






作者丨程sir
https://www.jianshu.com/p/5dc68059f2dd
 #决策树简介#
#决策树简介#
决策树(Decision Tree)是一种简单但是广泛使用的分类器。通过训练数据构建决策树,可以高效的对未知的数据进行分类。
决策数有两大优点:1)决策树模型可以读性好,具有描述性,有助于人工分析;2)效率高,决策树只需要一次构建,反复使用,每一次预测的最大计算次数不超过决策树的深度。
决策树的主要算法有ID3,C4.5,CART。其中C4.5是对于ID3的优化。本周主要就是学习了ID3算法的过程,基于我自己编的一组数据:
#基础概念-信息熵#
信息是个很抽象的概念。人们常常说信息很多,或者信息较少,但却很难说清楚信息到底有多少。比如一本五十万字的中文书到底有多少信息量。
直到1948年,香农提出了“信息熵”的概念,才解决了对信息的量化度量问题。香农从热力学中借用过来的。热力学中的热熵是表示分子状态混乱程度的物理量。香农用信息熵的概念来描述信源的不确定度。
假如事件A的全概率划分是(A1,A2,...,An),每部分发生的概率是(p1,p2,...,pn),那信息熵定义为:
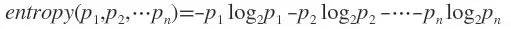
log通常以2为底数,所以信息熵的单位是bit。
#构造决策树-树根#
构造树的基本想法是随着树深度的增加,节点的熵迅速地降低。熵降低的速度越快越好,因为这样得到的树的高度最矮。让熵减小,就是说让确定性增加,也就是越来越能够做出判断。
我们的例子中,最开始如果病人的任何特征都不看,根据历史的数据,知道病人感冒的概率是1/2,过敏的概率1/6,脑震荡概率1/3。此时的熵为:
E = -(1/2)×log(1/2)-(1/6)×log(1/6)-(1/3)×log(1/3)= 1.459
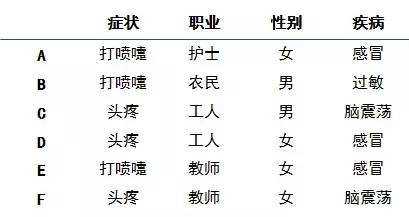
然后看特征,病人的特征有三个,症状、职业、性别,我们要选择一个作为树根,先把原始6个病人情况做成一张表:
先看症状这个特征:
症状为“打喷嚏”的有3人,2个感冒,1个过敏,因此打喷嚏时,2/3概率感冒,1/3概率过敏,0概率脑震荡,此时熵为:
-(2/3)×log(2/3)-(1/3)×log(1/3)= 0.918
症状为“头疼”的有3人,1个感冒,2个脑震荡,因此头疼时,1/3概率感冒,2/3概率脑震荡,0概率过敏,此时熵为:
-(1/3)×log(1/3)-(2/3)×log(2/3)= 0.918
从整体看,一共6个人,3个打喷嚏,3个头疼,因此,打喷嚏和头疼的概率都是1/2
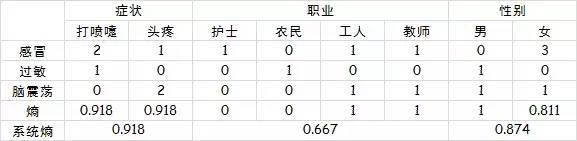
所以已知特征“症状”的情况,总系统的信息熵为0.918×1/2+0.918×1/2 = 0.918,
信息增益Gain(症状)=1.459-0.918= 0.541
再看“职业”这个特征:
职业为“护士”的有1人,1个感冒。因此职业为护士,1概率感冒,0概率其他病,熵为0
职业为“农民”的有1人,1个过敏。因此职业为农民,1概率过敏,0概率其他病,熵为0
职业为“工人”的有2人,1个感冒,1个脑震荡。因此职业为工人,1/2概率感冒,1/2概率脑震荡,0概率过敏,熵:
-(1/2)×log(1/2)-(1/2)×log(1/2)= 1
职业为“教师”的有2人,1个感冒,1个脑震荡。因此职业为教师,1/2概率感冒,1/2概率脑震荡,0概率过敏,熵:
-(1/2)×log(1/2)-(1/2)×log(1/2)= 1
从整体看,一共6个人,1护士,1农民,2工人,2教师,因此护士和农民的概率都是1/6,工人和教师概率都是1/3,所以已知特征“职业”的情况,总系统的信息熵为:
1/6 ×0 +1/6×0 +1/3×1+1/3×1=0.667,
信息增益Gain(职业)=1.459-0.667= 0.792
再看“性别”这个特征:
性别为“男”有2人,1过敏,1脑震荡,因此性别为男,1/2概率过敏,1/2概率脑震荡,0概率感冒,熵为:
-(1/2)×log(1/2)-(1/2)×log(1/2)= 1
性别为“女”有4人,3个感冒,1个脑震荡,因此性别为女,3/4概率感冒,1/4概率脑震荡,熵为:
-(3/4)×log(3/4)-(1/4)×log(1/4)= 0.811
从整体看,一共6个人,2男4女,因此男概率1/3,女概率2/3,已知性别的情况下,总系统的信息熵为
1×1/3+0.811×2/3=0.874
信息增益Gain(性别)=1.459-0.874=0.585
可见“职业”让总系统的信息熵下降的更快,决策树的根就是职业,如下图:
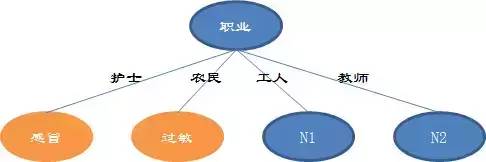
在护士和农民分支,刚才已经计算了熵为0,意味着已经没有任何不确定性了(给出的6个病人的数据也能看出来),可以直接判断病情。
#构造决策树-其他枝叶#
构造枝叶的方法和构造树根一样,只是考虑的病人的范围不同。
接下来确定N1,方法类似,现在只需要考虑职业为“工人”的这个子系统,还是列一个表:
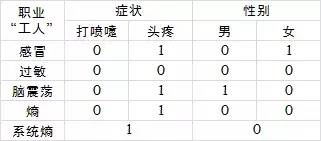
刚才已经计算过,职业为工人的系统信息熵为1
先看症状这个特征:
症状为打喷嚏的没有,熵为0
症状为头疼的有2人,1人感冒,1人脑震荡,因此“头疼工人”里,1/2概率感冒,1/2概率脑震荡,熵为:
-(1/2)×log(1/2)-(1/2)×log(1/2)= 1
总的系统信息熵为1,没有任何变化
再看性别这个特征
性别为男1人,是脑震荡,因此“男工人”里,脑震荡概率1,其他概率0,熵为0
性别为女1人,是感冒,因此“女工人”里,感冒概率1,其他概率0,熵为0
总的系统熵为0,把总系统熵一下降低为0
因此,N1就应该选择性别作为分支,然后分支的熵都为0了,也就都能确定病情了。
接下来确定N2,方法类似,现在只需要考虑职业为“教师”的这个子系统,还是列一个表:
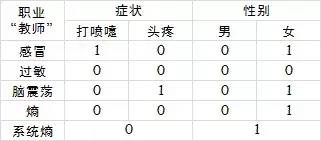
这个表和计算N1的表数值上完全类似,计算过程不再赘述,最终N2选择症状,同时系统的熵降为0
每个分支的熵都为0,总系统的熵也就为0,决策树构造完毕,最终如图:
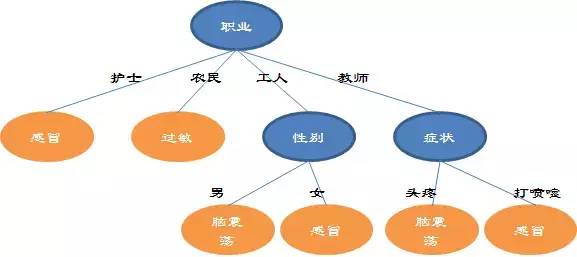
#判定规则#
决策树比较直观,好理解,关键就在于构造完成之后可以演变成一条一条的判定规则。本例中:
IF 职业为护士 THEN 感冒
IF 职业为农民 THEN 过敏
IF 职业为工人,性别为男 THEN 脑震荡
……
#其他#
构造过程中,可能发生属性用完还是没有最终判定的情况(也就是叶子节点还是有很多可能性),那么就选择最大可能性的判定作为判定(选判定结果最多的)
连续型数据的属性,ID3没法处理(个人理解也可以预先进行离散化操作,例如分段处理,然后在构造决策树)
决策树还有一个非常重要的问题是过度拟合,因为是100%按照给定的训练数据构造的树,训练数据中的噪音数据等都生成了特定的分支,应用的时候就会发生错误率很高的问题。对于决策树,必须要进行剪枝。
推荐↓↓↓

长
按
关
注
?【16个技术公众号】都在这里!
涵盖:程序员大咖、源码共读、程序员共读、数据结构与算法、黑客技术和网络安全、大数据科技、编程前端、Java、Python、Web编程开发、Android、iOS开发、Linux、数据库研发、幽默程序员等。
 万水千山总是情,点个 “
好看” 行不行
万水千山总是情,点个 “
好看” 行不行

















 792
792

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









