 数据驱动测试入门与实战
数据驱动测试入门与实战








一、数据驱动测试和自动化的关系:
- 不是说做自动化测试,就要用数据驱动测试。
- 做自动化测试的前提下,做数据驱动测试,是优化代码的一种方式。
-做自动化测试的初衷,是要想好自动化脚本之后的维护。
二、学习目标:
- 常见自动化测试模式
- 数据驱动测试
– 测试数据决定测试行为以及最终的结果,是测试的基本形式,常用。 - 关键字驱动测试
– 对测试代码进行高度封装,测试人员直接通过简单词汇的函数调用就可实现自动化测试。 如,将登录测试的代码封装成login方法,用到时直接调用。或者,定义测试时所用到的名字,来决定测试的行为。 - 行为驱动测试
– 高度封装的同时,加入了对自然语言的支持,使测试人员通过自然语言描述实现自动化测试,依赖框架,普及程度不高。 举例:
Feature:Search in Sogou website
in order to Search inSougou website
As a visitor
We'll search the NBA best player
# 场景:搜索NBA的一个运动员
Scenario:Search NBA player
#测试代码如下:贴近自然语言的描述,其底层是有代码的,不能随意改变自然语言表述的
Given I have the English name "<search_name>"
When I search it in Sougou website
Then I see the entire name "<search_result>"
- 数据驱动测试特点
- 减少冗余代码,便于代码维护。
- 集中管理测试数据,方便测试维护。
- 便于测试框架扩展(模块化编程思维)。
- 数据驱动测试实现
- 编程语言:puthon3.x
- 编程工具:pycharm
- 用到的第三方库:requests、ddt、xlrd、xlutils
三、环境
1、安装python
- 注意添加环境变量
2、安装pycharm
3、安装第三方的库
- 3.1 安装ddt(data driver test)
– Python语言数据驱动测试用的库。
- 3.2 安装requests库
– 做接口自动化测试的库。
- 3.3 安装xlrd库
– 读excel文件的库
- 3.4 安装xlutils
– 向已存在的excel文件中追加内容的库。




四、创建工程编写代码
1、创建工程-选择解释器
解释器决定了下载的插件能不能用

也可以在项目建立后,确认解释器是否选择,如图:

2、写代码
-
demo_基本的代码.py
-- 缺陷:维护起来成本高,耗时耗力
import requests # 导入接口自动化的库
# 接口的地址
url = "http://172.31.191.129:8080/opencart/index.php?route=account/login"
# 入参,格式一般是字典
data = {
"email":"admin@admin.com",
"password":"123456"
}
# 发送请求
re = requests.post(url=url,data=data)
#print(re) # 打印结果:<Response [200]>,尖括号代表这是一个对象,其含义不只一个200,还有很多内容的
#print(re.text) # 查看响应的文本。
result = "注销退出" in re.text # 注销退出,作为一个断言
print(result)
# 密码错误
data = {
"email":"admin@admin.com",
"password":"12345"
}
re = requests.post(url=url,data=data)
result = "邮箱地址/电话号码或密码不匹配。" in re.text
print(result) # 打印结果:True
# 账号错误
data = {
"email":"admin@admin.co",
"password":"123456"
}
re = requests.post(url=url,data=data)
result = "邮箱地址/电话号码或密码不匹配。" in re.text
print(result) # 打印结果:True
# 密码为空
data = {
"email":"admin@admin.com",
"password":""
}
re = requests.post(url=url,data=data)
result = "邮箱地址/电话号码或密码不匹配。" in re.text
print(result) # 打印结果:True
# 账号为空
data = {
"email":"",
"password":"123456"
}
re = requests.post(url=url,data=data)
result = "邮箱地址/电话号码或密码不匹配。" in re.text
print(result) # 打印结果:False→原因是此功能在“账号为空、密码正确”时也能登录成功,是一个bug
# 账号,密码都为空
data = {
"email":"",
"password":""
}
re = requests.post(url=url,data=data)
result = "邮箱地址/电话号码或密码不匹配。" in re.text
print(result) # 打印结果:True
进阶:
-
demo2_基于unittest框架的简单数据驱动.py
-- 缺陷:不适合大数据量的测试,否则通篇都是数据
# 导入测试框架unittest(pytest比unittest更灵活、功能更强大)
# 测试框架,存在的意义:可以更加方便的管理测试代码。
import unittest
# 从ddt(data driver test)包导入相应内容
from ddt import ddt,data,unpack
import requests
# 加 @ddt 表示当前测试类要进行数据驱动测试,不加 @ddt 就没办法进行数据驱动测试了
@ddt
# 步骤1:
# 定义测试类,测试类要继承自unittest.TestCase类
# 定义的测试类Demo名,是自定义的
class Demo(unittest.TestCase):
# 步骤4:
# @data 表示当前这条测试用例需要用到的测试数据。
# @data([第一组数据],[第二组数据],[第三组数据],[第四组数据],[第五组数据]),入参和预期结果组成一组数据
# @data后面有几组测试数据,它对应的测试用例,就会循环执行多少次,每次取新的数据。
@data([{"email": "admin@admin.com","password": "123456"},"注销退出"],
[{"email": "admin@admin.com","password": "12345"},"邮箱地址/电话号码或密码不匹配。"],
[{"email": "admin@admin.co","password": "123456"},"邮箱地址/电话号码或密码不匹配。"],
[{"email": "admin@admin.com","password": ""},"邮箱地址/电话号码或密码不匹配。"],
[{"email": "","password": "123456"},"邮箱地址/电话号码或密码不匹配。"],
[{"email": "","password": ""},"邮箱地址/电话号码或密码不匹配。"])
# 要进行数据驱动,我们就要为测试用例定义形式参数,形参的个数要与每组测试数据中的元素个数一致。
# 执行测试的时候,测试数据会自动传递给对应的形式参数
# 步骤6:
# 将一组数据(列表,元组)拆分成单个元素,然后一一对应传递给形式参数。只拆分一次。
# 缺少@unpack的话,如此案例中,每组列表数据包含有入参和预期结果(多个值),不拆分这两个,会将它们全部传递给第一个形参,即value,进行传递(默认以逗号作为传递标准)。不符合要求,且会报错。
@unpack #步骤2:定义方法中的内容,可以先将“demo_基本的代码.py”中的这部分粘过来
# unittest框架中的测试用例方法,应该以test开头,后面的为自定义名。
def test_01_demo(self,value,pre_result): # 步骤5:数据的传递,方法中传参,定义形式参数。变量的个数取决于每组数据里元素的个数,有2个值,就定义2个形参
url = "http://172.31.191.129:8080/opencart/index.php?route=account/login"
# 步骤3:
# 让测试用例只有一条,但测试数据data不断变化,预期结果随之变化,去实现数据驱动,需要用到@data。删除此处的data
re = requests.post(url=url, data=value) # 步骤6:此处的变量value,作为数据内容,赋值给data
result = pre_result in re.text # 步骤6:此处的预期结果,换为形参pre_result
print(result)
# 打印结果:True True True True False True
if __name__=="__main__":
unittest.main()
进阶:
- demo3_将数据保存在文件中.py
步骤:
1. 本地新建.xls文件(新版本不支持.xlsx,需另存为.xls)
2. 一组一行的格式,准备测试数据,如data.xls:

3. 写一个能读取excel的文件excel_utils.py
# 步骤2:导入读excel的库xlrd
import xlrd
import os
# 步骤1:定义一个函数get_excel_data
def get_excel_data():
# 用xrld打开指定路径下的excel文件
wb = xlrd.open_workbook("data.xls")
# 选择excel下面相应的标签(告诉计算机选择的excel里的标签页)
sheet = wb.sheet_by_name("Sheet1")
# 动态获取当前标签页中数据一共多少行
num = sheet.nrows # sheet.row_values()是读取指定行的内容,如sheet.row_values(0),读取第一行的内容
# 步骤3:循环获取当前页签中所有的数据
# 定义一个空列表,用来装所有的测试数据。
row_data = [] # 空列表,用来装新数据
for i in range(0,num): # 序号:0至num
# 获取指定行号的数据
data = sheet.row_values(i)
# 将字符串类型的字典,转换成它本身的样子(字典)。
# 不转换的话,会将每一行数据都变成列表转换出来,字典多加了引号,与数据源要求不一致
data[0] = eval(data[0])
# 将取到的每行数据添加到列表中
row_data.append(data)
print(row_data) # 打印转换后的row_data
# 打印结果:一个二位列表:[[第一行],[第二行],[第三行],[第四行],[第五行]]
return row_data
# 如果代码不想让别人执行,就可以把其放在if __name__=="__main__"下面
if __name__=="__main__":
get_excel_data()

4. 调试:demo3_将数据保存在文件中.py
# 步骤1:可以先把“demo2_基于unittest框架的简单数据驱动.py”中的代码拷贝过来
import unittest
from ddt import ddt,data,unpack
import requests
# 步骤3:
# 导入写好的excel_utils.py中的get_excel_data方法(函数)
from excel_utils import get_excel_data
@ddt
class Demo(unittest.TestCase):
# 步骤6:理解下述内容
# get_excel_data() 相当于 [[第一行],[第二行],[第三行],[第四行],[第五行]]这个二位列表
# @unpack 解包后 相当于 [第一行],[第二行],[第三行],[第四行],[第五行],不能直接使用,参考demo2_基于unittest框架的简单数据驱动.py
# 所以需要再次解包
# *get_excel_data() 调用函数时,函数名前加*,表示对结果进行一次解包。
# 配合@unpack 就可以进行两次解包
@data(*get_excel_data()) # 步骤2:因为有excel数据,此处data中的数据删除变为@data();步骤4:将excel数据传入
@unpack
def test_01_demo(self,value,pre_result):
url = "http://172.31.191.129:8080/opencart/index.php?route=account/login"
re = requests.post(url=url, data=value)
result = pre_result in re.text
print(result) # 打印结果:True True True True False True
if __name__=="__main__":
unittest.main()
# 这种类型也适用于selenium的表单类测试,不同的表单创建不同的标签
进阶:
- demo4_从excel中读取所有数据.py
(更偏向于关键字驱动)
步骤:
1. 本地新建.xls文件(新版本不支持.xlsx,需另存为.xls)
2. 第一行标题,其他数据一组一行的格式,准备测试数据,列名根据需要自定义,如data2.xls:

其中类似id的,设置成了文本格式,以免运行时显示.00这样的数。
在excel中定义好名称的原因是,简化代码,使测试数据直接在excel中维护。
3. 写一个能读取excel的文件excel_utils.py
# 步骤2:导入读excel的库xlrd
import xlrd
from xlutils import copy
import os
# 步骤1:定义一个函数get_excel_data2
def get_excel_data2():
wb = xlrd.open_workbook("data2.xls")
sheet = wb.sheet_by_name("Sheet1")
num = sheet.nrows
row_data = []
# 因为第一行是标题内容,要跳过,所以取数据要从第2行起,即序号从1开始
for i in range(1, num):
data = sheet.row_values(i)
data[4] = eval(data[4])
row_data.append(data)
print(row_data)
return row_data
if __name__=="__main__":
get_excel_data2()
4. 调试:demo4_从excel中读取所有数据.py
import unittest
from ddt import ddt,data,unpack
import requests
from excel_utils import get_excel_data2
@ddt
class Demo(unittest.TestCase):
@data(*get_excel_data2()) # 步骤1:写入数据,形参
@unpack
def test_01_demo(self,id,name,url,type,data,pre_result,result): # 步骤2:传参。data2.excel中有多少标题,这里必须一致。如果只要一部分,需要将get_excel_data2()函数中追加列表后,定义、生成需要的一个新列表
# 步骤3:此处原先的url不需要了,删除即可。直接从文档data2.xls读即可。
re = requests.post(url=url, data=data)
result = pre_result in re.text
print(result) # 运行结果 True True True True False True
if __name__=="__main__":
unittest.main()
以上示例中只提到post请求(re = requests.post(url=url, data=data)),如果还包含get请求的数据呢?
进阶:
- demo5_用自己封装的请求自适应数据测试
步骤:
1. 本地新建.xls文件(新版本不支持.xlsx,需另存为.xls)
2. 一组一行的格式,准备测试数据,列名根据需要自定义,如data3.xls:

3. 需要将get、post请求做一定的封装,能够自适应get和post,request.py
# 步骤1:
import requests
def send_request():
requests.post()
requests.get()
# 步骤2:
import requests
def send_request(type):
if type=="post":
requests.post()
elif type=="get":
requests.get()
# 步骤3:
import requests
# 不能只传type,其他值也要传进来
def send_request(url,data,type):
if type=="post":
# post请求可以传递两种数据
requests.post(url=url,data=data) # 有时传递的data,在excel中增加一列data_type(data[字典]或json[字符串])
requests.post(url=url,json=data) # 有时传递的json
elif type=="get":
requests.get(url=url,params=data)
# 步骤4:
import requests
def send_request(url,data,data_type,type):
if type=="post":
if data_type=="data":
requests.post(url=url,data=data)
elif data_type == "json":
requests.post(url=url,json=data)
elif type=="get":
requests.get(url=url,params=data)
# 步骤5:
# 有时请求可能会带一些其他消息,如header、cookies等,可将**kwargs带上,代表接收一个字典
import requests
def send_request(url,data,data_type,type,**kwargs):
if type=="post":
if data_type=="data":
requests.post(url=url,data=data,**kwargs)
elif data_type == "json":
requests.post(url=url,json=data,**kwargs)
elif type=="get":
requests.get(url=url,params=data,**kwargs)
# 步骤6:
# 最终需要将请求的响应内容拿出去,所以要将结果返回,加return
import requests
def send_request(url,data,data_type,type,**kwargs):
if type=="post":
if data_type=="data":
return requests.post(url=url,data=data,**kwargs)
elif data_type == "json":
return requests.post(url=url,json=data,**kwargs)
elif type=="get":
return requests.get(url=url,params=data,**kwargs)
4. 写一个能读取excel的文件excel_utils.py
import xlrd
import xlutils
def get_excel_data3():
wb = xlrd.open_workbook("data3.xls")
sheet = wb.sheet_by_name("Sheet1")
num = sheet.nrows
row_data = []
# 因为第一行是标题内容,要跳过,所以序号从1开始
for i in range(1, num):
data = sheet.row_values(i)
data[5] = eval(data[5])
row_data.append(data)
print(row_data)
return row_data
5. demo5_用自己封装的请求自适应数据测试.py
import unittest
from ddt import ddt,data,unpack
import requests
from excel_utils import get_excel_data3
from request import send_request
@ddt
class Demo(unittest.TestCase):
@data(*get_excel_data3())
@unpack
def test_01_demo(self,id,name,url,type,data_type,data,pre_result,result):
# 不用之前的re = requests.post(url=url,data=data),用自己封装的请求调用
re = send_request(url=url,type=type,data_type=data_type,data=data)
result = pre_result in re.text
print(result) # 打印结果:True True True True False True
if __name__=="__main__":
unittest.main()
6. 以上代码执行后,excel中最后一列result为空,需要在excel_utils中多一个写测试数据的动作:
import xlrd
from xlutils import copy
import os
def get_excel_data3():
wb = xlrd.open_workbook("data3.xls")
sheet = wb.sheet_by_name("Sheet1")
num = sheet.nrows
row_data = []
# 因为第一行是标题内容,要跳过,所以序号从1开始
for i in range(1, num):
data = sheet.row_values(i)
data[5] = eval(data[5])
row_data.append(data)
print(row_data)
return row_data
# 将最终的测试结果数据,写入excel中。思路:最终结果出来后,复制一份原始的excel文件,写入全部数据后,删除旧的excel表
def write_result(id,result):
# 打开原始数据文件
books = xlrd.open_workbook("data3.xls")
# 复制数据的副本
wb = copy.copy(books)
# 选第一个标签页
sheet = wb.get_sheet(0)
# 测试数据应该与原始行一一对应,所以前面的id(文本格式)作用就体现出来了
# 把文件中字符串格式的id转换成整数
id = eval(id)
# 向指定坐标的单元格写入测试数据。
sheet.write(id,7,result) # id:行;7:列
# 移除原始文件(操作之前,最好备份一份原始测试数据)
os.remove("data3.xls")
# 保存新文件
wb.save("data3.xls")
# 如果代码不想让别人执行,就可以把其放在if __name__=="__main__"下面
if __name__=="__main__":
get_excel_data2()
7. demo6_测试完毕将结果写入到文件中.py,运行后可查看新的data3.xls文件中result列的更新效果。(这种写法不会把错误日志写进来,如果需要,可以结合生成.html格式的测试报告。)
import unittest
from ddt import ddt,data,unpack
from excel_utils import get_excel_data3
from request import send_request
# 步骤1:导入自写模块的函数
from excel_utils import write_result
@ddt
class Demo(unittest.TestCase):
@data(*get_excel_data3())
@unpack
def test_01_demo(self,id,name,url,type,data_type,data,pre_result,result):
re = send_request(url=url,type=type,data_type=data_type,data=data)
result = pre_result in re.text
write_result(id=id,result=result)
if __name__=="__main__":
unittest.main()
*如果有的接口需要其他接口返回的数据,比如需要的是前一个接口的token、cookies等,
*思路如下:
*把所有的需要的上一接口的数据,单独放到一个sheet页里,如果需要用到某些请求的这些数据,在上一个sheet里添加判断。举例如下:
*需要上一接口产生的特定数据的,填Y,不需要的填N。如:get-header、set-header。
*值为Y的时候,则向指定的sheet页中写入header值。


本次举例测试项目结构:

这两年,IT行业面临经济周期波动与AI产业结构调整的双重压力,确实有很多运维与网络工程师因企业缩编或技术迭代而暂时失业。
很多人都在提运维网工失业后就只能去跑滴滴送外卖了,但我想分享的是,对于运维人员来说,即便失业以后仍然有很多副业可以尝试。
网工/运维/测试副业方向
运维网工,千万不要再错过这些副业机会!
第一个是知识付费类副业:输出经验打造个人IP
在线教育平台讲师
操作路径:在慕课网、极客时间等平台开设《CCNA实战》《Linux运维从入门到精通》等课程,或与培训机构合作录制专题课。
收益模式:课程销售分成、企业内训。
技术博客与公众号运营
操作路径:撰写网络协议解析、故障排查案例、设备评测等深度文章,通过公众号广告、付费专栏及企业合作变现。
收益关键:每周更新2-3篇原创,结合SEO优化与社群运营。
第二个是技术类副业:深耕专业领域变现
企业网络设备配置与优化服务
操作路径:为中小型企业提供路由器、交换机、防火墙等设备的配置调试、性能优化及故障排查服务。可通过本地IT服务公司合作或自建线上接单平台获客。
收益模式:按项目收费或签订年度维护合同。
远程IT基础设施代维
操作路径:通过承接服务器监控、日志分析、备份恢复等远程代维任务。适合熟悉Zabbix、ELK等技术栈的工程师。
收益模式:按工时计费或包月服务。
网络安全顾问与渗透测试
操作路径:利用OWASP Top 10漏洞分析、Nmap/BurpSuite等工具,为企业提供漏洞扫描、渗透测试及安全加固方案。需考取CISP等认证提升资质。
收益模式:单次渗透测试报告收费;长期安全顾问年费。
比如不久前跟我一起聊天的一个粉丝,他自己之前是大四实习的时候做的运维,发现运维7*24小时待命受不了,就准备转网安,学了差不多2个月,然后开始挖漏洞,光是补天的漏洞奖励也有个四五千,他说自己每个月的房租和饭钱就够了。
为什么我会推荐你网安是运维和网工测试人员的绝佳副业&转型方向?
1.你的经验是巨大优势: 你比任何人都懂系统、网络和架构。漏洞挖掘、内网渗透、应急响应,这些核心安全能力本质上是“攻击视角下的运维”。你的运维背景不是从零开始,而是降维打击。
2.越老越吃香,规避年龄危机: 安全行业极度依赖经验。你的排查思路、风险意识和对复杂系统的理解能力,会随着项目积累而愈发珍贵,真正做到“姜还是老的辣”。
3.职业选择极其灵活: 你可以加入企业成为安全专家,可以兼职“挖洞“获取丰厚奖金,甚至可以成为自由顾问。这种多样性为你提供了前所未有的抗风险能力。
4.市场需求爆发,前景广阔: 在国家级政策的推动下,从一线城市到二三线地区,安全人才缺口正在急剧扩大。现在布局,正是抢占未来先机的黄金时刻。
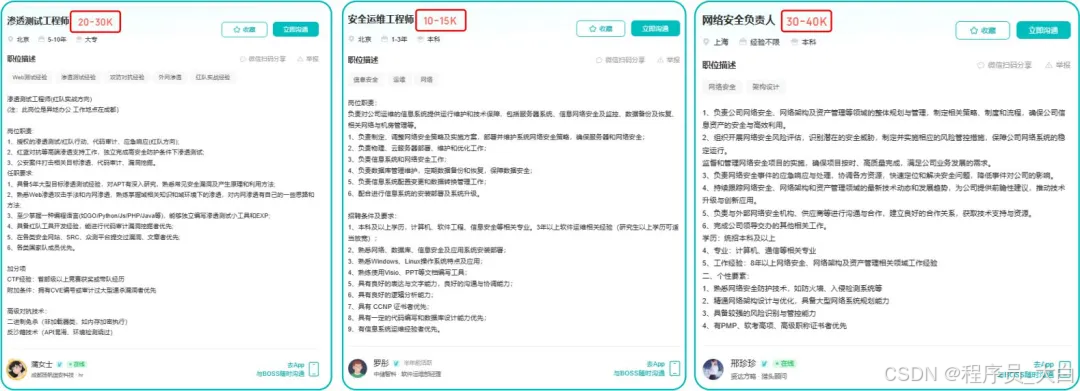
网工运维测试转行学习网络安全路线
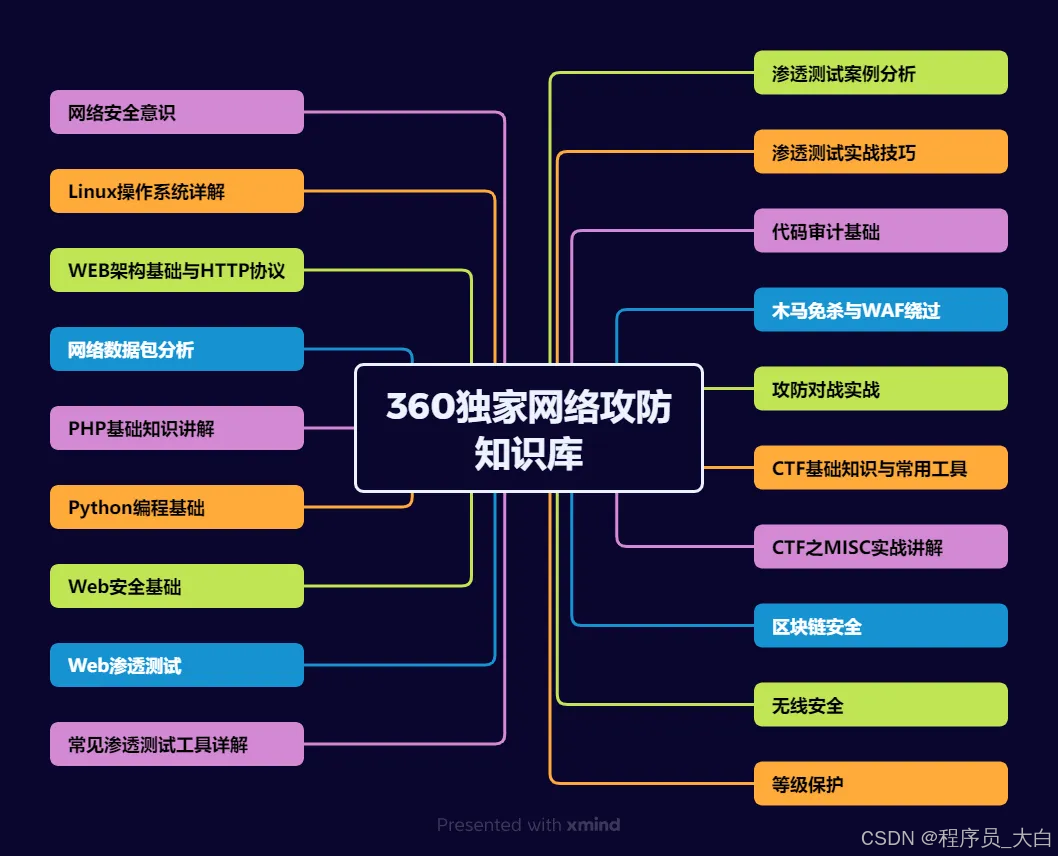
(一)第一阶段:网络安全筑基
1. 阶段目标
你已经有运维经验了,所以操作系统、网络协议这些你不是零基础。但要学安全,得重新过一遍——只不过这次我们是带着“安全视角”去学。
2. 学习内容
**操作系统强化:**你需要重点学习 Windows、Linux 操作系统安全配置,对比运维工作中常规配置与安全配置的差异,深化系统安全认知(比如说日志审计配置,为应急响应日志分析打基础)。
**网络协议深化:**结合过往网络协议应用经验,聚焦 TCP/IP 协议簇中的安全漏洞及防护机制,如 ARP 欺骗、TCP 三次握手漏洞等(为 SRC 漏扫中协议层漏洞识别铺垫)。
**Web 与数据库基础:**补充 Web 架构、HTTP 协议及 MySQL、SQL Server 等数据库安全相关知识,了解 Web 应用与数据库在网安中的作用。
**编程语言入门:**学习 Python 基础语法,掌握简单脚本编写,为后续 SRC 漏扫自动化脚本开发及应急响应工具使用打基础。
**工具实战:**集中训练抓包工具(Wireshark)、渗透测试工具(Nmap)、漏洞扫描工具(Nessus 基础版)的使用,结合模拟场景练习工具应用(掌握基础扫描逻辑,为 SRC 漏扫工具进阶做准备)。
(二)第二阶段:漏洞挖掘与 SRC 漏扫实战
1. 阶段目标
这阶段是真正开始“动手”了。信息收集、漏洞分析、工具联动,一样不能少。
熟练运用漏洞挖掘及 SRC 漏扫工具,具备独立挖掘常见漏洞及 SRC 平台漏扫实战能力,尝试通过 SRC 挖洞搞钱,不管是低危漏洞还是高危漏洞,先挖到一个。
2. 学习内容
信息收集实战:结合运维中对网络拓扑、设备信息的了解,强化基本信息收集、网络空间搜索引擎(Shodan、ZoomEye)、域名及端口信息收集技巧,针对企业级网络场景开展信息收集练习(为 SRC 漏扫目标筛选提供支撑)。
漏洞原理与分析:深入学习 SQL 注入、CSRF、文件上传等常见漏洞的原理、危害及利用方法,结合运维工作中遇到的类似问题进行关联分析(明确 SRC 漏扫重点漏洞类型)。
工具进阶与 SRC 漏扫应用:
-
系统学习 SQLMap、BurpSuite、AWVS 等工具的高级功能,开展工具联用实战训练;
-
专项学习 SRC 漏扫流程:包括 SRC 平台规则解读(如漏洞提交规范、奖励机制)、漏扫目标范围界定、漏扫策略制定(全量扫描 vs 定向扫描)、漏扫结果验证与复现;
-
实战训练:使用 AWVS+BurpSuite 组合开展 SRC 平台目标漏扫,练习 “扫描 - 验证 - 漏洞报告撰写 - 平台提交” 全流程。
SRC 实战演练:选择合适的 SRC 平台(如补天、CNVD)进行漏洞挖掘与漏扫实战,积累实战经验,尝试获取挖洞收益。
恭喜你,如果学到这里,你基本可以下班搞搞副业创收了,并且具备渗透测试工程师必备的「渗透技巧」、「溯源能力」,让你在黑客盛行的年代别背锅,工作实现升职加薪的同时也能开创副业创收!
如果你想要入坑黑客&网络安全,笔者给大家准备了一份:全网最全的网络安全资料包需要保存下方图片,微信扫码即可前往获取!
因篇幅有限,仅展示部分资料,需要点击下方链接即可前往获取
优快云大礼包:《黑客&网络安全入门&进阶学习资源包》免费分享
(三)第三阶段:渗透测试技能学习
1. 阶段目标
全面掌握渗透测试理论与实战技能,能够独立完成渗透测试项目,编写规范的渗透测试报告,具备渗透测试工程师岗位能力,为护网红蓝对抗及应急响应提供技术支撑。
2. 学习内容
渗透测试核心理论:系统学习渗透测试流程、方法论及法律法规知识,明确渗透测试边界与规范(与红蓝对抗攻击边界要求一致)。
实战技能训练:开展漏洞扫描、漏洞利用、电商系统渗透测试、内网渗透、权限提升(Windows、Linux)、代码审计等实战训练,结合运维中熟悉的系统环境设计测试场景(强化红蓝对抗攻击端技术能力)。
工具开发实践:基于 Python 编程基础,学习渗透测试工具开发技巧,开发简单的自动化测试脚本(可拓展用于 SRC 漏扫自动化及应急响应辅助工具)。
报告编写指导:学习渗透测试报告的结构与编写规范,完成多个不同场景的渗透测试报告撰写练习(与 SRC 漏洞报告、应急响应报告撰写逻辑互通)。
(四)第四阶段:企业级安全攻防(含红蓝对抗)、应急响应
1. 阶段目标
掌握企业级安全攻防、护网红蓝对抗及应急响应核心技能,考取网安行业相关证书。
2. 学习内容
护网红蓝对抗专项:
-
红蓝对抗基础:学习护网行动背景、红蓝对抗规则(攻击范围、禁止行为)、红蓝双方角色职责(红队:模拟攻击;蓝队:防御检测与应急处置);
-
红队实战技能:强化内网渗透、横向移动、权限维持、免杀攻击等高级技巧,模拟护网中常见攻击场景;
-
蓝队实战技能:学习安全设备(防火墙、IDS/IPS、WAF)联动防御配置、安全监控平台(SOC)使用、攻击行为研判与溯源方法;
-
模拟护网演练:参与团队式红蓝对抗演练,完整体验 “攻击 - 检测 - 防御 - 处置” 全流程。
应急响应专项: -
应急响应流程:学习应急响应 6 步流程(准备 - 检测 - 遏制 - 根除 - 恢复 - 总结),掌握各环节核心任务;
-
实战技能:开展操作系统入侵响应(如病毒木马清除、异常进程终止)、数据泄露应急处置、漏洞应急修补等实战训练;
-
工具应用:学习应急响应工具(如 Autoruns、Process Monitor、病毒分析工具)的使用,提升处置效率;
-
案例复盘:分析真实网络安全事件应急响应案例(如勒索病毒事件),总结处置经验。
其他企业级攻防技能:学习社工与钓鱼、CTF 夺旗赛解析等内容,结合运维中企业安全防护需求深化理解。
证书备考:针对网安行业相关证书考试内容(含红蓝对抗、应急响应考点)进行专项复习,参加模拟考试,查漏补缺。
运维网工测试转行网络攻防知识库分享
网络安全这行,不是会几个工具就能搞定的。你得有体系,懂原理,能实战。尤其是从运维转过来的,别浪费你原来的经验——你比纯新人强多了。
但也要沉得住气,别学了两天Web安全就觉得自己是黑客了。内网、域渗透、代码审计、应急响应,要学的还多着呢。
如果你真的想转,按这个路子一步步走,没问题。如果你只是好奇,我劝你再想想——这行要持续学习,挺累的,但也是真有意思。
关于如何学习网络安全,笔者也给大家整理好了全套网络安全知识库,需要的可以扫码获取!
因篇幅有限,仅展示部分资料,需要点击下方链接即可前往获取
优快云大礼包:《黑客&网络安全入门&进阶学习资源包》免费分享
1、网络安全意识
2、Linux操作系统
3、WEB架构基础与HTTP协议
4、Web渗透测试
5、渗透测试案例分享
6、渗透测试实战技巧

7、攻防对战实战
8、CTF之MISC实战讲解
关于如何学习网络安全,笔者也给大家整理好了全套网络安全知识库,需要的可以扫码获取!
因篇幅有限,仅展示部分资料,需要点击下方链接即可前往获取

















 1479
1479

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









