



 在开发中,遇到一个问题,即从FTP服务器下载图片到本地临时目录,然后使用AmazonS3进行存储。由于文件名可能重复,在多线程环境下导致数据不完整错误。为解决这个问题,提出了在文件名中添加时间戳或UUID以确保唯一性。然而,测试发现`java.util.UUID.randomUUID()`可能存在重复。因此,文章提供了一种基于`ThreadLocalRandom`生成无横杠的UUID的方法,以确保在多线程环境下的线程安全和无重复。
在开发中,遇到一个问题,即从FTP服务器下载图片到本地临时目录,然后使用AmazonS3进行存储。由于文件名可能重复,在多线程环境下导致数据不完整错误。为解决这个问题,提出了在文件名中添加时间戳或UUID以确保唯一性。然而,测试发现`java.util.UUID.randomUUID()`可能存在重复。因此,文章提供了一种基于`ThreadLocalRandom`生成无横杠的UUID的方法,以确保在多线程环境下的线程安全和无重复。
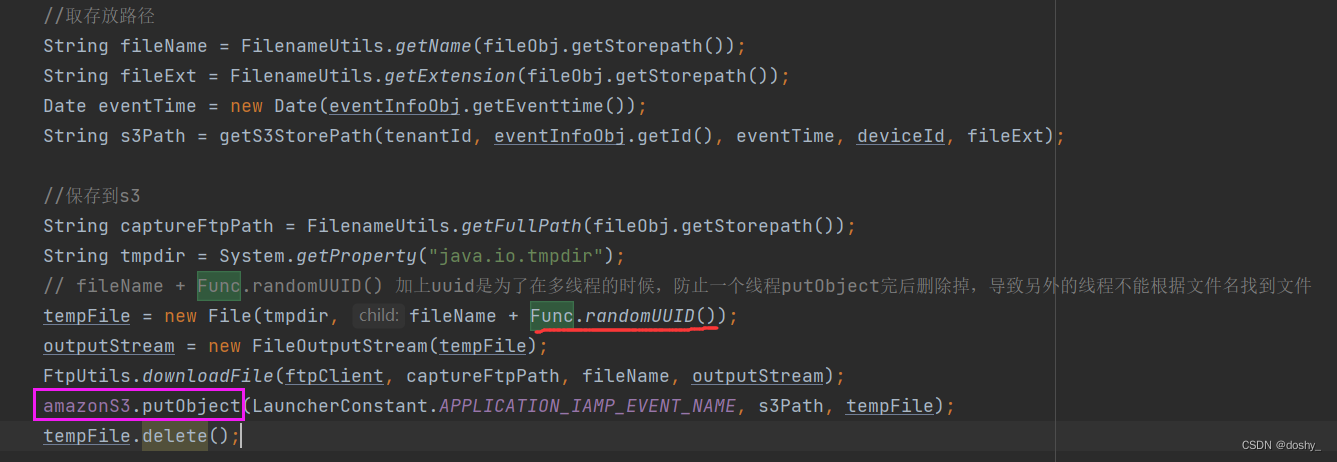
产生原因:目前开发中遇到的场景是这样的,我有一个方法a需要从公司
ftp服务器上取图片下来保存到一个临时目录。然后通过 amazonS3.putObject() 方法保存图片,保存完后从 本地的临时目录删掉。
由于文件名不是唯一,多线程的时候就会有问题,假如 x 线程 和 y 线程刚好都在操作同一个文件, x 线程存完后删除,y 线程存到一半就不行了 ,这时候就会报错 Data read has a different length than the expected,
可以理解为:amazon原本得知即将要存 1M 的数据,结果接收过来的数据只有 0.5M ,和实际大小不符合就会报错了
解决方案:
我这种情况是文件名重复导致(具体情况具体分析)。
文件名拼上时间搓或者uuid。
实际测试中多线程情况下使用java.util.UUID.randomUUID(); 会出现uuid重复,而使用 下面这段代码 的uuid不会重复
public static String randomUUID() {
ThreadLocalRandom random = ThreadLocalRandom.current();
return (new UUID(random.nextLong(), random.nextLong())).toString().replace("-", "");
}

















 1620
1620

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









