






XGBoost:使用 XGBoost 来代替 SVM,它在不平衡数据集上表现通常较好。
-
类别权重调整:可以通过遍历scale_pos_weight取值为5,6,7,8,9,10来调整类别权重,从而提升少数类别(含误解)的召回率。
-
调参:使用 GridSearchCV 来调节模型的超参数,以提高性能。
import pandas as pd
import string
from sklearn.feature_extraction.text import TfidfVectorizer
from sklearn.model_selection import train_test_split, GridSearchCV
from sklearn.metrics import classification_report, ConfusionMatrixDisplay
import xgboost as xgb
import matplotlib.pyplot as plt
# Step 1: Load the dataset
file_path = '/path/to/your/train.csv' # 修改为实际文件路径
data = pd.read_csv(file_path)
# Step 2: Clean the student explanation text (remove punctuation and lower case)
def clean_text(text):
text = text.lower() # Convert to lower case
text = ''.join([char for char in text if char not in string.punctuation]) # Remove punctuation
return text
# Apply the cleaning function to the 'StudentExplanation' column
data['cleaned_explanation'] = data['StudentExplanation'].apply(clean_text)
# Step 3: Feature extraction using TF-IDF
vectorizer = TfidfVectorizer(stop_words='english', max_features=5000)
X = vectorizer.fit_transform(data['cleaned_explanation'])
# Step 4: Prepare labels (Misconception column)
# We will predict if the explanation contains a misconception or not
data['Misconception'] = data['Misconception'].fillna('No_Misconception')
# Convert labels to binary: 'No_Misconception' -> 0, any other label -> 1
y = data['Misconception'].apply(lambda x: 0 if x == 'No_Misconception' else 1)
# Step 5: Split the data into training and testing sets
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
# Step 6: Use XGBoost with class_weight='balanced' to handle the data imbalance
xgb_model = xgb.XGBClassifier(scale_pos_weight=3, random_state=42) # Adjust scale_pos_weight for imbalanced classes
# Step 7: Tune the model with GridSearchCV to find the best parameters
param_grid = {
'max_depth': [3, 6, 10],
'learning_rate': [0.01, 0.1, 0.2],
'n_estimators': [50, 100, 200]
}
grid_search = GridSearchCV(xgb_model, param_grid, scoring='f1', cv=3, verbose=1)
grid_search.fit(X_train, y_train)
# Step 8: Get the best model from the grid search
best_model = grid_search.best_estimator_
# Step 9: Make predictions
y_pred_xgb = best_model.predict(X_test)
# Step 10: Evaluate the model
print(classification_report(y_test, y_pred_xgb))
# Step 11: Plot confusion matrix
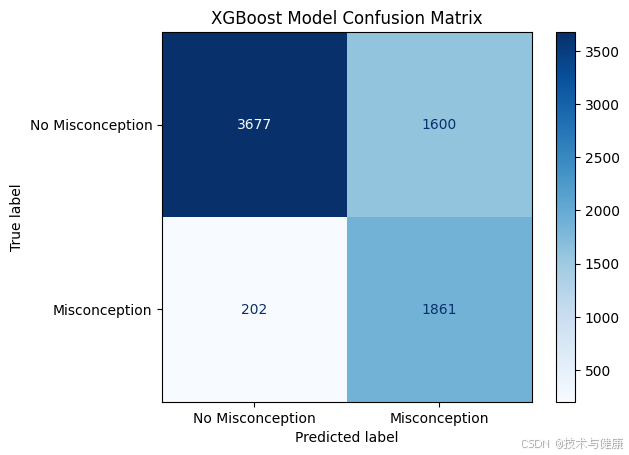
cm_xgb = confusion_matrix(y_test, y_pred_xgb)
disp = ConfusionMatrixDisplay(confusion_matrix=cm_xgb, display_labels=['No Misconception', 'Misconception'])
disp.plot(cmap=plt.cm.Blues)
plt.title('XGBoost Model Confusion Matrix')
plt.show()
Fitting 3 folds for each of 27 candidates, totalling 81 fits
precision recall f1-score support
0 0.95 0.70 0.80 5277
1 0.54 0.90 0.67 2063
accuracy 0.75 7340
macro avg 0.74 0.80 0.74 7340
weighted avg 0.83 0.75 0.77 7340



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











