




本文是对SepLUT技术的代码讲解, 原文解读请看SepLUT文章讲解。
1、原文概要
SepLUT将原有3DLUT的功能分解为颜色无关的1DLUT和颜色相关的3DLUT实现了更高效的图像增强。整体流程如下所示。

首先采用一个轻量级的CNN来提取一个context向量,context向量生成3个1DLUT和1个3DLUT作为变换所使用的权重,最后通过高效查找和插值完成增强。整体流程是比较清晰的。
2、代码结构
代码整体结构如下:
代码基于mmedit框架构建,MMEditing 来自 OpenMMLab 项目,是基于 PyTorch 的图像和视频编辑开源工具箱。它目前包含了常见的编辑任务,比如图像修复,图像抠图,超分辨率和生成模型。与其类似的框架还有basicsr,在开发中使用事半功倍,强烈推荐。
这里就不讲解框架相关内容,主要讲解跟本文相关的核心代码。核心代码位于seplut文件夹中,如下所示:
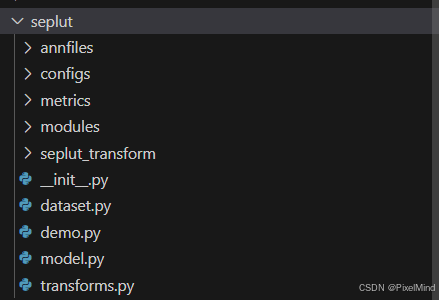
splut_transform中放着跟1DLUT和3DLUT插值相关的cpp代码实现,model.py中是最核心的部分,一些网络的子模块实现在modules文件中。
3 、核心代码模块
model.py 文件
这个文件包含了AdaInt文章中关于backbone、Weights Predictor、AdaInt模块的实现,另外还有生成采样3DLUT和一次迭代的过程。
1. SepLUT类
这里是网络的整体实现,其定义了backbone、1DLUT、3DLUT的网络以及量化的过程。
@MODELS.register_module()
class SepLUT(BaseModel):
r"""Separable Image-adaptive Lookup Tables for Real-time Image Enhancement.
Args:
n_ranks (int, optional): Number of ranks for 3D LUT (or the number of basis
LUTs). Default: 3.
n_vertices_3d (int, optional): Size of the 3D LUT. If `n_vertices_3d` <= 0,
the 3D LUT will be disabled. Default: 17.
n_vertices_1d (int, optional): Size of the 1D LUTs. If `n_vertices_1d` <= 0,
the 1D LUTs will be disabled. Default: 17.
lut1d_color_share (bool, optional): Whether to share a single 1D LUT across
three color channels. Default: False.
backbone (str, optional): Backbone architecture to use. Can be either 'light'
or 'res18'. Default: 'light'.
n_base_feats (int, optional): The channel multiplier of the backbone network.
Only used when `backbone` is 'light'. Default: 8.
pretrained (bool, optional): Whether to use ImageNet-pretrained weights.
Only used when `backbone` is 'res18'. Default: None.
n_colors (int, optional): Number of input color channels. Default: 3.
sparse_factor (float, optional): Loss weight for the sparse regularization term.
Default: 0.0001.
smooth_factor (float, optional): Loss weight for the smoothness regularization term.
Default: 0.
monotonicity_factor (float, optional): Loss weight for the monotonicaity
regularization term. Default: 10.0.
recons_loss (dict, optional): Config for pixel-wise reconstruction loss.
train_cfg (dict, optional): Config for training. Default: None.
test_cfg (dict, optional): Config for testing. Default: None.
"""
allowed_metrics = {'PSNR': psnr, 'SSIM': ssim}
# quantization_mode: (n_vertices_1d, n_vertices_3d)
allowed_quantization_modes = {(9, 9), (17, 17)}
def __init__(self,
n_ranks=3,
n_vertices_3d=17,
n_vertices_1d=17,
lut1d_color_share=False,
backbone='light',
n_base_feats=8,
pretrained=False,
n_colors=3,
sparse_factor=0.0001,
smooth_factor=0,
monotonicity_factor=0,
recons_loss=dict(type='MSELoss', loss_weight=1.0, reduction='mean'),
train_cfg=None,
test_cfg=None):
super().__init__()
assert backbone in ['light', 'res18']
assert n_vertices_3d > 0 or n_vertices_1d > 0
self.backbone = dict(
light=LightBackbone,
res18=Res18Backbone)[backbone.lower()](
pretrained=pretrained,
extra_pooling=True,
n_base_feats=n_base_feats)
if n_vertices_3d > 0:
self.lut3d_generator = LUT3DGenerator(
n_colors, n_vertices_3d, self.backbone.out_channels, n_ranks)
if n_vertices_1d > 0:
self.lut1d_generator = LUT1DGenerator(
n_colors, n_vertices_1d, self.backbone.out_channels,
color_share=lut1d_color_share)
self.n_ranks = n_ranks
self.n_colors = n_colors
self.n_vertices_3d = n_vertices_3d
self.n_vertices_1d = n_vertices_1d
self.sparse_factor = sparse_factor
self.smooth_factor = smooth_factor
self.monotonicity_factor = monotonicity_factor
self.backbone_name = backbone.lower()
self.train_cfg = train_cfg
self.test_cfg = test_cfg
self.fp16_enabled = False
self.init_weights()
self.recons_loss = build_loss(recons_loss)
# variables for quantization
self.en_quant = test_cfg.get('en_quant', False) if test_cfg else False
self.quantization_mode = (self.n_vertices_1d, self.n_vertices_3d)
self._quantized = False
if self.en_quant and self.quantization_mode not in self.allowed_quantization_modes:
get_logger('seplut').warning('Current implementation does not support '
'quantization on mode 1D#{}-3D#{}. Quantization is disabled.'.format(
*self.quantization_mode))
self.en_quant = False
def forward_dummy(self, imgs):
r"""The real implementation of model forward.
Args:
img (Tensor): Input image, shape (b, c, h, w).
Returns:
tuple(Tensor, Tensor, Tensor):
Output image, 3DLUT weights, 1DLUTs.
"""
# context vector: (b, f)
codes = self.backbone(imgs)
# generate 3x 1DLUTs and perform the 1D LUT transform
if self.n_vertices_1d > 0:
# (b, c, m)
lut1d = self.lut1d_generator(codes)
# achieved by converting the 1DLUTs into equivalent 3DLUT
iluts = []
for i in range(imgs.shape[0]):
iluts.append(torch.stack(
torch.meshgrid(*(lut1d[i].unbind(0)[::-1])),
dim=0).flip(0))
# (b, c, m, m, m)
iluts = torch.stack(iluts, dim=0)
imgs = lut_transform(imgs, iluts)
else:
lut1d = imgs.new_zeros(1)
# generate 3DLUT and perform the 3D LUT transform
if self.n_vertices_3d > 0:
# (b, c, d, d, d)
lut3d_weights, lut3d = self.lut3d_generator(codes)
outs = lut_transform(imgs, lut3d)
else:
lut3d_weights = imgs.new_zeros(1)
outs = imgs
return outs, lut3d_weights, lut1d
def forward_fast(self, imgs):
r"""The fast implementation of model forward. It uses a custom PyTorch
extension `seplut_transform` that merges the 1D and 3D LUT transforms
into a single kernel for efficiency.
[NOTE] The backward function of `seplut_transform` is not implemented,
so it cannot be used in the training.
Args:
img (Tensor): Input image, shape (b, c, h, w).
Returns:
Tensor: Output image.
"""
self.quantize()
# context vector: (b, f)
codes = self.backbone(imgs)
# 3x 1DLUTs: (b, c, m)
if self.n_vertices_1d > 0:
lut1d = self.lut1d_generator(codes)
else:
lut1d = (torch.arange(4, device=imgs.device)
.div(3).repeat(self.n_colors, 1))
lut1d = lut1d.unsqueeze(0).repeat(imgs.shape[0], 1, 1)
# 3DLUT: (b, c, d, d, d)
if self.n_vertices_3d > 0:
_, lut3d = self.lut3d_generator(codes)
else:
lut3d = torch.stack(
torch.meshgrid(*[torch.arange(4, device=imgs.device) \
for _ in range(self.n_colors)]),
dim=0).div(3).flip(0)
lut3d = lut3d.unsqueeze(0).repeat(
imgs.shape[0], 1, *([1] * self.n_colors))
imgs, lut1d, lut3d, lmin, lmax = \
self.preprocess_quantized_transform(imgs, lut1d, lut3d)
out = seplut_transform(imgs, lut3d, lut1d)
out = self.postprocess_quantized_transform(out, lmin, lmax)
self.dequantize()
return out
forward_dummy函数中可以看到前向计算的过程,图像输入到backbone中得到codes,codes分别输入到lut1d_generator和lut3d_generator中得到1DLUT和3DLUT,图像先经过1DLUT对图像进行增强(这里作者用了一个方法来统一1DLUT和3DLUT的增强函数,将1DLUT变换为3DLUT,实现方法是利用grid_sample,1DLUT通道之间是无关的,因此只需要利用组合就可以得到1DLUT对应的3DLUT),后续经过3DLUT对图像进行增强并输出。
forward_fast函数中实现了加入量化的前向过程,首先调用了self.quantize函数,函数只对1DLUT和3DLUT做量化,未对backbone的部分做量化,量化方法是torch.quantization.quantize_dynamic,动态量化方法,实现的是一个非对称的线性量化,如下所示。
def quantize(self):
r'''Apply PyTorch's dynamic quantization technique to model parameters.
'''
if not self.en_quant or self._quantized: return
if 'cuda' in str(next(self.parameters()).device):
get_logger('seplut').warning('Current implementation does not support '
'quantization on GPU model. Quantization is disabled. Please run '
'the inference on CPU.')
self.en_quant = False
return
self.modules_backup = {
self.lut1d_generator, self.lut3d_generator}
self.lut1d_generator = torch.quantization.quantize_dynamic(
self.lut1d_generator, {nn.Linear}, dtype=torch.qint8)
self.lut3d_generator = torch.quantization.quantize_dynamic(
self.lut3d_generator, {nn.Linear}, dtype=torch.qint8)
self._quantized = True
forward_fast后续推理的过程跟forward一致,推理出1DLUT和3DLUT,后续利用preprocess_quantized_transform和postprocess_quantized_transform完成推理。
def preprocess_quantized_transform(self, img, lut1d, lut3d):
r'''Quantize input image, 1D LUT and 3D LUT into 8-bit representation.
Args:
img (Tensor): Input image, shape (b, c, h, w).
lut1d (Tensor): 1D LUT, shape (b, c, n_vertices_1d).
lut3d (Tensor): 3D LUT, shape
(b, c, n_vertices_3d, n_vertices_3d, n_vertices_3d).
Returns:
tuple(Tensor, Tensor, Tensor, float, float):
Quantized input image, 1D LUT, 3D LUT,
minimum and maximum values of the 3D LUT.
'''
lmin, lmax = lut3d.min(), lut3d.max()
if self._quantized:
img = img.mul(255).round().to(torch.uint8)
lut1d = lut1d.mul(255).round().to(torch.uint8)
lut3d = lut3d.sub(lmin).div(lmax - lmin)
lut3d = lut3d.mul(255).round().to(torch.uint8)
return img, lut1d, lut3d, lmin, lmax
def postprocess_quantized_transform(self, out, lmin, lmax):
r'''Dequantize output image.
Args:
out (Tensor): Output image, shape (b, c, h, w).
lmin (float): minimum float value in the original 3D LUT.
lmax (float): maximum float value in the original 3D LUT.
Returns:
Tensor: Dequantized output image.
'''
if self._quantized:
out = out.float().div(255)
out = out.float().mul(lmax - lmin).add(lmin).clamp(0, 1)
out = out.mul(255).round().div(255)
return out
preprocess_quantized_transform是将img和lut进行量化,这里是实际进行量化,前面的动态量化函数实际没有完成量化,它只是保存了量化的系数,scale和zero_point等内容,量化完推理后再施行后处理的反量化postprocess_quantized_transform函数得到最终输出。
modules/lut.py 文件
1. LUT1DGenerator类
用于生成1DLUT,这里是生成n_colors*n_vertices的1DLUT,分别对应于颜色通道数和采样点数,如下所示。
class LUT1DGenerator(nn.Module):
r"""The 1DLUT generator module.
Args:
n_colors (int): Number of input color channels.
n_vertices (int): Number of sampling points.
n_feats (int): Dimension of the input image representation vector.
color_share (bool, optional): Whether to share a single 1D LUT across
three color channels. Default: False.
"""
def __init__(self, n_colors, n_vertices, n_feats, color_share=False) -> None:
super().__init__()
repeat_factor = n_colors if not color_share else 1
self.lut1d_generator = nn.Linear(
n_feats, n_vertices * repeat_factor)
self.n_colors = n_colors
self.n_vertices = n_vertices
self.color_share = color_share
def forward(self, x):
x = x.view(x.shape[0], -1)
lut1d = self.lut1d_generator(x).view(
x.shape[0], -1, self.n_vertices)
if self.color_share:
lut1d = lut1d.repeat_interleave(self.n_colors, dim=1)
lut1d = lut1d.sigmoid()
return lut1d
2. LUT3DGenerator类
用于生成3DLUT,这里是生成n_colors * (n_vertices ** n_colors)的3DLUT。
class LUT3DGenerator(nn.Module):
r"""The 3DLUT generator module.
Args:
n_colors (int): Number of input color channels.
n_vertices (int): Number of sampling points along each lattice dimension.
n_feats (int): Dimension of the input image representation vector.
n_ranks (int): Number of ranks (or the number of basis LUTs).
"""
def __init__(self, n_colors, n_vertices, n_feats, n_ranks) -> None:
super().__init__()
# h0
self.weights_generator = nn.Linear(n_feats, n_ranks)
# h1
self.basis_luts_bank = nn.Linear(
n_ranks, n_colors * (n_vertices ** n_colors), bias=False)
self.n_colors = n_colors
self.n_vertices = n_vertices
self.n_feats = n_feats
self.n_ranks = n_ranks
def init_weights(self):
r"""Init weights for models.
For the mapping f (`backbone`) and h (`lut_generator`), we follow the initialization in
[TPAMI 3D-LUT](https://github.com/HuiZeng/Image-Adaptive-3DLUT).
"""
nn.init.ones_(self.weights_generator.bias)
identity_lut = torch.stack([
torch.stack(
torch.meshgrid(*[torch.arange(self.n_vertices) for _ in range(self.n_colors)]),
dim=0).div(self.n_vertices - 1).flip(0),
*[torch.zeros(
self.n_colors, *((self.n_vertices,) * self.n_colors)) for _ in range(self.n_ranks - 1)]
], dim=0).view(self.n_ranks, -1)
self.basis_luts_bank.weight.data.copy_(identity_lut.t())
def forward(self, x):
weights = self.weights_generator(x)
luts = self.basis_luts_bank(weights)
luts = luts.view(x.shape[0], -1, *((self.n_vertices,) * self.n_colors))
return weights, luts
def regularizations(self, smoothness, monotonicity):
basis_luts = self.basis_luts_bank.weight.t().view(
self.n_ranks, self.n_colors, *((self.n_vertices,) * self.n_colors))
tv, mn = 0, 0
for i in range(2, basis_luts.ndimension()):
diff = torch.diff(basis_luts.flip(i), dim=i)
tv += torch.square(diff).sum(0).mean()
mn += F.relu(diff).sum(0).mean()
reg_smoothness = smoothness * tv
reg_monotonicity = monotonicity * mn
return reg_smoothness, reg_monotonicity
都是熟悉的实现了。
3、总结
代码实现核心的部分讲解完毕,该篇论文的代码比较简单,1DLUT模拟3DLUT的实现不太好理解,大家可以参考着作者的实现自己跑一下这个模拟的过程,看看tensor对应实际的内容。
感谢阅读,欢迎留言或私信,一起探讨和交流。
如果对你有帮助的话,也希望可以给博主点一个关注,感谢。

















 1815
1815

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









