




一、引入
通用代码框架是一组代码,可以准确可靠地爬取网页上的内容。
在使用Requests库进行页面访问时,经常使用request.get(url)获取指定URL的相关内容,但并不是总能正确获取,因为网络连接有风险,这时对于这样的语句的异常处理很重要。
二、Requests库支持6种常见的连接异常
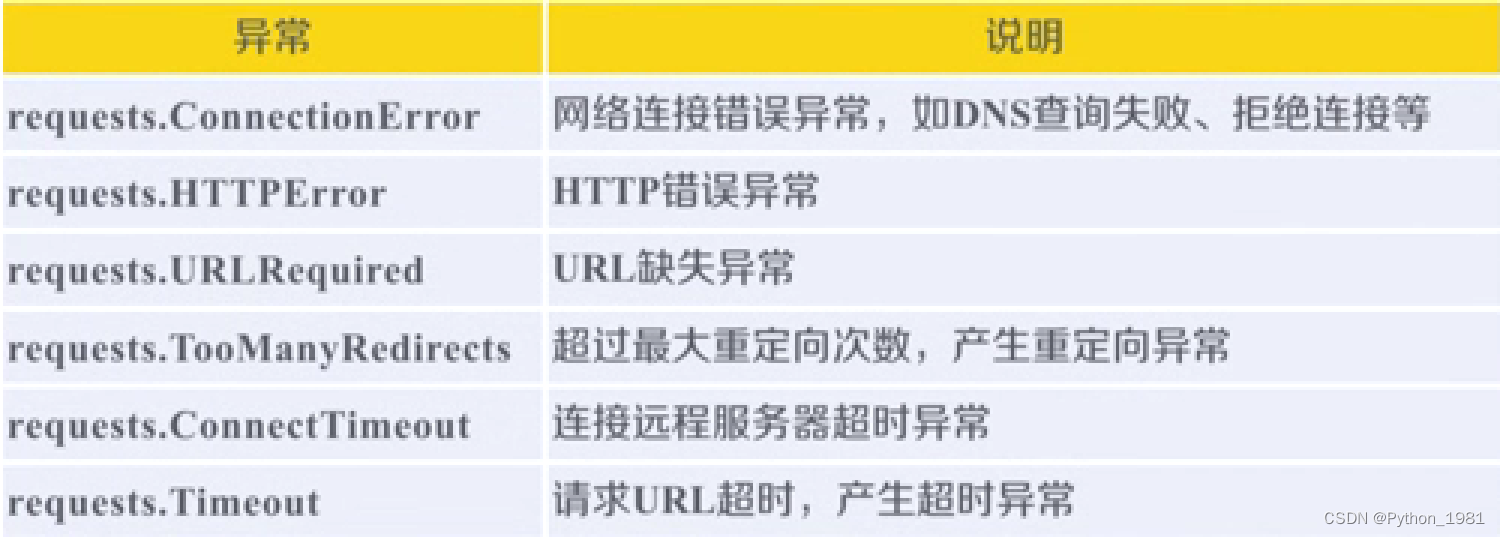
三、Response对象返回了 页面所有内容,也提供一个方法,专门与异常打交道
 r.raise_for_status(): 判断返回的Response类型的状态是不是200,200表示返回页面的内容是正确的;否则,产生HTTPError 异常
r.raise_for_status(): 判断返回的Response类型的状态是不是200,200表示返回页面的内容是正确的;否则,产生HTTPError 异常
四、爬取网页的通用代码框架

测试:

五、总结
通用代码框架使得爬取网页更稳定、更可靠。


















 6968
6968

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











