Python3列表模糊匹配列表
B列表模糊匹配A列表
| 1 2 3 4 5 6 7 | a = ['123','666','355']
b = ['2','5']
for i in range(len(b)):
for j in range(len(a)):
if a[j].find(b[i]) == -1:
continue
print(a[j])
|
执行结果:

Python 模糊匹配搜索问题
利用python库:fuzzywuzzy及difflib,两个库均可实现词粒度的模糊匹配,同时可设定模糊阈值,实现关键词的提取、地址匹配、语法检查等
fuzzywuzzy
| 1 2 3 4 | pip install fuzzywuzzy
from fuzzywuzzy import process
from fuzzywuzzy import fuzz
|
fuzzy模块
(1)模糊匹配方法
ratio()——简单匹配,使用纯Levenshtein Distance进行匹配。partial_ratio()——非完全匹配,基于最佳的子串(substrings)进行匹配token_set_ratio——忽略顺序匹配,对字符串进行标记(tokenizes)并在匹配之前按字母顺序对它们进行排序 token_set_ratio——去重子集匹配,对字符串进行标记(tokenizes)并比较交集和余数
(2)实例
ratio() 简单匹配
| 1 2 3 4 5 | fuzz.ratio("河南省", "河南省")
>>> 100
fuzz.ratio("河南", "河南省")
>>> 80
|
partial_ratio() 非完全匹配
| 1 2 3 4 5 | fuzz.partial_ratio("河南省", "河南省")
>>> 100
fuzz.partial_ratio("河南", "河南省")
>>> 100
|
token_set_ratio() 忽略顺序匹配
| 1 2 3 4 5 6 7 8 9 | fuzz.ratio("西藏 自治区", "自治区 西藏")
>>> 50
fuzz.ratio('I love YOU','YOU LOVE I')
>>> 30
fuzz.token_sort_ratio("西藏 自治区", "自治区 西藏")
>>> 100
fuzz.token_sort_ratio('I love YOU','YOU LOVE I')
>>> 100
|
token_set_ratio() 去重子集匹配
| 1 2 3 4 5 6 7 8 | fuzz.ratio("西藏 西藏 自治区", "自治区 西藏")
>>> 40
fuzz.token_sort_ratio("西藏 西藏 自治区", "自治区 西藏")
>>> 80
fuzz.token_set_ratio("西藏 西藏 自治区", "自治区 西藏")
>>> 100
|
process模块
(1) extract提取多条数据
类似于爬虫中select,返回的是列表,其中会包含很多匹配的数据
| 1 2 3 4 | choices = ["河南省", "郑州市", "湖北省", "武汉市"]
process.extract("郑州", choices, limit=2)
>>> [('郑州市', 90), ('河南省', 0)]
# extract之后的数据类型是列表,即使limit=1,最后还是列表,注意和下面extractOne的区别
|
(2)extractOne提取一条数据
提取匹配度最大的结果,返回 元组 类型, 还有就是匹配度最大的结果不一定是我们想要的数据,可以通过下面的示例和两个实战应用体会一下
| 1 2 3 4 5 | process.extractOne("郑州", choices)
>>> ('郑州市', 90)
process.extractOne("北京", choices)
>>> ('湖北省', 45)
|
difflib
Difflib作为python的标准库,difflib模块提供的类和方法用来进行序列的差异化比较,它能够比对文件并生成差异结果文本或者html格式的差异化比较页面,而且支持输出可读性比较强的HTML文档
(0)get_close_matches(word, possibilities, n=3, cutoff=0.6)
| 1 2 3 4 5 6 7 | import difflib
config_list = ['中国工商银行','中国农业银行','建设银行','中国人民银行','招商证券','中国农业发展银行']
query_word = '农行'
res = difflib.get_close_matches(query_word, config_list, 1, cutoff=0.5)
print(res)
>>>['中国农业银行']
|
扩展——文件比较
(1)difflib.Differ
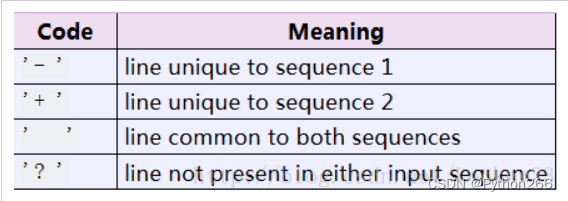
此类比较的是文本行的差异并且产生适合人类阅读的差异结果或者增量结果,结果中各部分的表示如下:
(2)difflib.HtmlDiff
| 1 2 3 | make_file(fromlines, tolines [, fromdesc][, todesc][, context][, numlines])
make_table(fromlines, tolines [, fromdesc][, todesc][, context][, numlines])
|
此类可以被用来创建HTML表格 (或者说包含表格的html文件) ,两边对应展示或者行对行的展示比对差异结果。以上两个方法都可以用来生成包含一个内容为比对结果的表格的html文件,并且部分内容会高亮显示。
(3)context_diff
| 1 | difflib.context_diff(a, b[, fromfile][, tofile][, fromfiledate][, tofiledate][, n][, lineterm])
|
比较a与b(字符串列表),并且返回一个差异文本行的生成器
| 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 | >>> s1 = ['bacon\n', 'eggs\n', 'ham\n', 'guido\n']
>>> s2 = ['python\n', 'eggy\n', 'hamster\n', 'guido\n']
>>> for line in context_diff(s1, s2, fromfile='before.py', tofile='after.py'):
... sys.stdout.write(line)
*** before.py
--- after.py
***************
*** 1,4 ****
! bacon
! eggs
! ham
guido
--- 1,4 ----
! python
! eggy
! hamster
guido
|
(4) 比对两个文件,然后生成一个展示差异结果的HTML文件
| 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 | import difflib
hd = difflib.HtmlDiff()
file1 = ''
with open('xxx1.py','r') as load:
file1 = load.readlines()
load.close()
file2 = ''
with open('xxx2', 'r') as mem:
file2 = mem.readlines()
mem.close()
with open('htmlout.html','a+') as fo:
fo.write(hd.make_file(file1,file2))
fo.close()
|
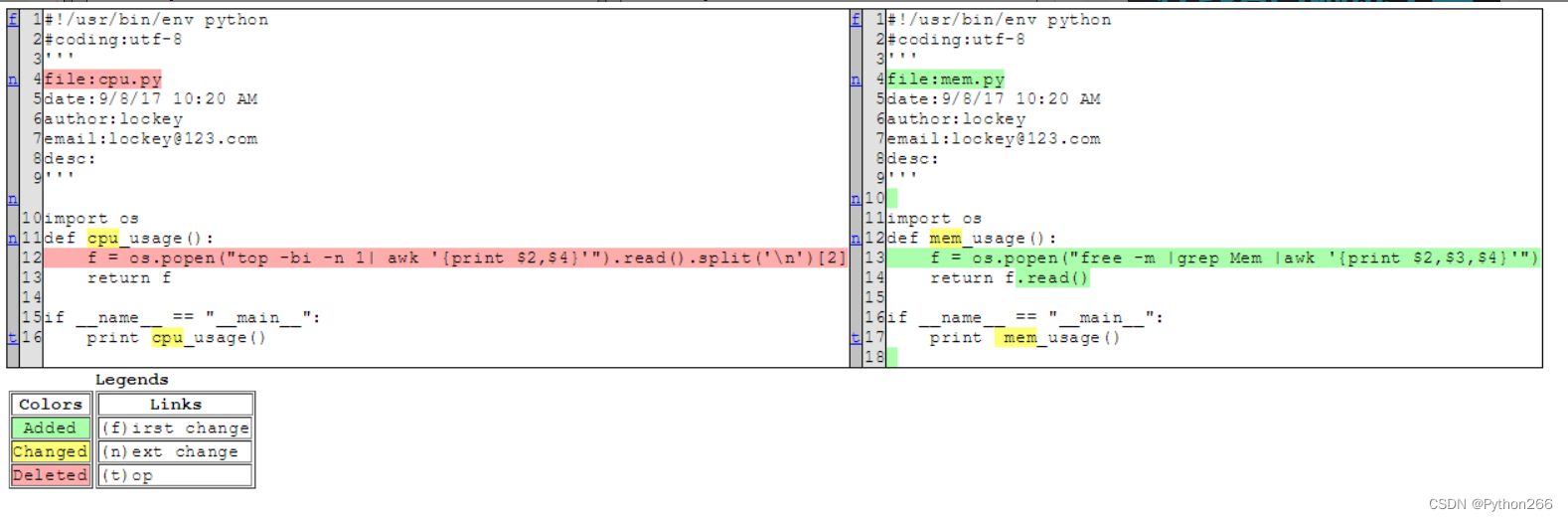
总结:difflib多用于文本的差异比较,用于模糊匹配精度还是不太准的,一般词的模糊匹配可用fuzzywuzzy




 本文介绍了Python3中实现列表模糊匹配的方法,重点讲解了fuzzywuzzy和difflib两个库。fuzzywuzzy提供ratio(), partial_ratio(), token_set_ratio(), token_sort_ratio()等方法进行不同级别的模糊匹配,而difflib则适用于序列差异比较,如get_close_matches(),Differ()和HtmlDiff()。fuzzywuzzy更适合关键词提取和地址匹配,difflib则常用于文本差异展示。"
93657213,8164716,SpringMVC数据绑定与类型转换原理详解,"['Spring框架', 'Web开发', '数据校验', '类型转换']
本文介绍了Python3中实现列表模糊匹配的方法,重点讲解了fuzzywuzzy和difflib两个库。fuzzywuzzy提供ratio(), partial_ratio(), token_set_ratio(), token_sort_ratio()等方法进行不同级别的模糊匹配,而difflib则适用于序列差异比较,如get_close_matches(),Differ()和HtmlDiff()。fuzzywuzzy更适合关键词提取和地址匹配,difflib则常用于文本差异展示。"
93657213,8164716,SpringMVC数据绑定与类型转换原理详解,"['Spring框架', 'Web开发', '数据校验', '类型转换']


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









