




 本文介绍了在深度神经网络中使用Dropout的原因和作用,旨在解决过拟合问题。Dropout通过随机让部分神经元不工作来实现正则化,防止模型过度依赖训练数据。代码展示了一个简单的应用,作者表示将在后续学习中深化理解。
本文介绍了在深度神经网络中使用Dropout的原因和作用,旨在解决过拟合问题。Dropout通过随机让部分神经元不工作来实现正则化,防止模型过度依赖训练数据。代码展示了一个简单的应用,作者表示将在后续学习中深化理解。
内心os:后期还需补代码。
一、使用原因: 当训练集不足够大时,过度学习会导致学习到的模型对本数据集几乎100%契合,但对别的符合条件的数据却无法get到。

训练深度神经网络的时候,总是会遇到两大缺点:
(1)容易过拟合
(2)费时
Dropout可以比较有效的缓解过拟合的发生,在一定程度上达到正则化的效果。
二、dropout:
其实就是让一部分神经元停止工作,避免神经网络获得的参数过多,导致结果过拟合。
三、代码:
import tensorflow as tf
from sklearn.datasets import load_digits
# from sklearn.cross_validation import train_test_split
from sklearn.preprocessing import LabelBinarizer
from sklearn.model_selection import train_test_split
# load data
digits = load_digits()
X = digits.data
y = digits.target
y = LabelBinarizer().fit_transform(y)
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=.3)
def add_layer(inputs, in_size, out_size, layer_name, activation_function=None, ):
# add one more layer and return the output of this layer
Weights = tf.Variable(tf.random_normal([in_size, out_size]))
biases = tf.Variable(tf.zeros([1, out_size]) + 0.1, )
Wx_plus_b = tf.matmul(inputs, Weights) + biases
Wx_plus_b = tf.nn.dropout(Wx_plus_b,keep_prob) #加这行~~
if activation_function is None:
outputs = Wx_plus_b
else:
outputs = activation_function(Wx_plus_b, )
tf.summary.histogram(layer_name + '/outputs', outputs)#不加这句有可能总报错
return outputs
# define placeholder for inputs to network
keep_prob = tf.placeholder(tf.float32) # 要保持多少的结果不被dropout掉(keep probablity)
xs = tf.placeholder(tf.float32, [None, 64]) # 8x8
ys = tf.placeholder(tf.float32, [None, 10])
# add output layer
l1 = add_layer(xs,64,50,'l1',activation_function=tf.nn.tanh) #100改成50,数量太多容易报错
prediction = add_layer(l1,50,10,'l2',activation_function=tf.nn.softmax)
# the loss between prediction and real data
cross_entropy = tf.reduce_mean(-tf.reduce_sum(ys * tf.log(prediction),
reduction_indices=[1])) # loss
tf.summary.scalar('loss', cross_entropy)
train_step = tf.train.GradientDescentOptimizer(0.5).minimize(cross_entropy)
sess = tf.Session()
merged = tf.summary.merge_all()
# summary writer goes in here
train_writer = tf.summary.FileWriter("logs/train",sess.graph)
test_writer = tf.summary.FileWriter("logs/test",sess.graph)
sess.run(tf.global_variables_initializer())
for i in range(500):
sess.run(train_step, feed_dict={xs: X_train, ys: y_train,keep_prob:0.5}) #50%被drop掉 若40%,则写0.6(保持60%的概率不被drop掉)
if i % 50 == 0:
# record loss
train_result = sess.run(merged,feed_dict={xs:X_train,ys:y_train,keep_prob:1})#因为记录result过程中我不要drop掉任何东西
test_result = sess.run(merged,feed_dict={xs:X_test,ys:y_test,keep_prob:0.5})
#加载到summary的FileWriter之中
train_writer.add_summary(train_result,i) #第i次学习
test_writer.add_summary(test_result,i)
效果:
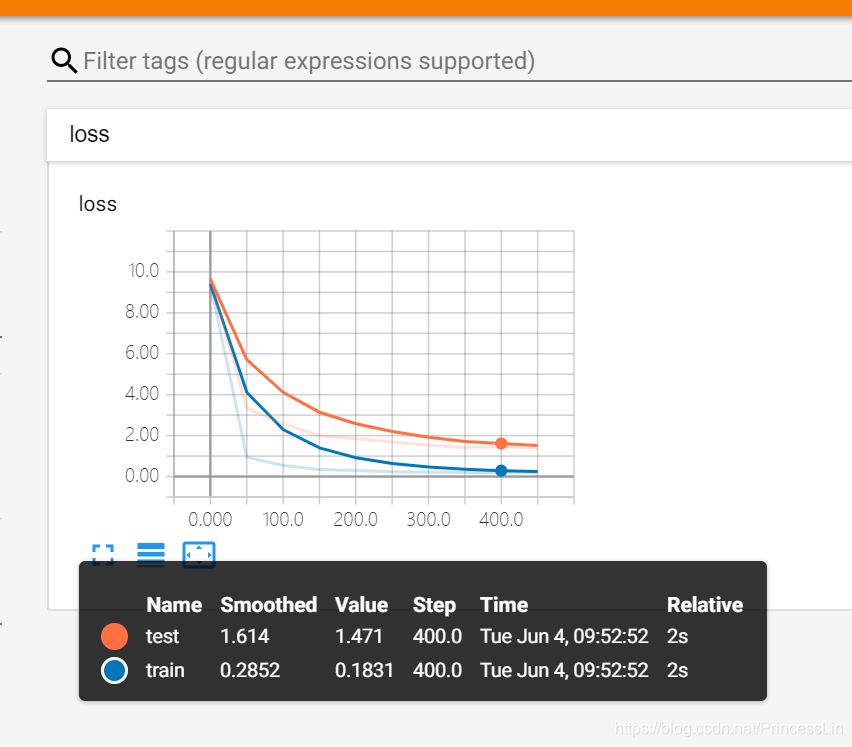
目前我还看不太懂这意味着什么,希望后期我能深入的理解。立个flag~


















 720
720

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









