




诸神缄默不语-个人优快云博文目录
诸神缄默不语的论文阅读笔记和分类
论文下载地址:https://arxiv.org/abs/2104.09864
论文标题:RoFormer: Enhanced Transformer with Rotary Position Embedding
这篇是苏神团队的工作,是做位置编码的。总之就是直接计算的是绝对位置编码,但是用在注意力机制中就能建模相对位置编码,这么一个算法。
原博文:Transformer升级之路:2、博采众长的旋转式位置编码 - 科学空间|Scientific Spaces
比较早期的博文:让研究人员绞尽脑汁的Transformer位置编码 - 科学空间|Scientific Spaces
本文提出的编码方法叫:Rotary Position Embedding(RoPE)
用RoPE的Transformer就叫RoFormer,RoFormer模型开源地址:
https://github.com/ZhuiyiTechnology/roformer
https://huggingface.co/docs/transformers/model_doc/roformer
1. 大模型位置编码问题发展史
Transformer相比RNN的优势是可以并行,相比CNN的优势是可以建模长距token间关系(多层CNN其实也可以建模,但本文说不考虑这件事先)。
但是现存的Transformer自注意力机制其实是与token位置无关的。
这里的编码是以KQV计算方式的选型来定义的,这个是通用写法:

↓ x x x是content-based encoding(我的理解是就是词向量), p p p就是位置编码
- absolute position embedding:在计算kqv的时候直接把这个位置编码加到表征上
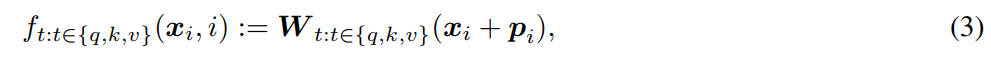
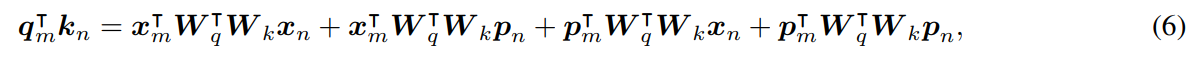
- generated absolute position encoding:直接用固定的公式生成位置编码,例如Transformer本来的位置编码。
Transformer标准的位置编码方法可以见我之前写过的Transformer原理那篇博文的对应段落:https://blog.youkuaiyun.com/PolarisRisingWar/article/details/127999367#t9 - trainable absolute position encoding
- generated absolute position encoding:直接用固定的公式生成位置编码,例如Transformer本来的位置编码。
- relative position encoding

就是这个KQV它本来就是用于token之间的自注意力,现在就直接只针对token之间的关系进行建模了,这个意思。r是m和n之间的相对距离,clip到一个范围内,也就是说如果距离太大就一概而论了。
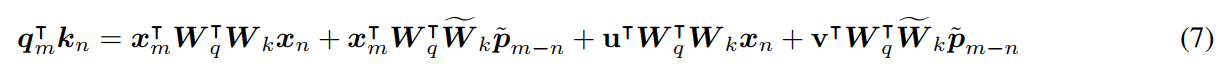
其他:
3. 神经常微分网络
4. 在复数空间建模
2. RoPE原理
用旋转矩阵(乘原始余弦表征)编码绝对位置,用自注意力机制编码相对位置。
在具体的实现上,它是想办法让绝对位置编码拥有一种能在注意力机制计算的过程中建模相对位置编码的能力。
RoPE的编码也是绝对的,不是可学的。
优势:(数学证明我懒得研究了)
- 支持任意长度序列(有更好的“外推性”)
- token间依赖随距离增加而衰减
- 相对位置编码间可以应用线性注意力
以下是我看不懂的数学上RoPE的定义:
目标是qk内积能只建模token之间的相对距离:
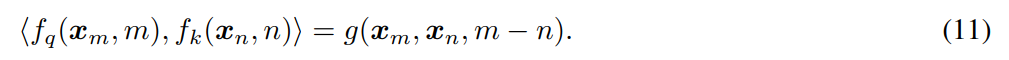
当d=2时:
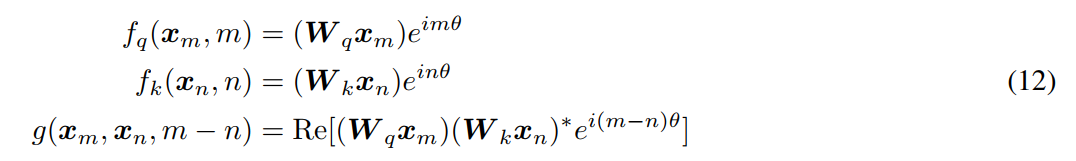
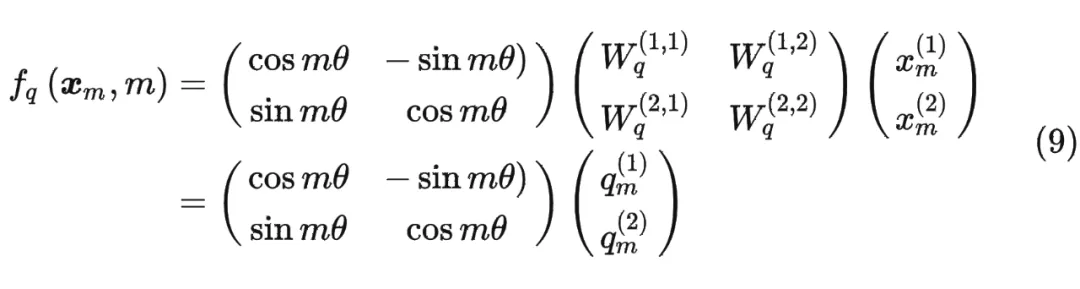
↑也就是query向量乘一个旋转矩阵
k同理,最终g(内积)就可以表示为:
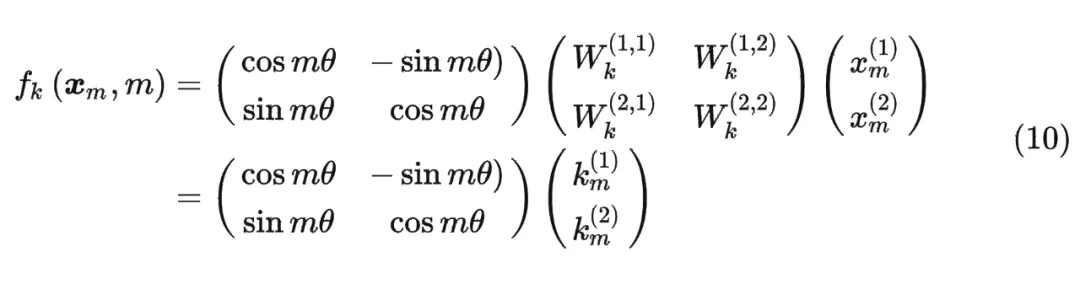
对于普遍的多维场景,分成d/2个子空间(图1的色块),根据点积的线性叠加性进行拼接:

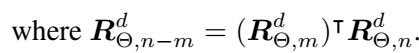
示意图:
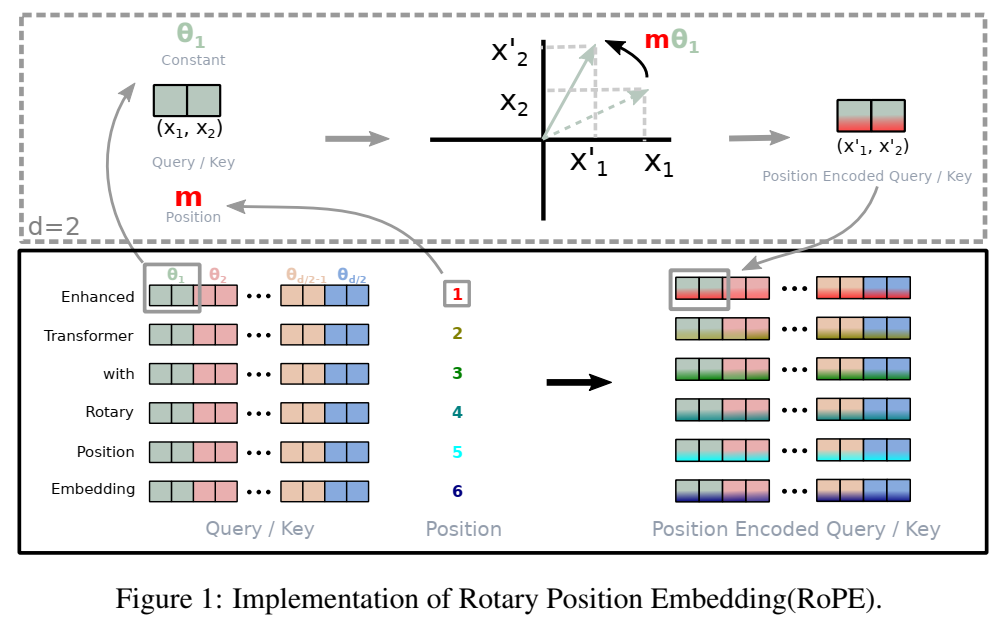
RoPE的高效计算:
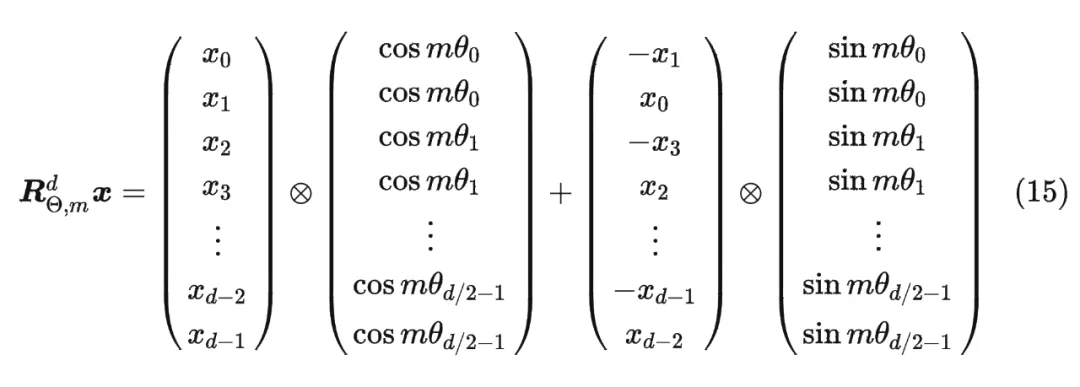
纯数学理论证明懒得看了,我靠,看不懂。
3. 实验
机器翻译任务:

预训练语言模型任务,与标准Transformer(BERT)的对比和Performer是否结合RoPE的效果对比:
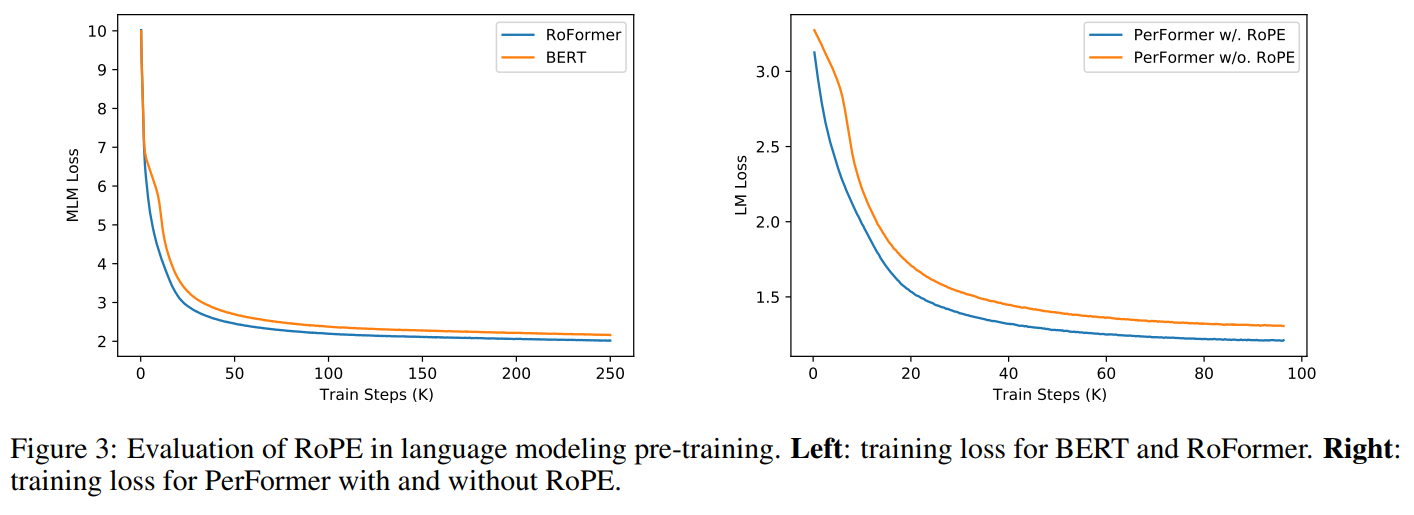
GLUE benchmark:

中文数据:
对中文数据的处理:

对中文数据的预训练:
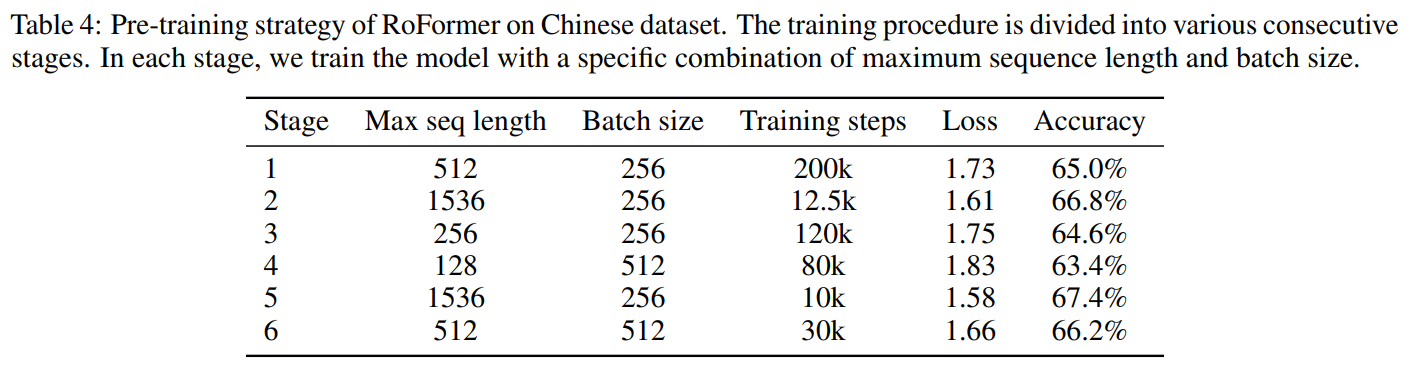
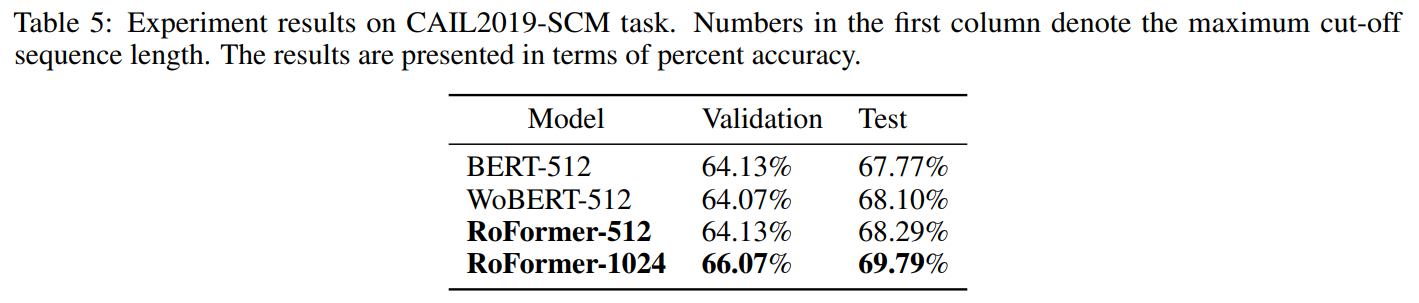
下游任务实验指标:
4. 本文撰写过程中参考的网络资料
因为数学部分比较难,我基本上都是略读,以后还有很大的重刷空间:


















 504
504

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











