




诸神缄默不语-个人技术博文与视频目录
诸神缄默不语的论文阅读笔记和分类
(这是我在3月时候写的,其实没写完,但是事已至此,我先发了,以后再补吧)
论文全名:DeepSeek-R1: Incentivizing Reasoning Capability in LLMs via Reinforcement Learning
论文下载地址:https://arxiv.org/abs/2501.12948
基模型是DeepSeek-V3,我之前也写过博文,可以参考:Re 80 读论文:DeepSeek-V3:2025年初最强大模型(几天前还是的)
可能需要注意的是DeepSeek-V3公布了训练成本,但DeepSeek-R1其实没有。
DeepSeek-R1就是拿来跟OpenAI-o1-1217打擂台的,主要用来提升推理能力的思路是强化学习和SFT。DeepSeek-R1效果好,还便宜,一出来就火了,这就是国产大模型之光的实力。
DeepSeek官方还给出了用千问和llama蒸馏的小模型版本。
1. DeepSeek-R1
3个变体:DeepSeek-R1-Zero、DeepSeek-R1 和 DeepSeek-R1-Distill
(所有模型全部开源)
开发顺序(这个算是比较清晰的,但我发现下一张更清晰):
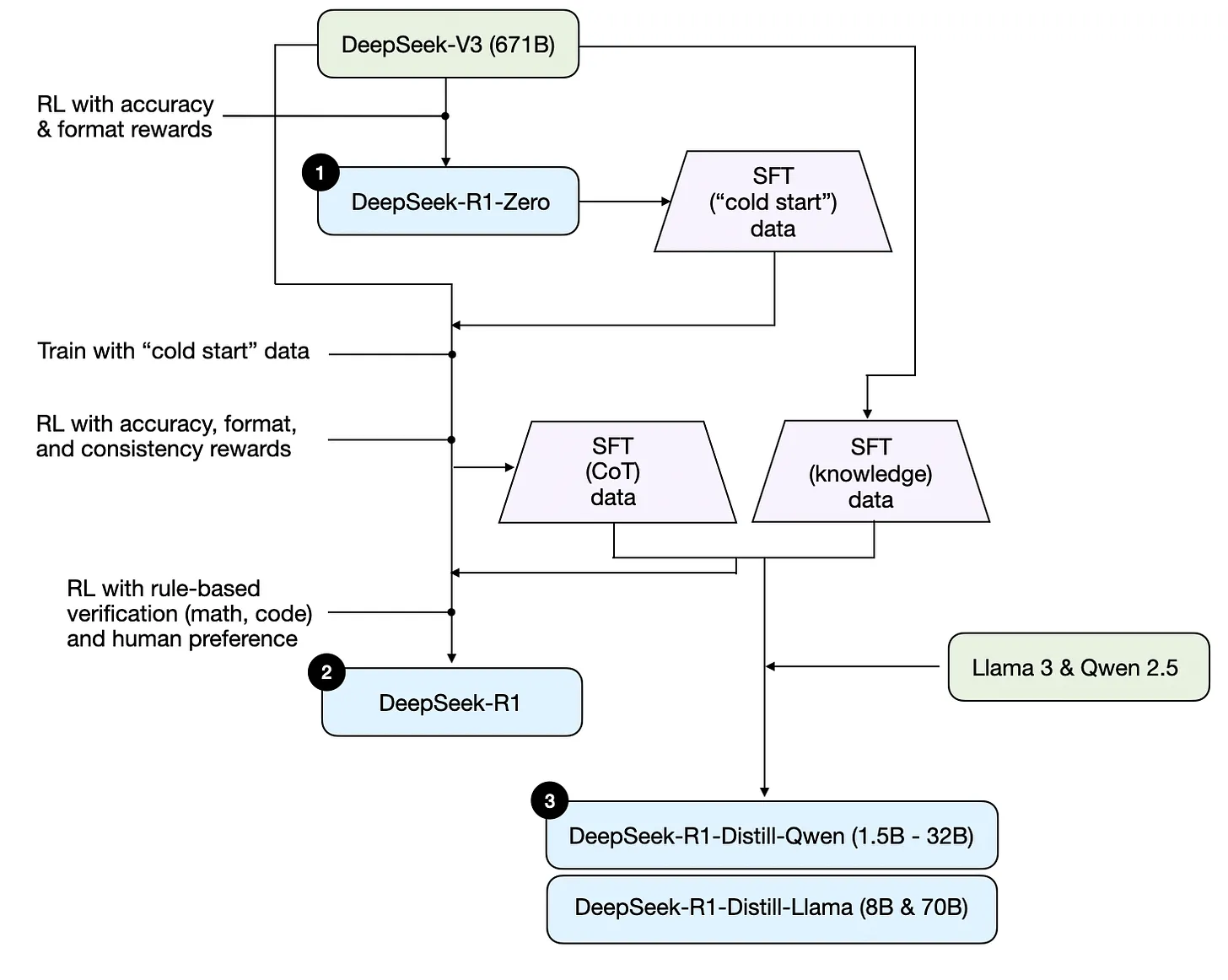
我写笔记的过程中找到一张写得更清晰的:
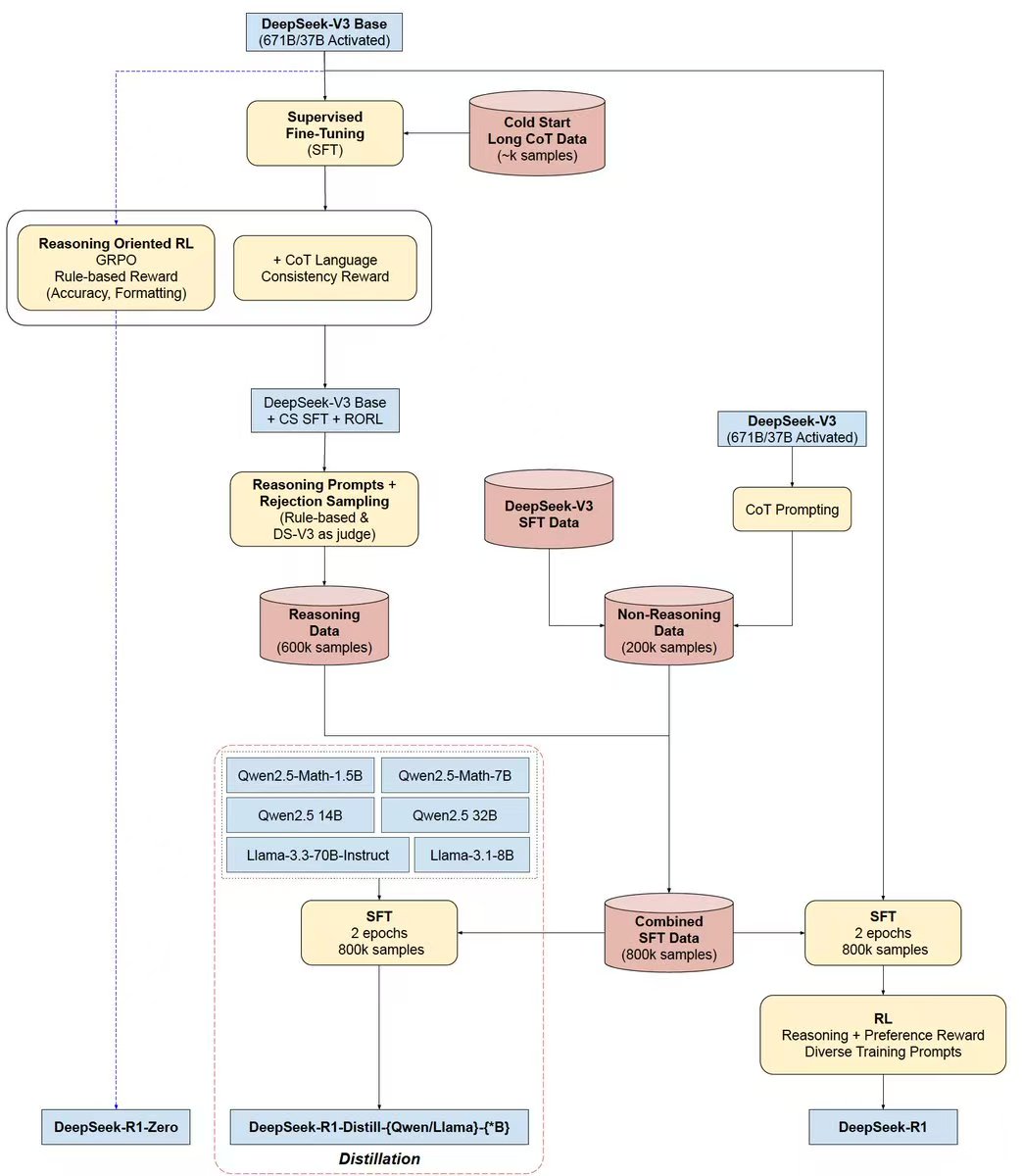
DeepSeek-R1-Zero:DeepSeek-V3 + RL(没有用SFT做指令微调)
RL奖励:准确性和输出格式
准确性用LeetCode编译器解析来判断,输出格式用一个LLM judge来判断(如在<think>标签里放置推理过程)
出现了思考行为,但会说怪话,而且会多语言混杂(语言不一致)
DeepSeek-R1:DeepSeek-V3 + SFT + RL
第一轮SFT:用DeepSeek-R1-Zero生成冷启动数据,进行指令微调。
RL增加了对语言一致性的奖励
第二轮SFT:用DeepSeek-V3和上一轮得到的DeepSeek-R1生成CoT训练数据
RL奖励:用基于规则的方法来获得数学和编码问题的准确性奖励,而人类偏好标签则用于其他问题类型。
DeepSeek-R1-Distill*:用上一阶段的SFT数据微调千问和Llama,增强其推理能力
(在LLM中的蒸馏一般指小模型用大模型的输入输出数据进行训练)
在小模型上,蒸馏比RL效果更好
(↑原论文中说是用DeepSeek-R1直接蒸馏千问和LLaMA)
1. RL框架:GRPO
2. rejection sampling
2. 实验结果
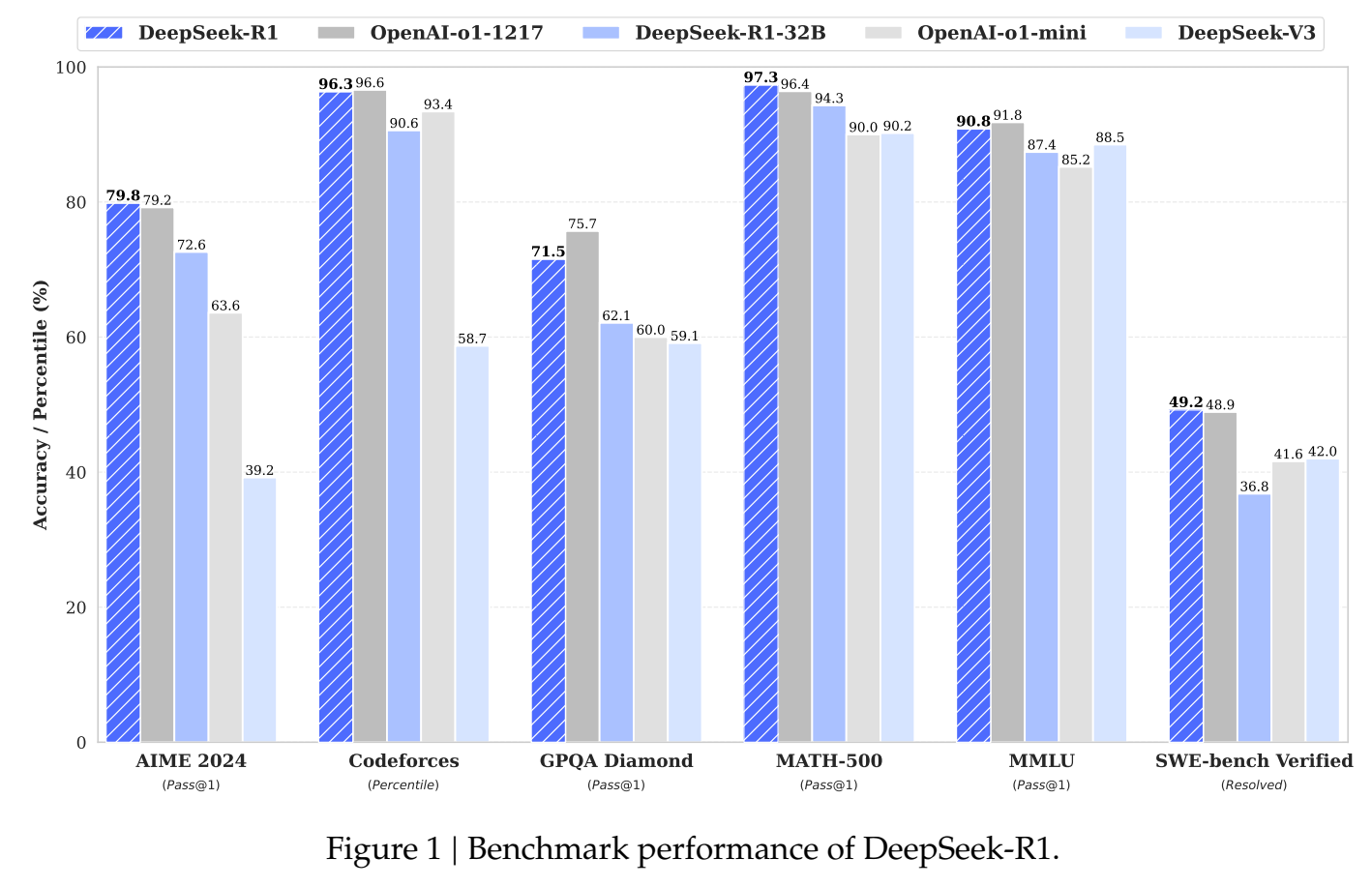
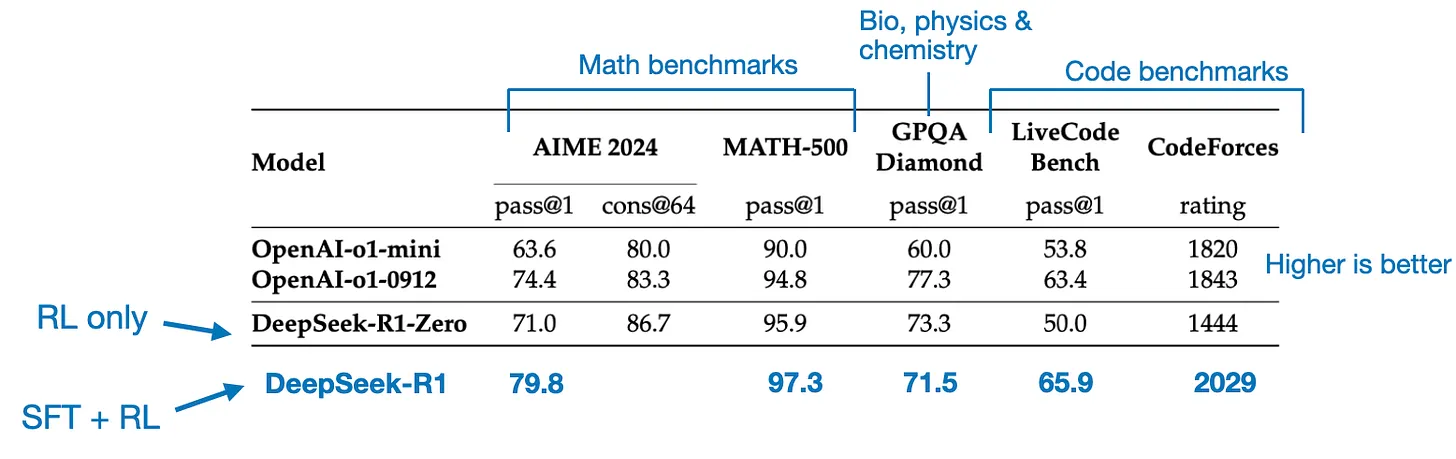
蒸馏:
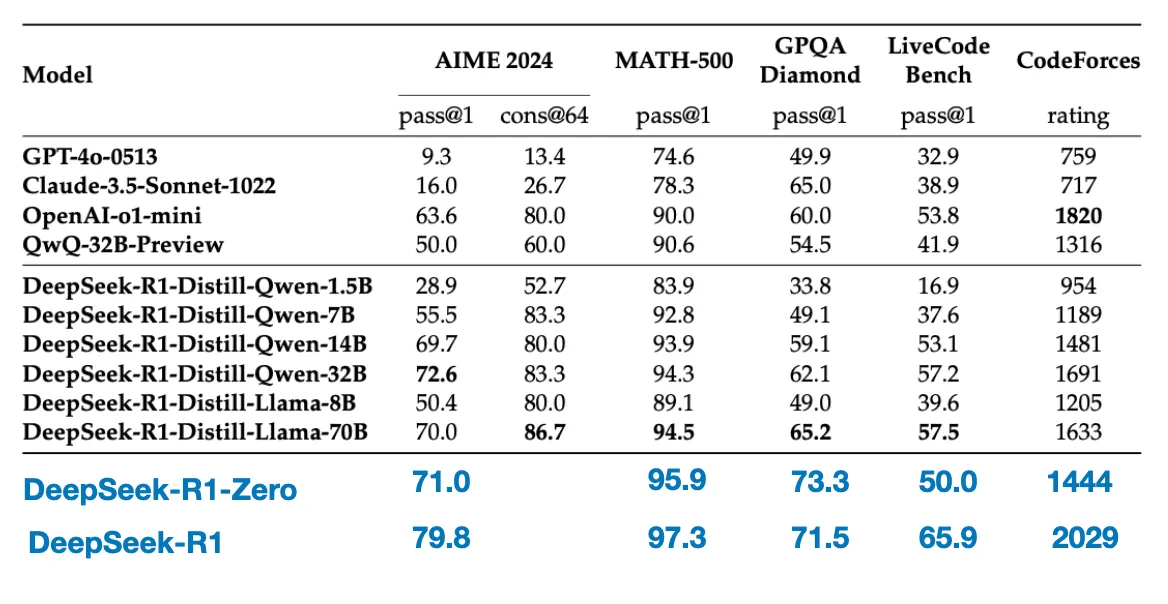
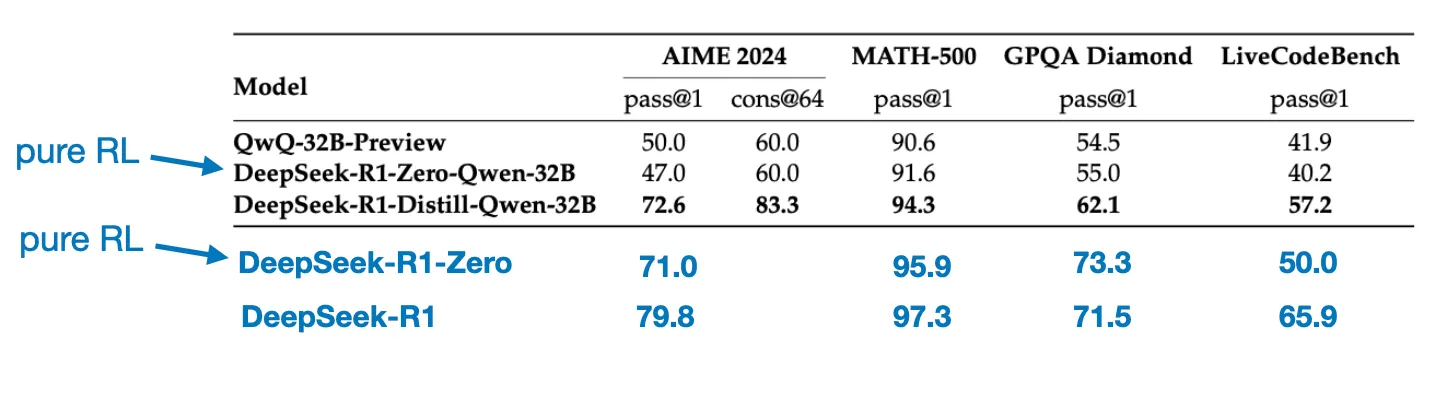
证明零样本prompt比少样本prompt效果更好、问题越简洁直白越好、prompt最好不要更换语言
3. 参考资料
- https://magazine.sebastianraschka.com/p/understanding-reasoning-llms:这篇是以DeepSeek-R1为主要示例介绍大模型推理功能实现的文章




















 5413
5413

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











