




 本文介绍了一种破解字体反爬虫的五步法,包括下载字体文件、使用TTFont库解析字体、构建字体映射关系、自动化爬取数据等步骤,详细解释了如何通过分析字体文件和网页源码来识别和替换被混淆的文字内容。
本文介绍了一种破解字体反爬虫的五步法,包括下载字体文件、使用TTFont库解析字体、构建字体映射关系、自动化爬取数据等步骤,详细解释了如何通过分析字体文件和网页源码来识别和替换被混淆的文字内容。
五步法破解字体反爬虫
由于字体的加载和映射工作都是由css完成的,所以就算是借助来自动化工具也无法获取对应的文字内容
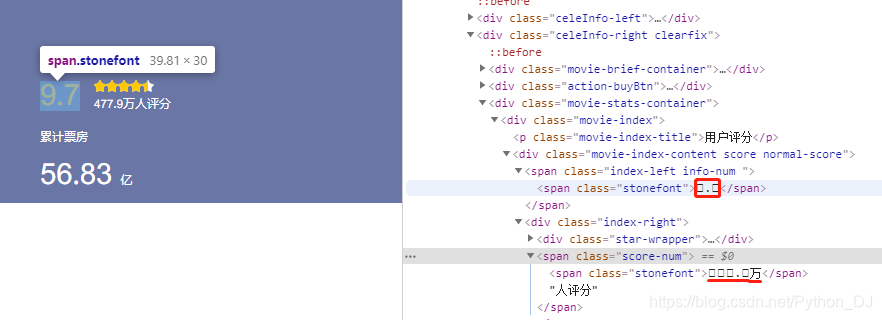
就是这种情况,它就是字体反爬虫,与之前SVG反爬虫最大的区别就是,它所有的class都是一个值,而且标签的文本也是一个方框来表示的,所以处理起来可能会比较复杂,不要担心,继续跟着我的思路,你会豁然开朗,加油吧!
再来看看网页的源码
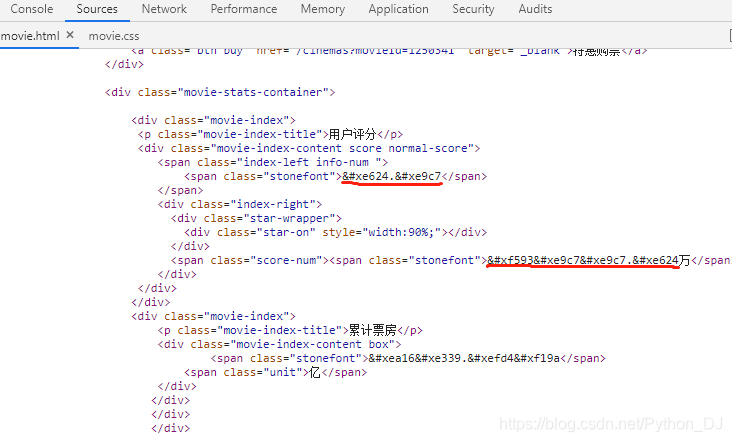
可以看到,在网页源码里面,是不同的类似符号的数据来代表网页的显示数据,例如
""".代表的就是网页显示的9.7"""
我们可以针对这种映射关系来破解字体反爬,但是,如果网站有多套字体映射,那这个恐怕就不好用了,我们要用Python来实现这种映射算法,这样就算网站更换来其他字体,我们也不用担心爬虫的健壮性

可以看到,网站加载了一个字体文件,那我们把这个文件下载到本地,查看一下它是什么个情况
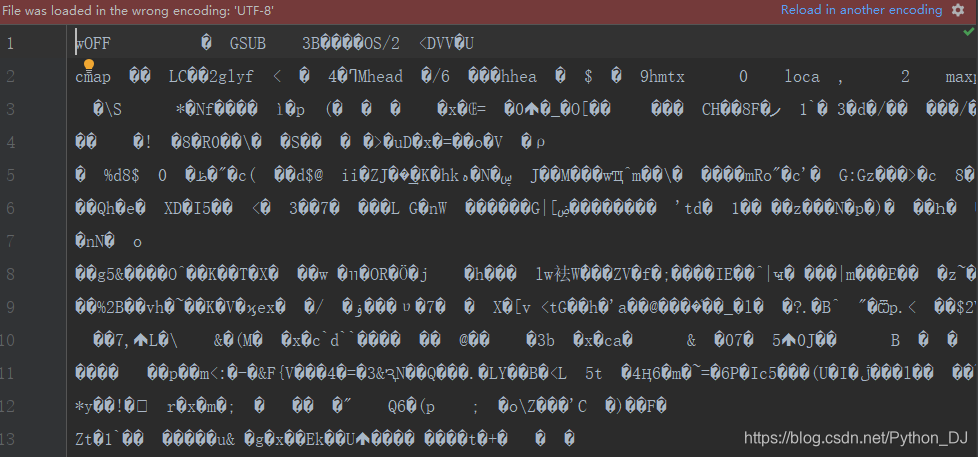
显示的是乱码,那是不是就没办法查看了呢,在Python中有一个专门处理字体的库from fontTools.ttLib import TTFont,在字体反爬过程中,我们要反复的使用这个库,如果不熟悉,那就要去问问度娘了,或者跟着我的思路走,我也会讲到一部分项目里面用到的方法,例如:
font = TTFont(r"D:\gcw\learn_crawler\font\movie.woff") # 打开字体文件
# 保存之后直接注释该代码,不然下面使用会报错,说--没有某某属性
font.saveXML(r"D:\gcw\learn_crawler\font\movie.xml") # 另存为xml格式
你看到了,现在是XML格式的文件了,那我们来看看XML是个啥样子吧
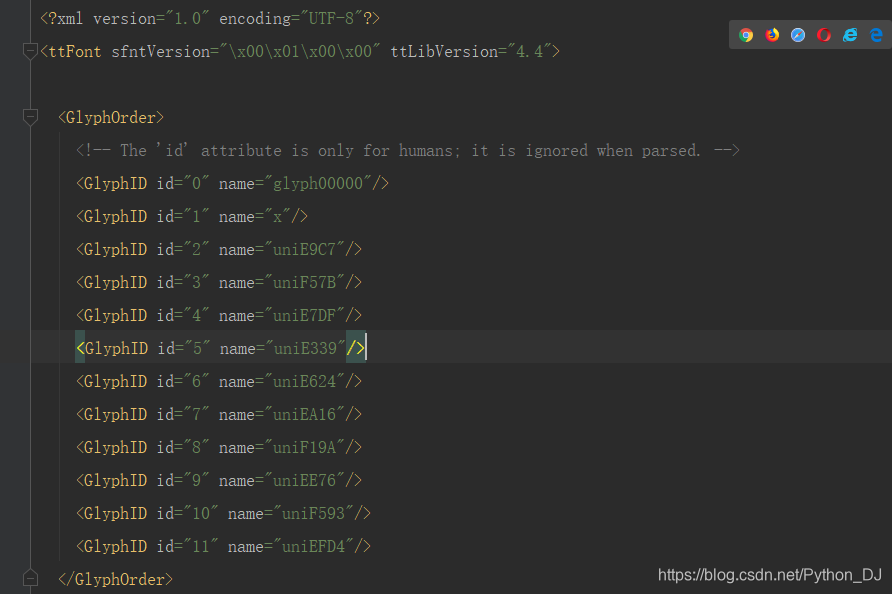
是不是有惊喜,看到了和网页有相同的内容.,这么看来&#x只是和uni替换了而已,在映射的时候我们逆向替换就行了,另外网页都是小写,上图的name值都是大写,这有什么关系呢,一个upper()即可迎刃而解
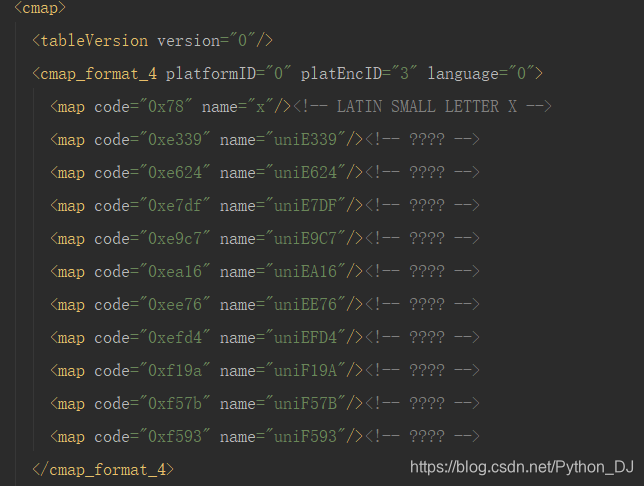
cmap # 就是网页和字体数据的一些映射情况
当然cmap属性我们是用来参考的,真正使用的是下面这个数据
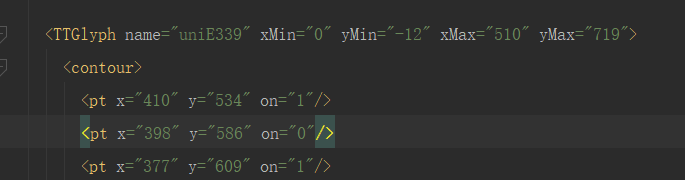
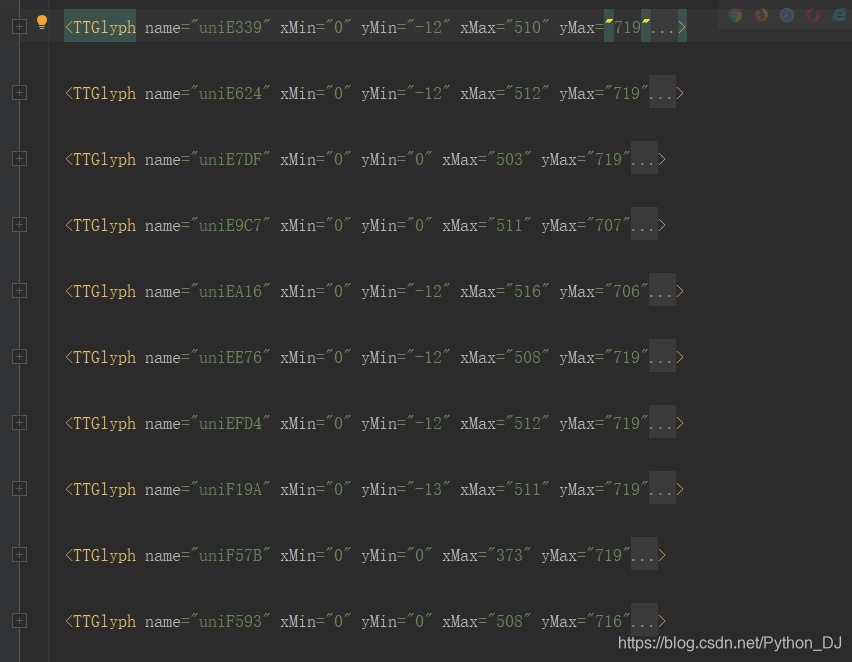
这个数据包含的是字体的字形数据,字形数据相同,那么这两个字肯定代表的是同一个字,至于推理过程就不在详述,只需要知道这个字形数据才是关键就可以了。
讲完这些之后,你应该会对字体反爬有一些了解了,话不多说,直接上源码,几乎一步一个注释,你想看不懂都难,嗯哼!!!
from fontTools.ttLib import TTFont
import requests
import re
import os
import hashlib
from parsel import Selector
from urllib import parse
import xml.etree.ElementTree as ET
# 第一步 :手动获取网站的字体,粘贴到项目对应目录,以备分析
# 第二步:使用TTFont生成字体文件对象后另存为xml,毕竟下载的直接看是乱码
font = TTFont(r"D:\gcw\learn_crawler\font\movie.woff") # 打开字体文件
# 保存之后直接注释该代码,不然下面使用会报错,说--没有某某属性
# font.saveXML(r"D:\gcw\learn_crawler\font\movie.xml") # 另存为xml格式
# 第三步:观察xml数据,这一步尤为重要,很多参数不太重要,只需要知道一点,使用的是字形数据glyf
# 字符 字形名
# <map code="0xe339" name="uniE339"/><!-- ???? -->
# 第四步:根据xml的原始数据,手动给出映射数据
xml_path = os.path.dirname(__file__)
# 读取字体的xml文件
tree = ET.ElementTree(file=xml_path + "/font/movie.xml")
# tree = ET.parse(xml_path + "/font/movie.xml") # 上下两种方式都可以读取数据
# 简单介绍tree对象的一些方法,如下面的这一行可以获取根元素对象
root = tree.getroot()
# 根元素对象的标签名和属性
# print(root.tag, root.attrib)
# 还有一些其他属性,有需要自行测试使用
# 'append', 'attrib', 'clear', 'extend', 'find', 'findall', 'findtext', 'get',
# 'getchildren', 'getiterator', 'insert', 'items', 'iter', 'iterfind', 'itertext',
# 'keys', 'makeelement', 'remove', 'set', 'tag', 'tail', 'text'
# 先定义两个空白字典,用于存储映射数据,然后遍历元素
s = {"name": "", "value": "0", "hex": ""} # s并没有使用,只是为来定义数据的格式给的参考
ys = {"name": ""}
# 遍历XML的TTGlyph这个标签,用的是iter这个方法
for elem in tree.iter(tag="TTGlyph"):
# 标题 属性字典格式 字典键值对
# print(elem.tag, elem.attrib, elem.attrib["name"])
if len(elem.attrib["name"]) == 7:
ys["name"] = elem.attrib["name"]
# print(ys)
# 注意:为了更好的观测数据,我用打印出来的ys数据,填充到来下面的这个字典,value值是通过网页对比获得
base_font = {
"font": [{'name': 'uniE339', "value": "6", "hex": ""},
{'name': 'uniE624', "value": "9", "hex": ""},
{'name': 'uniE7DF', "value": "2", "hex": ""},
{'name': 'uniE9C7', "value": "7", "hex": ""},
{'name': 'uniEA16', "value": "5", "hex": ""},
{'name': 'uniEE76', "value": "0", "hex": ""},
{'name': 'uniEFD4', "value": "8", "hex": ""},
{'name': 'uniF19A', "value": "3", "hex": ""},
{'name': 'uniF57B', "value": "1", "hex": ""},
{'name': 'uniF593', "value": "4", "hex": ""}]}
data_list = base_font["font"]
# print( data_list)
# [{'name': 'uniE339', 'value': '6', 'hex': ''}, {'name': 'uniE624', 'value': '9', 'hex': ''},...
# 遍历字典并填充数据
for n in data_list:
w = n["name"]
# 需要注释font.saveXML,否则报错没有data属性
# content得到的是bytes型的数据,而且数据量很长,所以使用哈希md5处理
content = font["glyf"].glyphs.get(w).data
glyph = hashlib.md5(content).hexdigest()
n["hex"] = glyph
# print(base_font["font"])
# [{'name': 'uniE339', 'value': '6', 'hex': '0833d3b4f61f02258217421b4e4bde24'},...
# print(base_font) # 这个是最终的字典 name是字体文件,value是网页映射值,hex是字形数据
# {'font': [{'name': 'uniE339', 'value': '6', 'hex': '0833d3b4f61f02258217421b4e4bde24'},...
# 第五步:爬取数据自动化,熟悉来前四步,最后一步就是水到渠成
# 请求网页源数据
url = "http://www.porters.vip/confusion/movie.html"
resp = requests.get(url=url)
sel = Selector(resp.text)
# 让程序自动提取页面加载的所有css文件路径
css_path = sel.css("link[rel=stylesheet]::attr(href)").extract()
# print(css_path)
# ['https://cdn.jsdelivr.net/npm/bootstrap@3.3.7/dist/css/bootstrap.min.css', './css/movie.css']
# 遍历获取到的css链接
woffs = []
for c in css_path:
# 拼接正确的css文件路径
css_url = parse.urljoin(url, c)
# print(css_url)
# https://cdn.jsdelivr.net/npm/bootstrap@3.3.7/dist/css/bootstrap.min.css
# http://www.porters.vip/confusion/css/movie.css
# 向css文件发起请求,然后使用正则获取字体文件路径
css_resp = requests.get(url=css_url)
# print(css_resp.text)
# 其中一段数据为:这个正式网页加载的字体文件路径,但是需要用正则表达式把路径找出来
# @font-face {
# font-family: stonefont;
# src:url('../font/movie.woff') format('woff');
# }
# 匹配css文件中的woff文件路径
woff_path = re.findall(r"src:url\('..(.*.woff)'\) format\('woff'\);", css_resp.text)
if woff_path:
# print(woff_path) # ['/font/movie.woff']
# 如果匹配到数据则添加到woffs列表中
woffs += woff_path # 结果为['/font/movie.woff']
# woffs.append(woff_path) # 结果为[['/font/movie.woff']]
# 拼接字体文件的链接 pop()从列表中删除一个元素并返回该元素
woff_url = "http://www.porters.vip/confusion" + woffs.pop()
# 请求字体文件
woff = requests.get(woff_url)
filename = "target.woff"
# file_path = os.path.dirname(os.path.abspath(__file__))
file_path = os.path.dirname(__file__)
# print(os.path.dirname(__file__)) # D:/gcw/learn_crawler
# print(os.path.abspath(__file__)) # D:\gcw\learn_crawler\字体反爬.py
# print(file_path) # D:\gcw\learn_crawler
# os.path.abspath(__file__) 获取当前文件所在的路径
# os.path.dirname 当前文件目录名,绝对路径
with open(file_path + "/" + filename, "wb") as f:
# 将字体文件保存到本地
f.write(woff.content)
# 使用TTFont库打开刚才下载的文件
font = TTFont(file=file_path + "/" + filename)
# 因为TTFont可以直接读取woff文件的结构,所以不需要将woff保存为XML文件,
# 接着以用户平分9.7对应的编码.测试,在原来的代码中引入基准字体数据base_font
web_code = "."
# 编码文字转换
woff_code = [i.upper().replace("&#X", "uni") for i in web_code.split(".")]
# print(woff_code) # ['uniE624', 'uniE9C7']
result = []
for w in woff_code:
# 从字体中取出对应编码的字形信息 glyf是字形数据
content = font["glyf"].glyphs.get(w).data
# # 字形信息MD5
glyph = hashlib.md5(content).hexdigest()
for b in base_font.get("font"):
# 与基准字形中的MD5值进行对比,如果相同则取出该字形描述的文字
if b.get("hex") == glyph:
result.append(b.get("value"))
break
# print(result) # ['9', '7']

















 1235
1235

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









