



没错,这是一个可以抓取网页内容变成markdown文件的工具。
是给大模型构建知识库的一把好手。
它能够抓取单个网页,还能够根据关键词抓取搜索结果网页中的内容。
公众号算法美食屋后台回复关键词:源码,获取本文notebook源码。
核心代码逻辑:

〇,WEB体验
可以在这个工具的网址直接用github账号登录注册使用。
https://www.firecrawl.dev/app/playground
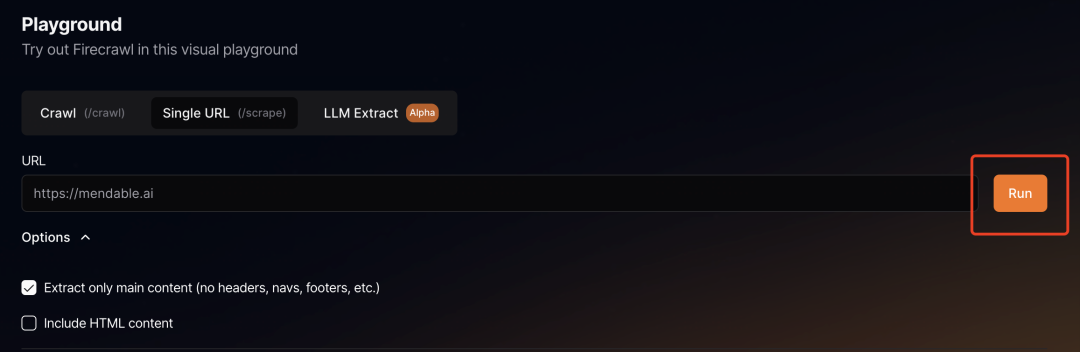
在这个playground页面,丢进去你想抓取的url就可以抓取并下载结果。
每个月每个账号可以免费抓取500个网页页面。
如果你想要更多,很简单,给这个产品打钱 或者 注册多个账号(逃)~
此外,这个产品也是开源的,你也可以在本地部署一套。
二,Python抓取单网页
首先在这个页面获取api_key
https://www.firecrawl.dev/app/api-keys
然后安装它的Python接口库
pip install firecrawl-py使用如下代码抓取:


三,Python搜索关键词
使用如下代码根据关键词获取页面




















 2291
2291

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









