_remote_code=True, torch_dtype=torch.bfloat16).to("cuda" if torch.cuda.is_available() else "cpu")``# Generate Long COT Response``def generate_response(prompt_text):` `messages = [` `{"role": "system", "content": "You are a helpful assistant that provides step-by-step solutions."},` `{"role": "user", "content": prompt_text}` `]` `text = tokenizer.apply_chat_template(messages, tokenize=False, add_generation_prompt=True)` `inputs = tokenizer(text, return_tensors="pt").to(model.device)` `outputs = model.generate(**inputs, max_new_tokens=200, do_sample=False) # Keep it deterministic for example` `response = tokenizer.decode(outputs[0], skip_special_tokens=True)` `return response.split("<|im_start|>assistant\n")[-1].strip() # Extract assistant's response
让我们根据我们提出的问题来定义几个示例:
# Example problems with solutions (using | special_token | as delimiter)``few_shot_prompt = """``Problem: What's the square root of 9 plus 5?``Solution: <|special_token|> First, find the square root of 9, which is 3. Then, add 5 to 3. 3 + 5 equals 8. <|special_token|> Summary: The answer is 8.``Problem: Train travels at 60 mph for 2 hours, how far?``Solution: <|special_token|> Use the formula: Distance = Speed times Time. Speed is 60 mph, Time is 2 hours. Distance = 60 * 2 = 120 miles. <|special_token|> Summary: Train travels 120 miles.``Problem: What is 2 + 3 * 4?``Solution:``"""
现在,使用我们的基础模型,我们生成的样本看起来是这样的:
# Generate response for the target problem using few-shot examples``target_problem_prompt = few_shot_prompt + "What is 2 + 3 * 4?"``model_response_few_shot = generate_response(target_problem_prompt)``print("Few-shot Prompt:")``print(target_problem_prompt)``print("\nModel Response (Few-shot CoT):")``print(model_response_few_shot)
它输出这些结构化数据:
Few-shot Prompt:``Problem: What's the square root of 9 plus 5?``Solution: <|special_token|> First, find the square root of 9,` `which is 3. Then, add 5 to 3. 3 + 5 equals 8.` `<|special_token|> Summary: The answer is 8.``Problem: Train travels at 60 mph for 2 hours, how far?``Solution: <|special_token|> Use the formula: Distance = Speed times Time.` `Speed is 60 mph, Time is 2 hours. Distance = 60 * 2 = 120 miles.` `<|special_token|> Summary: Train travels 120 miles.``Problem: What is 2 + 3 * 4?``Solution:` `Model Response (Few-shot CoT):``<|special_token|> To solve 2 + 3 * 4, we need to follow the order` `of operations (PEMDAS/BODMAS). Multiplication should be performed` `before addition.``Step 1: Multiply 3 by 4, which equals 12.``Step 2: Add 2 to the result from Step 1: 2 + 12 = 14.``<|special_token|> Summary: The answer is 14.
观察上述模型在看到示例后,是如何开始用 <|special_token|> 分隔符构建答案结构,并逐步推理出摘要和最终答案的!这就是 "少样本学习 "的威力,它能引导模型实现所需的输出格式。
25
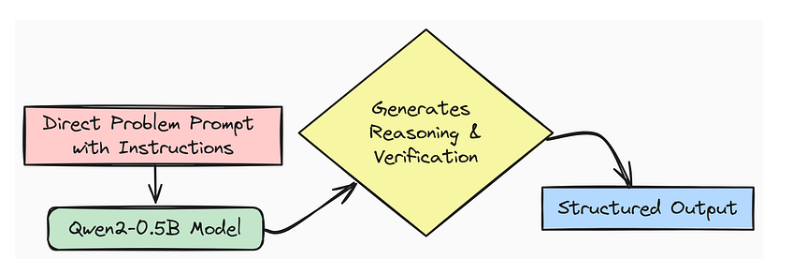
直接提示
另一种方法是直接提示法。在这里,我们直接指示模型不仅要解决问题,还要一步步明确展示其推理过程,然后验证其答案。这就是要鼓励采用一种更加审慎和深思熟虑的方法来解决问题。
Example based learning
让我们为 "2 + 3 * 4 是多少?"设计一个提示,明确要求推理和验证。下面是 Python 代码,看看它是如何运行的:
# Direct prompting example``direct_prompt_text = """``Problem: Solve this, show reasoning step-by-step, and verify:``What is 2 + 3 * 4?``"""``model_response_direct = generate_response(direct_prompt_text)``print("Direct Prompt:")``print(direct_prompt_text)``print("\nModel Response (Direct Prompting):")``print(model_response_direct)
直接提示输出非常容易理解,就是这个样子:
Direct Prompt:``Problem: Solve this, show reasoning step-by-step, and verify:``What is 2 + 3 * 4?``Model Response (Direct Prompting):``<|special_token|> Reasoning: To solve 2 + 3 * 4, I need to follow` `the order of operations, which states that multiplication should` `be done before addition.``Step 1: Multiply 3 by 4, which equals 12.``Step 2: Add 2 to the result from Step 1: 2 + 12 = 14.``Verification: To verify the answer, I can double-check the` `order of operations and the calculations. Multiplication is` `indeed performed before addition, and the calculations are correct.``<|special_token|> Summary: The answer is 14.
正如大家所看到的,通过直接询问推理和验证,该模型提供了更全面的输出,包括一个 "验证 "部分。这种方法可以直接引导模型进行我们所需的详细推理。
26
后处理细化
最后一项技术是后处理细化。有趣的是,他们甚至为此使用了已经训练好的 R1 Zero 模型的输出结果!
即使存在问题,R1-Zero 也能在一定程度上进行推理。因此,他们将 R1-Zero 的输出结果交给人类标注者进行完善,使其更简洁、更有条理,并纠正任何错误。
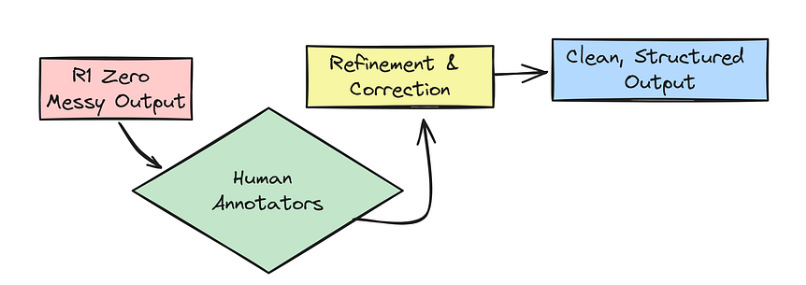
Processing Refnement
想象一下,R1-Zero 的输出可能会是这样一团糟:
<think> ummm... multiply 3 and 4... get 12... then add 2...</think>``<answer> 14 </answer>
然后,人工标注员将对其进行完善,使其更加清晰、格式更加合理:
<|special_token|> Reasoning: To solve this, we use order of operations, doing multiplication before addition.``Step 1: Multiply 3 by 4, which is 12.``Step 2: Add 2 to the result: 2 + 12 = 14.``<|special_token|> Summary: The answer is 14.
虽然我们无法在代码中完美地模拟人类的标注校准过程,但我们可以展示一个基本概念,即如何通过编程重新格式化和结构化潜在的混乱输出。
让我们来模拟一个 "杂乱无章 "的输出,看看如何对其进行改进:
# Simulated messy R1 Zero output``messy_output = "<think> ummm... multiply 3 and 4... get 12... then add 2...</think>\n<answer> 14 </answer>"``def refine_output(messy_text):` `think_content = messy_text.split("<think>")[1].split("</think>")[0].strip()` `answer_content = messy_text.split("<answer>")[1].split("</answer>")[0].strip()` `refined_text = f"""<|special_token|> Reasoning: {think_content.replace('umm...', '').strip().capitalize()}.``<|special_token|> Summary: The answer is {answer_content}."""` `return refined_text``refined_output_text = refine_output(messy_output)``print("Messy Output (Simulated R1 Zero):")``print(messy_output)``print("\nRefined Output:")``print(refined_output_text)
这将输出如下:
Messy Output (Simulated R1 Zero):``<think> ummm... multiply 3 and 4... get 12... then add 2...</think>``<answer> 14 </answer>``Refined Output:``<|special_token|> Reasoning: Multiply 3 and 4... get 12... then add 2.``<|special_token|> Summary: The answer is 14.
这个简单的 refine_output 函数只是一个基本示例。人类真正的校准涉及对推理步骤更细致入微的理解和修正。不过,它显示了核心思想:利用初始模型输出,改进其质量和结构,以创建更好的训练数据。
生成冷启动数据后,下一个关键步骤是监督微调(SFT),我们将在下一节中探讨!
27
对冷启动数据进行SFT
要生成合适的冷启动数据,并使用监督微调技术构建 R1,我们显然需要一个合适的团队和大量的代码,但值得庆幸的是,我们已经有了与冷启动形式类似的数据(Bespoke-Stratos-17k)。
我们需要知道 SFT 训练器在处理我们的训练数据时,内部发生了什么以及如何进行训练?
SFT: 是监督学习的一种形式。这意味着我们要给模型提供成对的输入和所需的输出。
在我们的案例中,输入可能是一个问题提示,而所需的输出则是训练数据集中有理有据、循序渐进的解决方案。我希望这一点能让我们清楚地了解为什么需要冷数据。
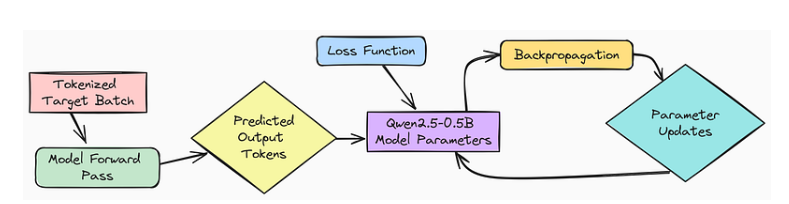
SFT 工作流程
首先,模型接收输入,例如一个问题提示。接着,它处理这个输入,并逐标记生成对解决方案的最佳猜测。这些生成的标记即为预测结果。
接下来,SFT Trainer需要评估这些预测结果的质量(好坏)。它使用一个损失函数(通常为交叉熵损失函数),通过数学方式将模型预测的标记与训练数据中的正确标记进行对比。这相当于计算模型预测结果的“误差”。
这个“误差”并不会被简单丢弃,而是学习过程中的关键信号。通过一个称为反向传播的过程,该误差被用于计算梯度。梯度如同向导,指示模型参数应调整的方向,使误差得以减小。
最后,像 AdamW 这样的优化器会利用这些梯度来微妙地调整模型的内部设参数。这些调整旨在使模型的下一次预测更接近正确答案。
28
配置R1的SFT Trainer
还记得我们在 R1-Zero 中遇到的混乱推理和语言混合问题吗?SFT 正是为了解决这些问题而设计的。通过在高质量的精炼数据上进行训练,我们可以教会模型:
-
清晰的推理风格:以易于阅读和理解的方式组织 “思考”。
-
语言一致:在答复中坚持使用一种语言,避免混淆。
我们在 SFT 中使用 Bespoke-Stratos-17k 数据集。正如我们之前看到的,该数据集中了 17,000 个数学和代码问题,其格式非常符合我们的需求。让我们快速回忆一下 Bespoke-Stratos-17k 的样本:
# Load the "Bespoke-Stratos-17k" dataset from bespokelabs``bespoke_rl = load_dataset("bespokelabs/Bespoke-Stratos-17k", "default")``# Access the first sample in the training set``bespoke_rl['train'][0]``#### OUTPUT ####``{` `'system': 'Your role as an assistant involves ... ',` `'conversations': [{'from': 'user', 'value': 'Return your ...'}]``}``#### OUTPUT ####
该数据集包含系统提示和用户助手对话,非常适合向我们的模型展示推理对话应该是怎样的。我们将再次使用 trl 库,它让 SFT 训练变得超级简单。
首先,我们需要设置我们的配置,类似于为 GRPO 所做的配置,但这次是为 SFT 所做的配置。
# Model and Output Configuration (same as before, or adjust as needed)``MODEL_NAME = "Qwen/Qwen2.5-0.5B-Instruct"``OUTPUT_DIR = "data/Qwen-SFT-training" # New output directory for SFT model``os.makedirs(OUTPUT_DIR, exist_ok=True)``# Training Arguments - similar to GRPO, but adjust for SFT``training_args = TrainingArguments(` `output_dir=OUTPUT_DIR,` `overwrite_output_dir=True,` `num_train_epochs=1, # Adjust epochs as needed` `per_device_train_batch_size=8,` `per_device_eval_batch_size=16,` `gradient_accumulation_steps=2,` `learning_rate=2e-5, # Adjust learning rate for SFT` `warmup_ratio=0.1,` `weight_decay=0.01,` `logging_steps=10,` `evaluation_strategy="no",` `eval_steps=50,` `save_strategy="steps",` `save_steps=50,` `save_total_limit=2,` `dataloader_num_workers=2,` `seed=42,` `bf16=True,` `push_to_hub=False,` `gradient_checkpointing=True,` `report_to="none",` `packing=True, # Enable data packing for efficiency` `max_seq_length=4096 # Set max sequence length``)``# Model Configuration - same as before``model_args = ModelConfig(` `model_name_or_path=MODEL_NAME,` `model_revision="main",` `torch_dtype="bfloat16",` `trust_remote_code=True,` `attn_implementation="flash_attention_2"``)
这些 TrainingArguments 和 ModelConfig 与我们在 GRPO 中使用的非常相似,但做了一些更适合 SFT 的调整(比如学习率略有不同,重要的是 packing=True 和 max_seq_length=4096,以便在更长的序列上进行高效训练)。
29
R1 SFT 训练流程
现在,让我们加载数据集:
# Load Bespoke-Stratos-17k dataset``dataset_sft = load_dataset("HuggingFaceH4/Bespoke-Stratos-17k", split='train') # Only using train split for simplicity``# Initialize tokenizer - same as before``tokenizer = AutoTokenizer.from_pretrained(` `MODEL_NAME,` `trust_remote_code=True,` `padding_side="right"``)``if tokenizer.pad_token is None:` `tokenizer.pad_token = tokenizer.eos_token
接着,我们初始化 SFTTrainer 并开始训练!
# Initialize base model for SFT - same as before``model_sft = AutoModelForCausalLM.from_pretrained(` `MODEL_NAME,` `trust_remote_code=True,` `torch_dtype=torch.bfloat16``)``# Initialize the SFT Trainer``sft_trainer = SFTTrainer(` `model=model_sft, # Our initialized Qwen model` `train_dataset=dataset_sft, # Bespoke-Stratos-17k dataset` `tokenizer=tokenizer, # Tokenizer` `args=training_args, # Training arguments` `dataset_text_field="conversations", # Field in dataset containing text - IMPORTANT for SFT` `packing=True, # Enable data packing` `max_seq_length=4096 # Max sequence length``)``# Start the SFT Training Loop``sft_train_result = sft_trainer.train()
运行此代码后,大家将看到 SFT 训练过程开始。它看起来与 GRPO 训练输出类似,显示每个记录步骤的损失和学习率。
...``INFO:__main__:Step 10: Loss = ..., Learning Rate = ...``INFO:__main__:Step 20: Loss = ..., Learning Rate = ...``...
与 GRPO 一样,训练时间取决于硬件和所选的epoch数目。在本例中,我们使用的仍然是一个小型模型,而且只有 1 个epoch,因此训练时间应该是相当快的。
30
保存 SFT R1 LLM
完成 SFT 后,我们保存新的微调模型 (R1)。
# Saving the Trained SFT Model``TRAINED_SFT_MODEL_PATH = "data/Qwen-SFT-training" # Same as OUTPUT_DIR``# Save the tokenizer``tokenizer.save_pretrained(TRAINED_SFT_MODEL_PATH)``# Save the trained model``sft_trainer.save_model(TRAINED_SFT_MODEL_PATH)``print(f"SFT Trained model saved to {TRAINED_SFT_MODEL_PATH}")
SFT 部分到此为止!现在,我们已经利用了我们的基础模型,向它展示了许多良好推理的例子,并对它进行了微调,使它能够更好地做出清晰、有条理的回答。
在经过SFT 第 1 阶段之后,我们将这种使用 SFT 的微调模型称为 R1。
SFT 之后的步骤,尤其是 RL 阶段和拒绝采样,在 Python 中从头开始实现非常复杂。注重理论理解是了解整个过程的关键。
31
面向推理的RL
在 SFT 之后,模型可以更好地进行推理,但我们希望真正关注推理质量,并解决语言混合问题。这一阶段将再次使用 RL,但奖励系统将更加智能。
这一新的奖励机制会检查模型的推理过程和答案是否与提问语言一致。例如,如果用英语提问,整个响应都应使用英语。这有效解决了模型输出中可能出现的语言混杂问题。
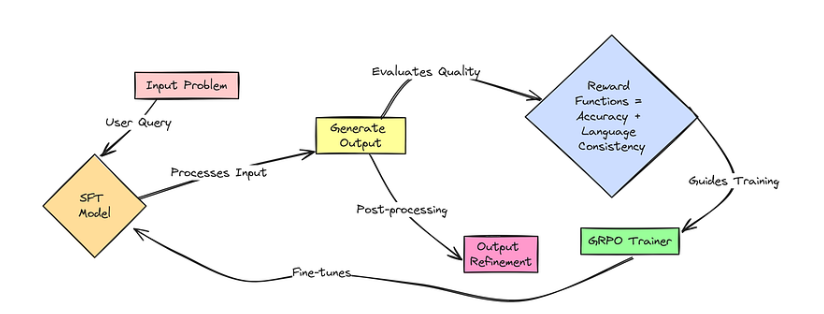
Reasoning Oriented RL
除了准确性之外,该机制还引入了语言一致性奖励,以确保SFT模型在推理和回答时始终使用与输入相同的语言。尽管沿用了R1 Zero中的GRPO算法及其训练循环,但改进了奖励信号的设计,专门针对提升模型推理能力和输出语言的统一性进行优化。
32
拒绝采样
为了获得超高质量的推理数据,DeepSeek 使用了拒绝采样(Rejection Sampling)技术。把它想象成一个过滤器,只保留最好的例子。
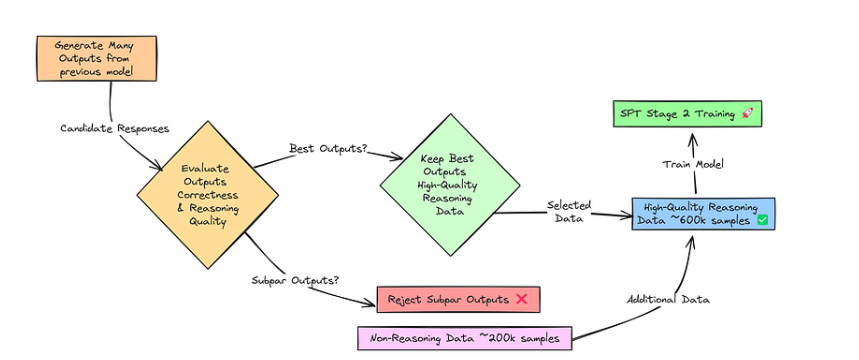
Rejection Sampling
模型会生成许多推理实例。然后对这些示例的正确性和推理质量进行评估(通常使用生成奖励模型和人工检查)。
只保留最好的高质量推理示例。结合非推理数据,这一改进后的数据集将用于第二次 SFT 阶段 ,进一步提高推理能力和综合能力。
33
SFT Stage 2 Training
最后的 RL 阶段重点是使模型成为一个在所有情况下都有用且安全的人工智能助手,而不仅仅是推理问题。这就是要与人类价值观保持一致。
不仅是准确性,奖励机制现在还包括:
-
有用性:答案是否有用、信息量大?
-
无害性:答案是否安全、公正和合乎道德?
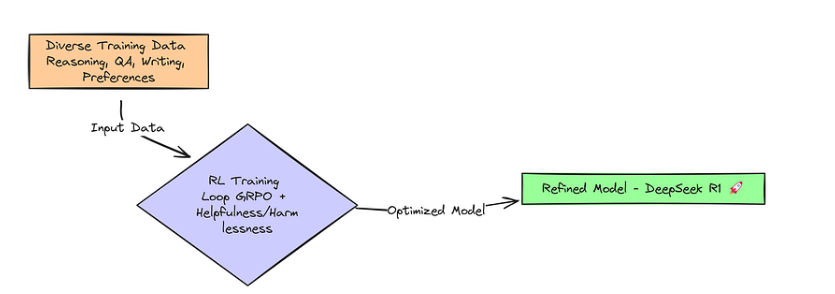
SFT Stage 2
训练数据变得多种多样,包括推理任务和人类偏好数据(哪种输出更好–更有帮助,危害更小)
现在的奖励系统兼顾了准确性、有用性和无害性。迭代 RL 训练(再次采用 GRPO)优化了模型,使其不仅擅长推理,而且还能成为安全、有用的人工智能助手,供一般用户使用,这就是 DeepSeek R1。
34
蒸馏
为了让 DeepSeek-R1 更易于使用,他们将其知识提炼为更小的模型。
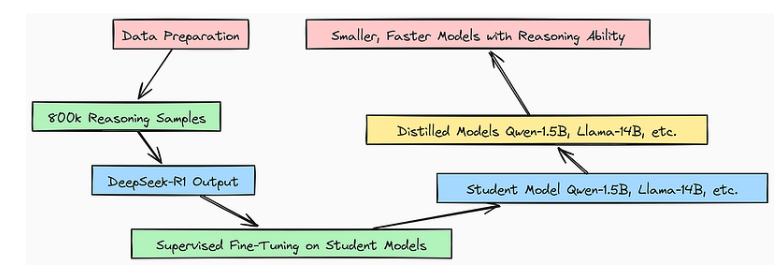
蒸馏过程
知识蒸馏通过提取大型高性能“教师”模型(如DeepSeek-R1)的知识,将其迁移到更小型的“学生”模型中。具体实现中,模型会借助海量的推理示例数据集,将DeepSeek-R1生成的输出作为目标答案进行学习。
随后,对这些小型模型进行监督微调(SFT)训练,使其能够模仿教师模型的输出。通过这种方式,最终得到更小巧、更高效的模型,它们保留了DeepSeek-R1的大部分推理能力,从而更适合广泛的实际应用。
如何学习大模型 AI ?
由于新岗位的生产效率,要优于被取代岗位的生产效率,所以实际上整个社会的生产效率是提升的。
但是具体到个人,只能说是:
“最先掌握AI的人,将会比较晚掌握AI的人有竞争优势”。
这句话,放在计算机、互联网、移动互联网的开局时期,都是一样的道理。
我在一线互联网企业工作十余年里,指导过不少同行后辈。帮助很多人得到了学习和成长。
我意识到有很多经验和知识值得分享给大家,也可以通过我们的能力和经验解答大家在人工智能学习中的很多困惑,所以在工作繁忙的情况下还是坚持各种整理和分享。但苦于知识传播途径有限,很多互联网行业朋友无法获得正确的资料得到学习提升,故此将并将重要的AI大模型资料包括AI大模型入门学习思维导图、精品AI大模型学习书籍手册、视频教程、实战学习等录播视频免费分享出来。

第一阶段(10天):初阶应用
该阶段让大家对大模型 AI有一个最前沿的认识,对大模型 AI 的理解超过 95% 的人,可以在相关讨论时发表高级、不跟风、又接地气的见解,别人只会和 AI 聊天,而你能调教 AI,并能用代码将大模型和业务衔接。
- 大模型 AI 能干什么?
- 大模型是怎样获得「智能」的?
- 用好 AI 的核心心法
- 大模型应用业务架构
- 大模型应用技术架构
- 代码示例:向 GPT-3.5 灌入新知识
- 提示工程的意义和核心思想
- Prompt 典型构成
- 指令调优方法论
- 思维链和思维树
- Prompt 攻击和防范
- …
第二阶段(30天):高阶应用
该阶段我们正式进入大模型 AI 进阶实战学习,学会构造私有知识库,扩展 AI 的能力。快速开发一个完整的基于 agent 对话机器人。掌握功能最强的大模型开发框架,抓住最新的技术进展,适合 Python 和 JavaScript 程序员。
- 为什么要做 RAG
- 搭建一个简单的 ChatPDF
- 检索的基础概念
- 什么是向量表示(Embeddings)
- 向量数据库与向量检索
- 基于向量检索的 RAG
- 搭建 RAG 系统的扩展知识
- 混合检索与 RAG-Fusion 简介
- 向量模型本地部署
- …
第三阶段(30天):模型训练
恭喜你,如果学到这里,你基本可以找到一份大模型 AI相关的工作,自己也能训练 GPT 了!通过微调,训练自己的垂直大模型,能独立训练开源多模态大模型,掌握更多技术方案。
到此为止,大概2个月的时间。你已经成为了一名“AI小子”。那么你还想往下探索吗?
- 为什么要做 RAG
- 什么是模型
- 什么是模型训练
- 求解器 & 损失函数简介
- 小实验2:手写一个简单的神经网络并训练它
- 什么是训练/预训练/微调/轻量化微调
- Transformer结构简介
- 轻量化微调
- 实验数据集的构建
- …
第四阶段(20天):商业闭环
对全球大模型从性能、吞吐量、成本等方面有一定的认知,可以在云端和本地等多种环境下部署大模型,找到适合自己的项目/创业方向,做一名被 AI 武装的产品经理。
- 硬件选型
- 带你了解全球大模型
- 使用国产大模型服务
- 搭建 OpenAI 代理
- 热身:基于阿里云 PAI 部署 Stable Diffusion
- 在本地计算机运行大模型
- 大模型的私有化部署
- 基于 vLLM 部署大模型
- 案例:如何优雅地在阿里云私有部署开源大模型
- 部署一套开源 LLM 项目
- 内容安全
- 互联网信息服务算法备案
- …
学习是一个过程,只要学习就会有挑战。天道酬勤,你越努力,就会成为越优秀的自己。
如果你能在15天内完成所有的任务,那你堪称天才。然而,如果你能完成 60-70% 的内容,你就已经开始具备成为一名大模型 AI 的正确特征了。
这份完整版的大模型 AI 学习资料已经上传优快云,朋友们如果需要可以微信扫描下方优快云官方认证二维码免费领取【保证100%免费】


















 2659
2659

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









