



BN (Batch Normalization):批量归一化
一 、Pytorch加载数据
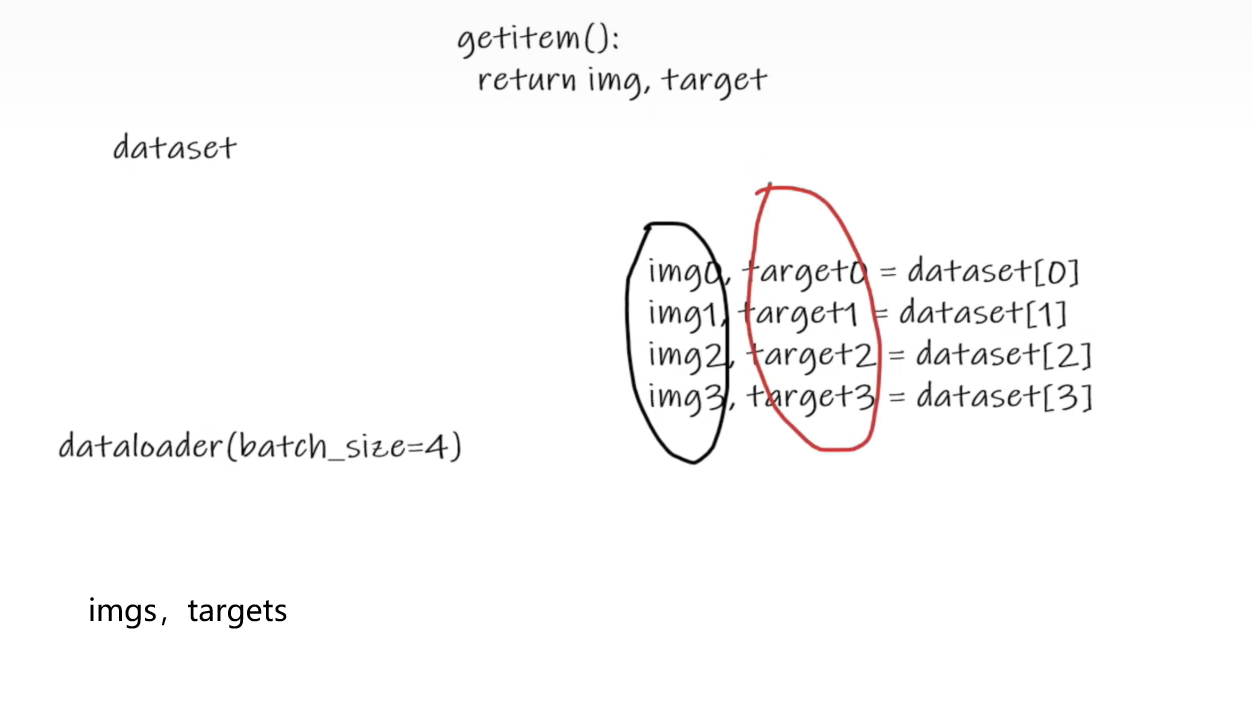
__getitem__方法:用于获取每一条数据及其label
__len__方法:用于获取dataset的大小。
从torch.utils.data包引入Dataset类
from torch.utils.data import Dataset
二、Dataset代码实战
from torch.utils.data import Dataset
from PIL import Image
import cv2
import os
class Mydata(Dataset):
def __init__(self,root_dir,label_dir):
self.root_dir=root_dir
self.label_dir=label_dir
#合并:相当于root_dir目录下的某一类
self.path=os.path.join(self.root_dir,self.label_dir)
#root_dir目录下的某一类里的全部 整个数据集
self.img_path=os.listdir(self.path)
def __getitem__(self,idx):
#idx相当于数组中的下标
img_name=self.img_path[idx]
#图片的位置
img_item_path=os.path.join(self.root_dir,self.label_dir,img_name)
#读取图片 需要 from PIL import Image
img=Image.open(img_item_path)
label=self.label_dir
return img,label
def __len__(self):
#数据集的长度,即有多少张图片
return len(self.img_path)
root_dir="data/test"
blur_label_dir="blur"
cover_label_dir="cover"
blur_dataset=Mydata(root_dir,blur_label_dir)
cover_dataset=Mydata(root_dir,cover_label_dir)
#两个数据集的集合
train_dataset=blur_dataset+cover_dataset
三、TensorBoard的使用
1、add_scalar()的使用(常用来绘制train/val loss)
#从torch的工具箱(utils)中导出tensorboard这个类
from torch.utils.tensorboard import SummaryWriter
writer=SummaryWriter("logs")
#writer.add_image()
#y=x
for i in range(100):
writer.add_scalar("y=2x",2*i,i)
writer.close()
#以上运行后会创建一个logs文件夹
#在终端运行以下命令会实现绘制y=x图像
tensorboard --logdir=logs
2、add_image()的使用
#从torch的工具箱(utils)中导出tensorboard这个类
from torch.utils.tensorboard import SummaryWriter
import numpy as np
from PIL import Image
writer=SummaryWriter("logs")
image_path="data/test/blur/1.jpeg"
img_PIL=Image.open(image_path)
#把jpeg类型的图片转换为numpy类型
img_array=np.array(img_PIL)
#输出图片的类型
print(type(img_array))
print(img_array.shape)
writer.add_image("test",img_array,1,dataformats='HWC')
四、Transforms的使用
torchvision中的transforms
1、ToTensor()的使用
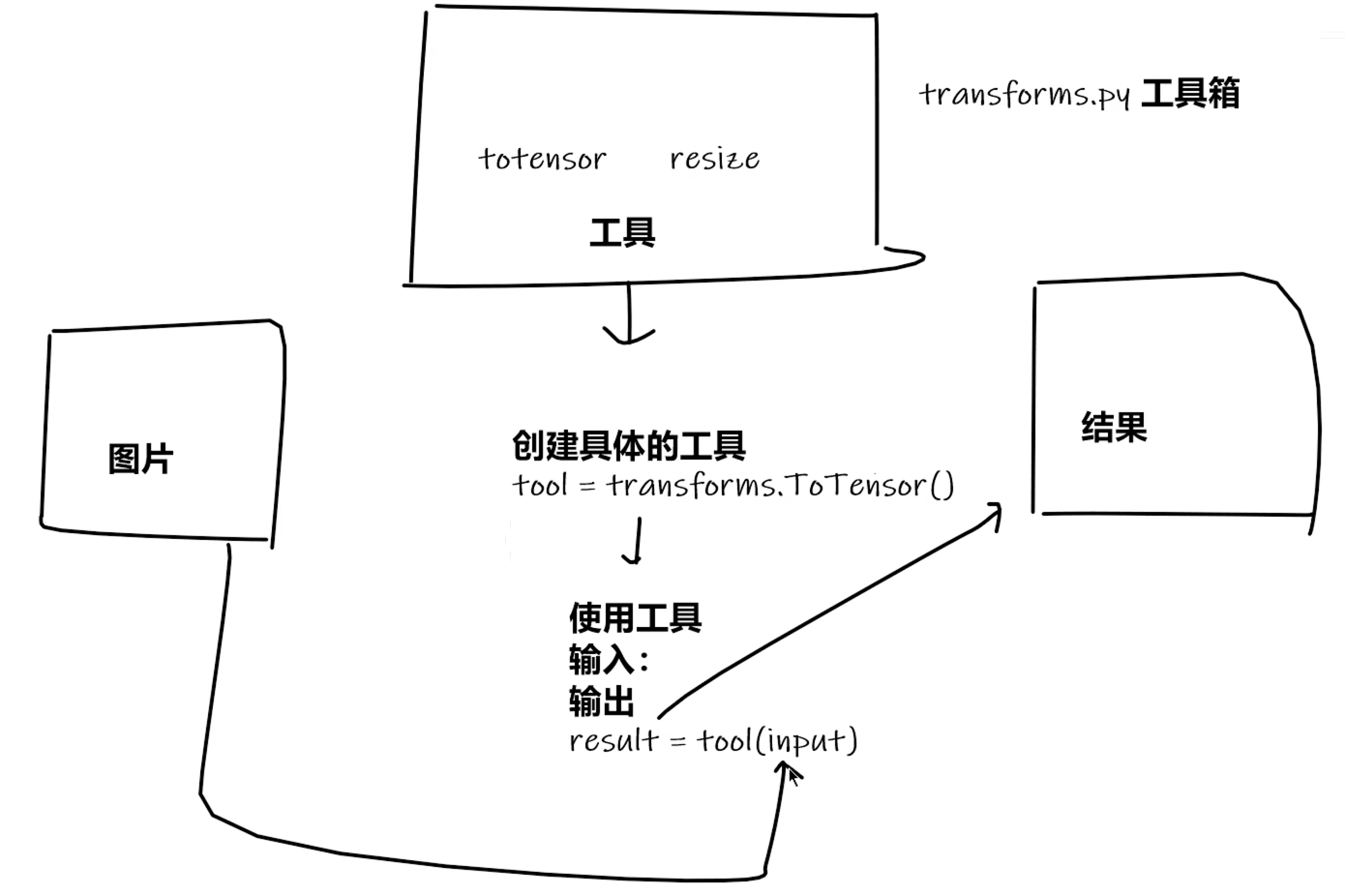
from torchvision import transforms
from PIL import Image
img_path="data/test/blur/1.jpeg"
img=Image.open(img_path)
#输出图片的类型
#print(img)
tensor_trans=transforms.ToTensor()
#将img的图片类型转换为tensor类型
tensor_img=tensor_trans(img)
print(tensor_img)
2、为什么需要Tensor类型?
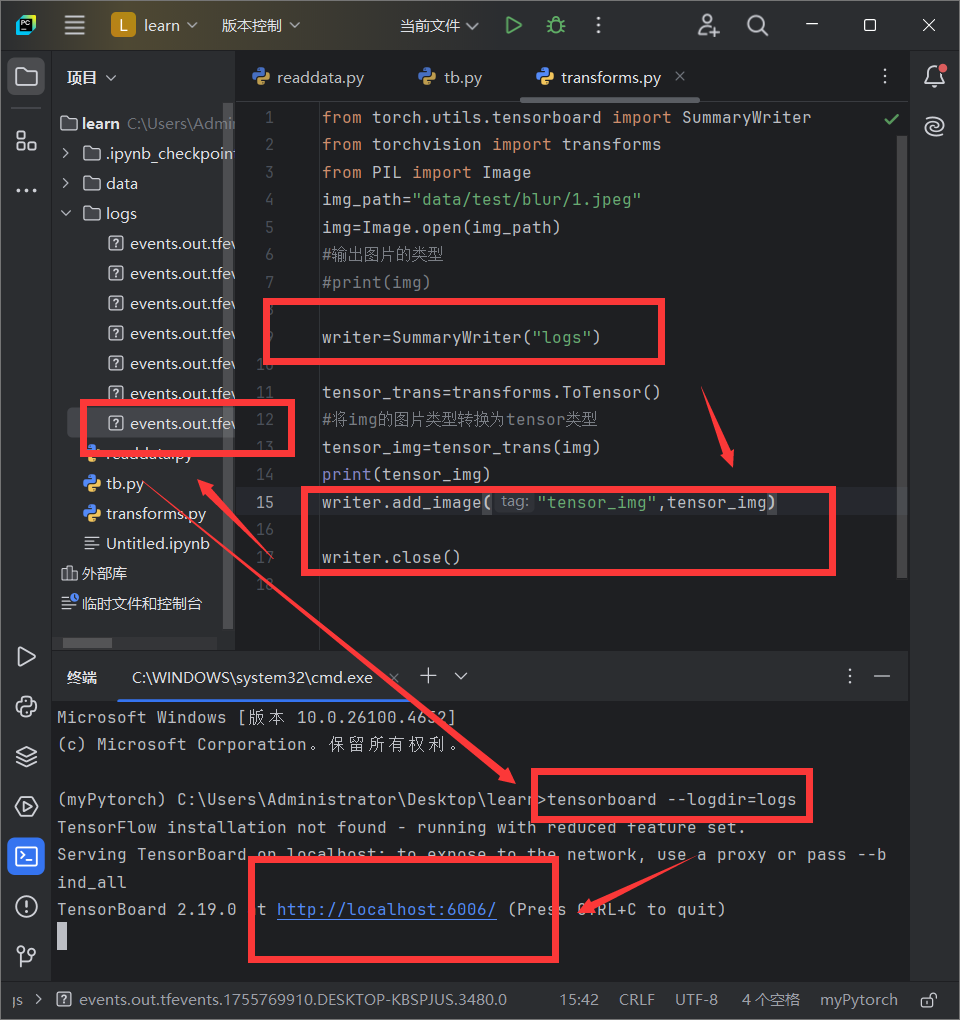
from torch.utils.tensorboard import SummaryWriter
from torchvision import transforms
from PIL import Image
img_path="data/test/blur/1.jpeg"
img=Image.open(img_path)
#输出图片的类型
#print(img)
writer=SummaryWriter("logs")
tensor_trans=transforms.ToTensor()
#将img的图片类型转换为tensor类型
tensor_img=tensor_trans(img)
print(tensor_img)
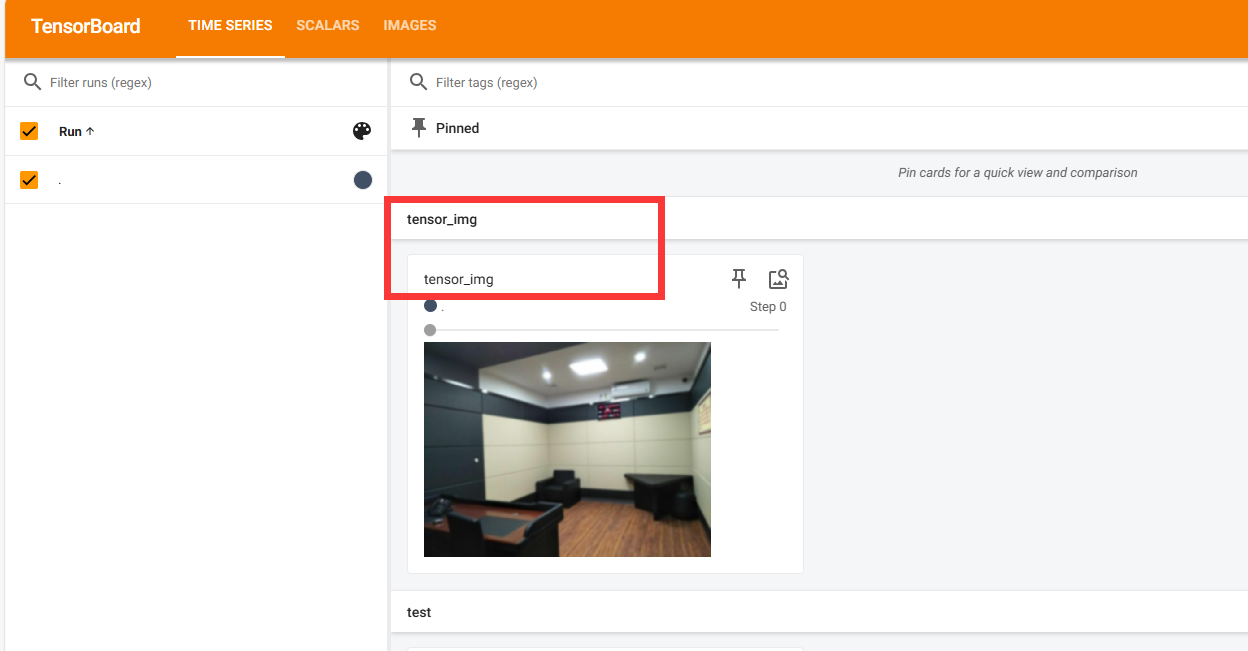
writer.add_image("tensor_img",tensor_img)
writer.close()
ToTensor()用法:把PIL image 或numpy类型转换成ToTensor类型
3、常见的Transforms
class Person:
#对象名+参数
def __call__(self, name):
print("__call__"+"hello"+name)
def hello(self,name):
print("hello"+name)
person=Person()
person("zs") #__call__hellozs
person.hello("ls") #hellols
ToPILImage()用法
ToPILImage() 是一个常用于将张量(Tensor)或 NumPy 数组转换为 PIL(Python Imaging Library)图像对象的函数。
import torch
from torchvision.transforms import ToPILImage
#假设有一个张量表示的图像(形状为 CxHxW,值范围 [0, 1])
tensor_image = torch.rand(3, 256, 256) # 3通道 RGB 图像
#转换为 PIL 图像
to_pil = ToPILImage()
pil_image = to_pil(tensor_image)
#显示或保存
pil_image.show()
pil_image.save("output.jpg")
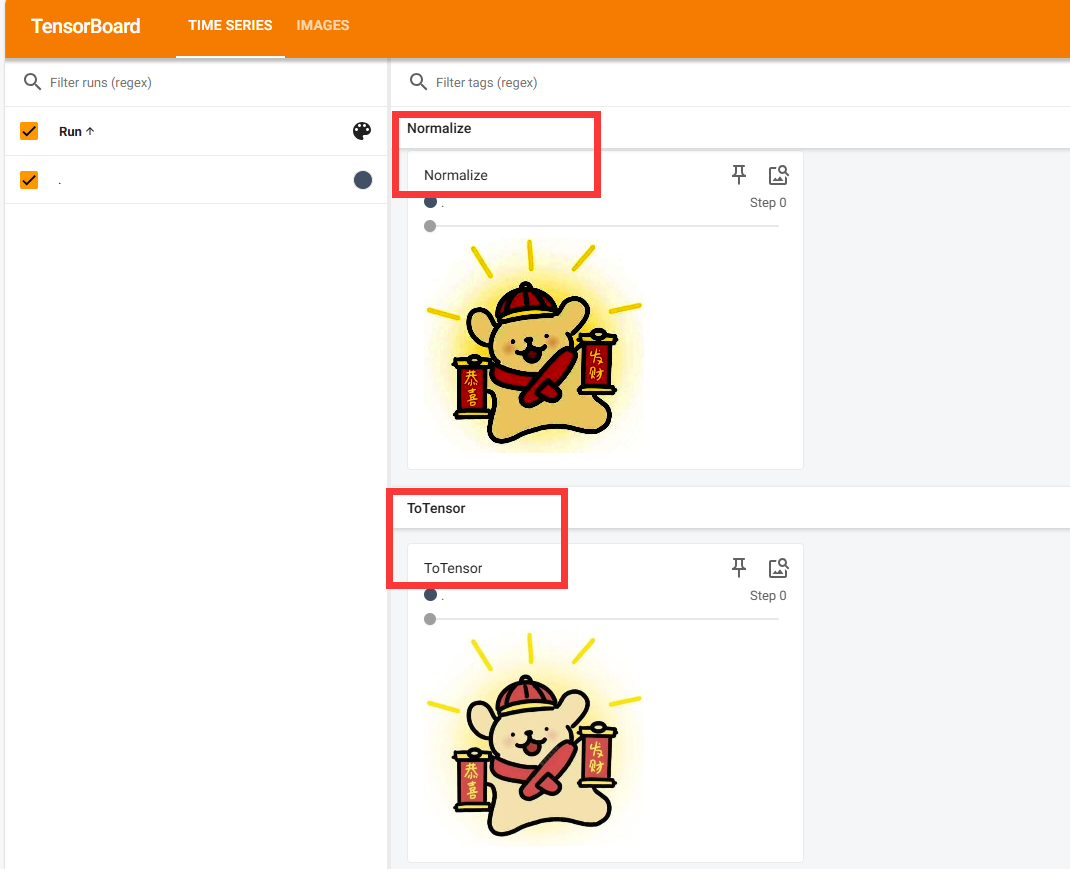
Normalize()用法:归一化??
数据归一化的常见方法就是对每个通道进行均值减除和标准差缩放
from PIL import Image
from torch.utils.tensorboard import SummaryWriter
from torchvision import transforms
writer =SummaryWriter("logs")
img=Image.open("image/pic.jpg")
print(img)
trans_toTensor=transforms.ToTensor()
img_tensor=trans_toTensor(img)
writer.add_image("ToTensor",img_tensor)
#Normalize
print(img_tensor[0][0][0])
trans_norm=transforms.Normalize([0.5,0.5,0.5],[0.5,0.5,0.5])
img_norm=trans_norm(img_tensor)
print(img_norm[0][0][0])
writer.add_image("Normalize",img_norm)
writer.close()
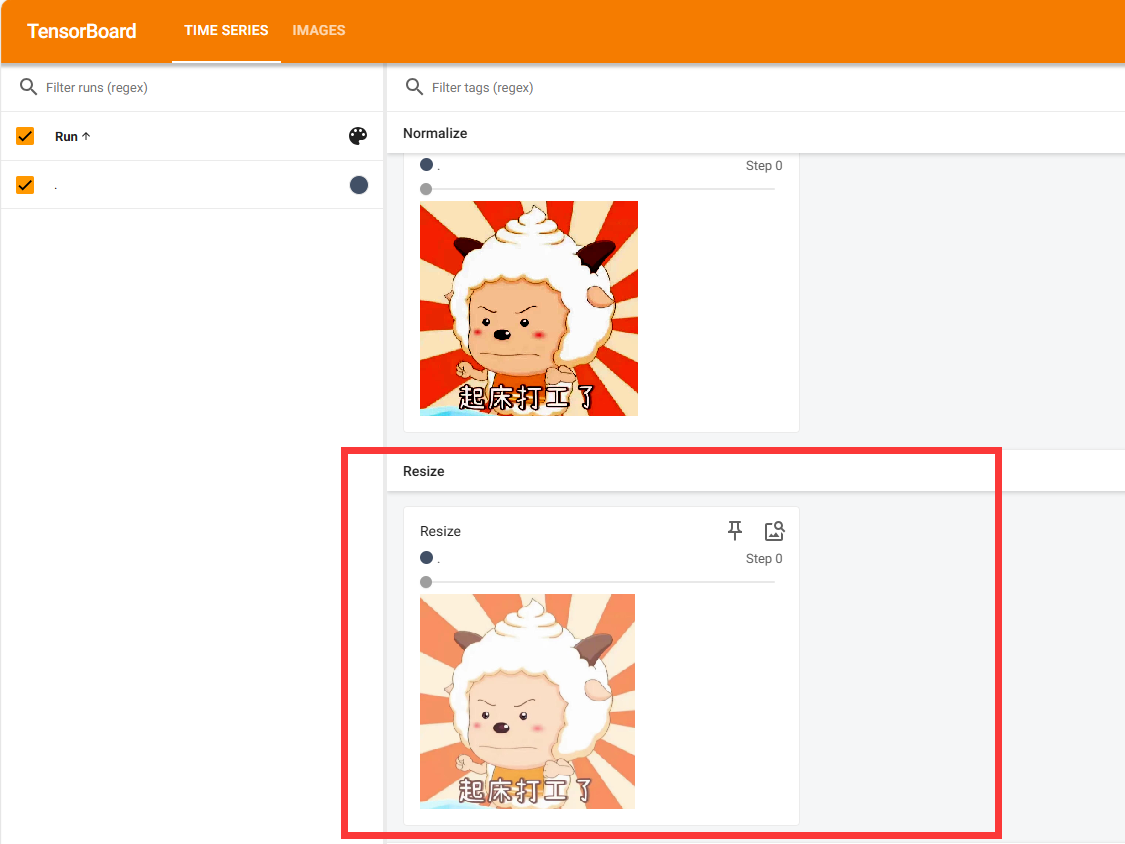
Resize()用法
from PIL import Image
from torch.utils.tensorboard import SummaryWriter
from torchvision import transforms
#ToTensor
writer =SummaryWriter("logs")
img=Image.open("image/12.jpeg")
print(img)
trans_toTensor=transforms.ToTensor()
img_tensor=trans_toTensor(img)
writer.add_image("ToTensor",img_tensor)
#Normalize
print(img_tensor[0][0][0])
trans_norm=transforms.Normalize([0.5,0.5,0.5],[0.5,0.5,0.5])
img_norm=trans_norm(img_tensor)
print(img_norm[0][0][0])
writer.add_image("Normalize",img_norm)
#Resize
print(img.size) #原来图片大小为1170x1153
trans_resize=transforms.Resize((512,512))
#img是PIL类型
img_resize=trans_resize(img)
#img PIL类型转换为tensor类型
img_resize=trans_toTensor(img_resize)
print(img_resize)#Resize后图片大小变为512x512
writer.add_image("Resize",img_resize,0)
writer.close()
Compose()用法

#Compose -resize -2
trans_resize_2=transforms.Resize(512)
trans_compose=transforms.Compose([trans_resize_2,trans_toTensor])
img_resize_2=trans_compose(img)
writer.add_image("Resize",img_resize_2)
writer.close()
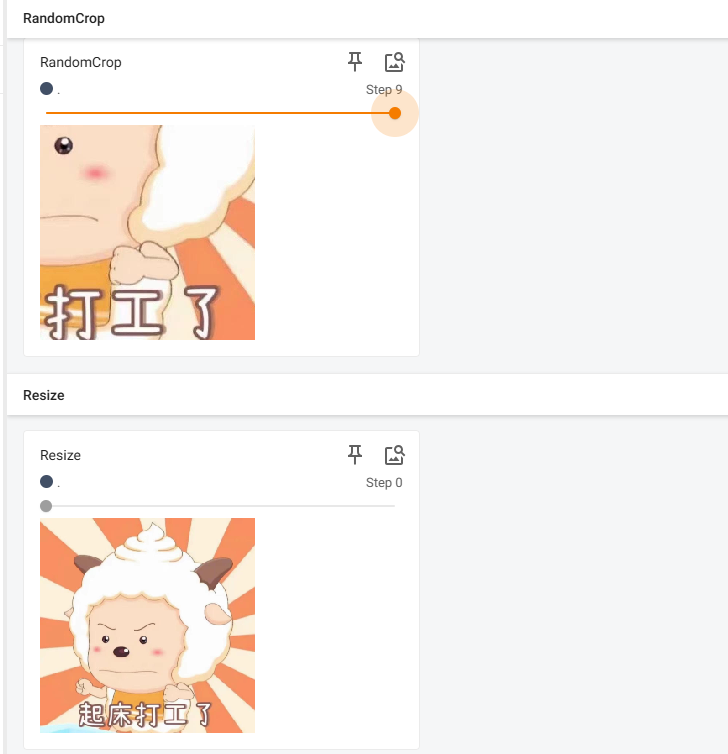
RandomCrop()用法:随机裁剪
#RandomCrop 随机裁剪
trans_random=transforms.RandomCrop(512)
trans_compose_2=transforms.Compose([trans_random,trans_toTensor])
for i in range(10):
img_crop=trans_compose_2(img)
writer.add_image("RandomCrop",img_crop,i)
writer.close()
五、torchvision中的数据集使用
1、Dataset与transform结合使用
下载数据集很慢的时候可以使用迅雷输入数据集链接下载
import torchvision
from torch.utils.tensorboard import SummaryWriter
dataset_transform=torchvision.transforms.Compose([
torchvision.transforms.ToTensor()
])
#注意这里的transform=dataset_transform不要忘记了,把数据集里的图片全部转换为totensor类型
#ctrl+p查看参数
train_dataset=torchvision.datasets.CIFAR10(root="./dataset",train=True,transform=dataset_transform,download=True)
test_dataset=torchvision.datasets.CIFAR10(root="./dataset",train=False,transform=dataset_transform,download=True)
#输出ToTensor类型
print(test_dataset[0])
#查看测试数据集中的第一个
print(test_dataset[0])
print(test_dataset.classes) #输出类别
img,target=test_dataset[0]
#输出img的图片类型
print(img) #不加dataset_transform之前是PIL类型
print(target) #3
print(test_dataset.classes[target]) #cat
#显示图片
img.show()
writer=SummaryWriter("log")
for i in range(10):
img,target=test_dataset[i]
writer.add_image("test_dataset",img,i)
writer.close()
六、DataLoader的使用
import torchvision
from torch.utils.data import DataLoader
from torch.utils.tensorboard import SummaryWriter
#准备的测试集
test_data=torchvision.datasets.CIFAR10("./dataset",train=False,transform=torchvision.transforms.ToTensor())
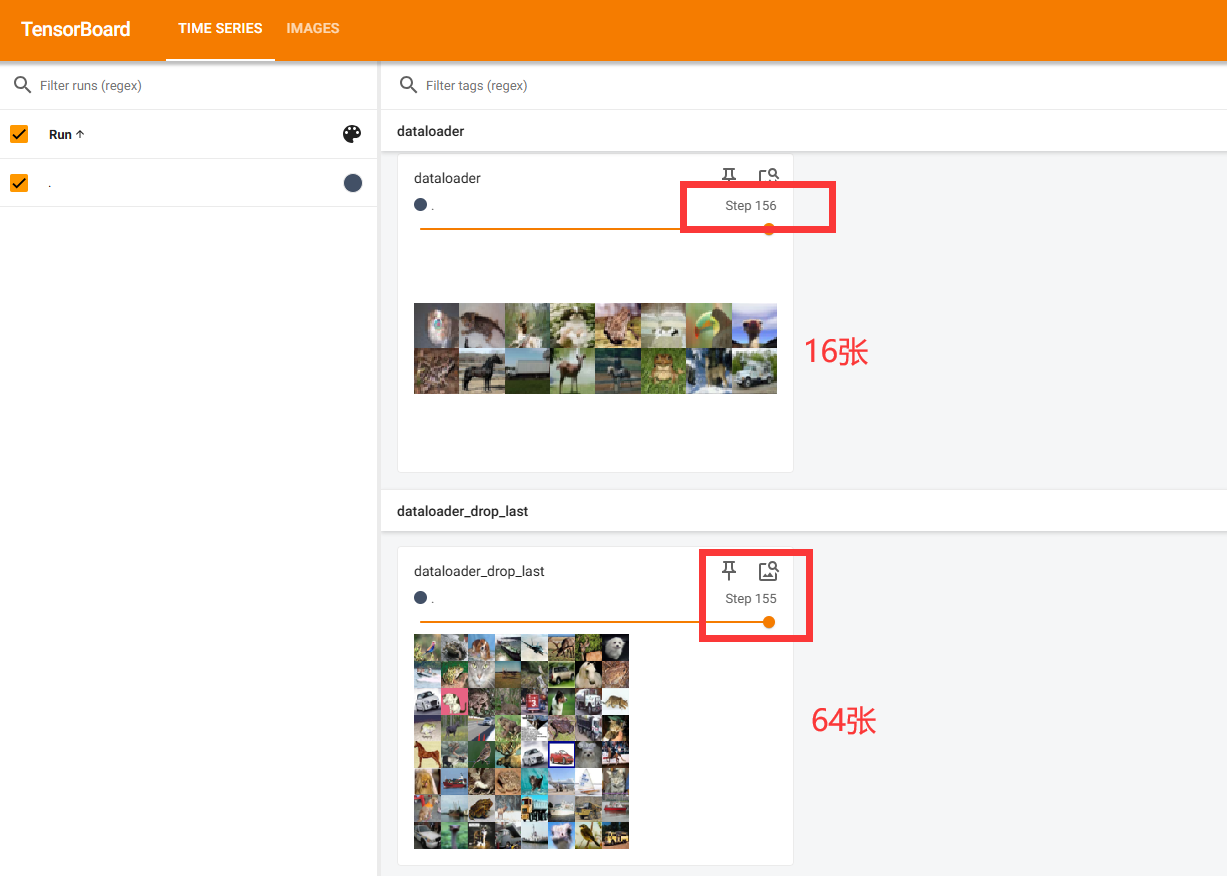
#batch_size 从dataloader中取4个数据 不删除
#test_dataloader=DataLoader(dataset=test_data,batch_size=64,shuffle=True,num_workers=0,drop_last=False)
#drop_last=True 删除最后不足64张的16张
#shuffle为True表示每一轮会打乱顺序 ,shuffle为false时每一轮的顺序是一样的 一般设置为True
test_dataloader=DataLoader(dataset=test_data,batch_size=64,shuffle=False,num_workers=0,drop_last=True)
#测试数据集中第一张图片及target
img,target=test_data[0]
print(img.shape) #torch.Size([3, 32, 32])
print(target) #3
writer=SummaryWriter("logs")
#Tab 一键缩进
#进行两轮
for epoch in range(2):
step=0
for data in test_dataloader:
imgs,targets=data
# print(imgs.shape) #torch.Size([4, 3, 32, 32]) 4张图片 3通道 32x32
# print(targets)
writer.add_images("Epoch:{}".format(epoch),imgs,step)
step=step+1
writer.close()
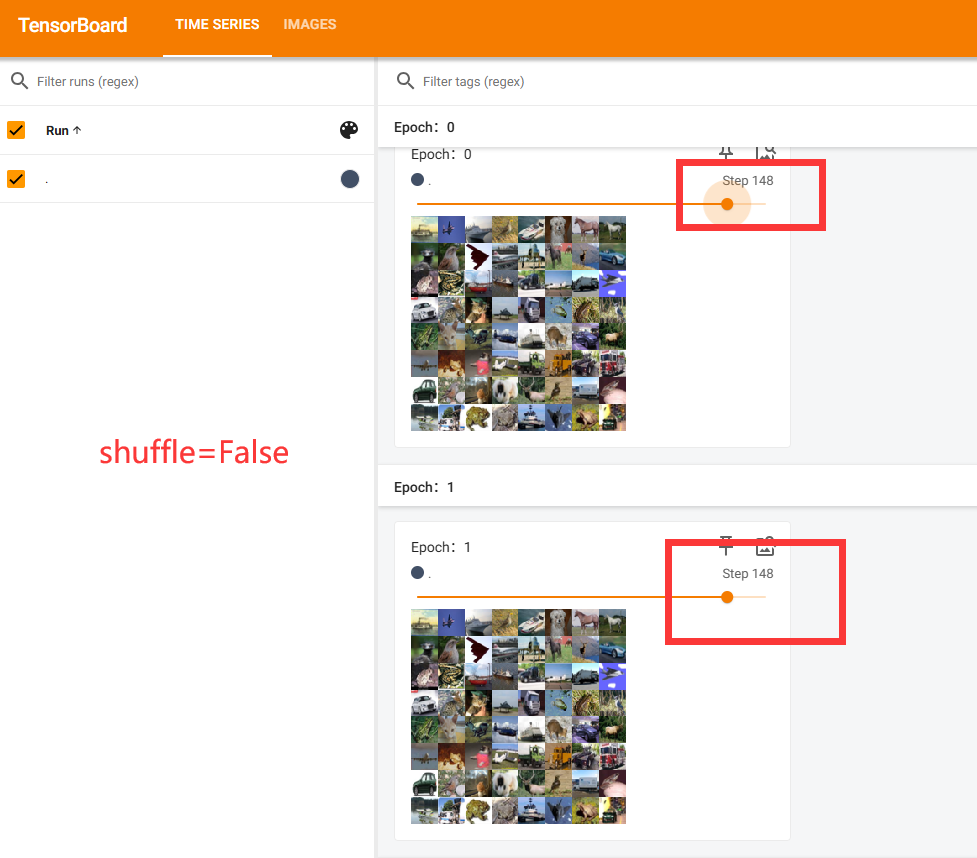
drop_last=True or False的区别
True时:最后一轮不足batch_size=64张会删除
False时不会删除
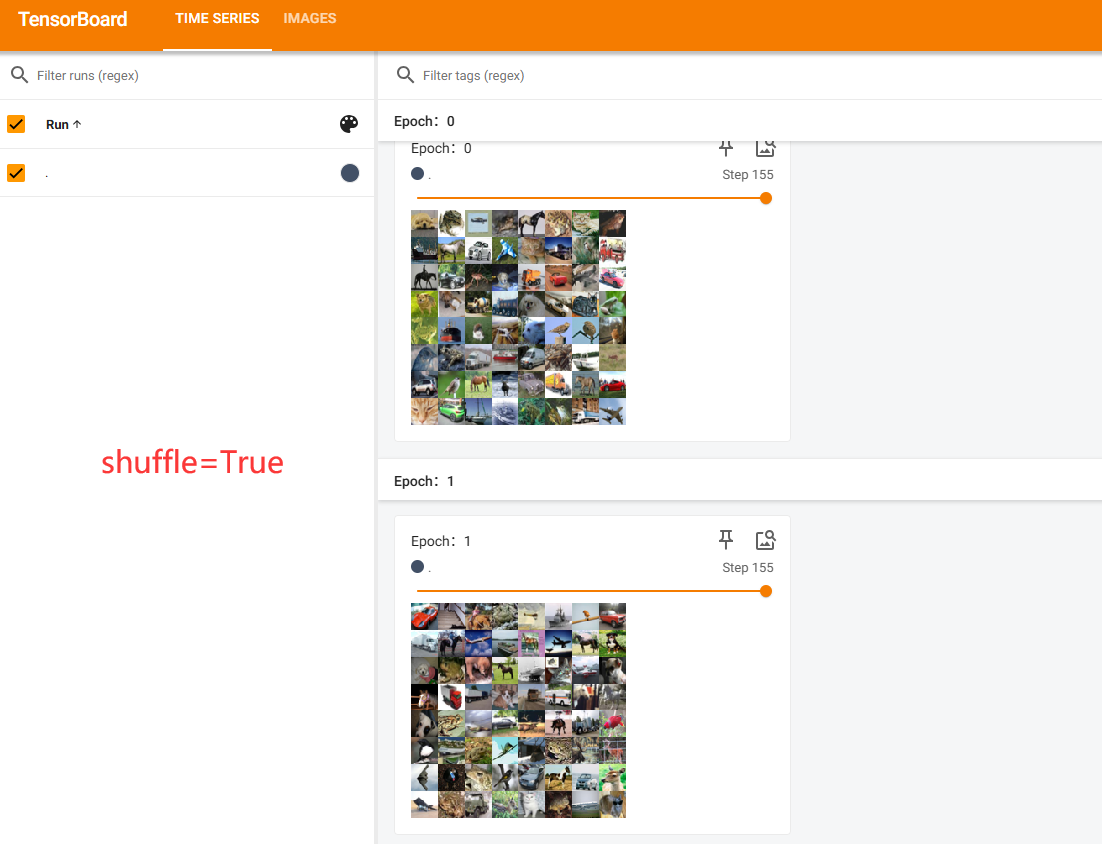
shuffle=True or False的区别
shuffle为True表示每一轮会打乱顺序
shuffle为false时每一轮的顺序是一样的
一般设置为True
七、神经网络的骨架—nn.Module的使用
Pytorch官网代码
import torch.nn as nn
import torch.nn.functional as F
class Model(nn.Module):
def __init__(self) -> None:
super().__init__()
self.conv1 = nn.Conv2d(1, 20, 5)
self.conv2 = nn.Conv2d(20, 20, 5)
def forward(self, x):
x = F.relu(self.conv1(x))
return F.relu(self.conv2(x))
解释forward两行代码

实例代码
import torch
from torch import nn
class Model(nn.Module):
def __init__(self):
super().__init__()
def forward(self,input):
output=input+1
return output
model=Model()
x=torch.tensor(1.0)
output=model(x)
print(output)
代码运行结果
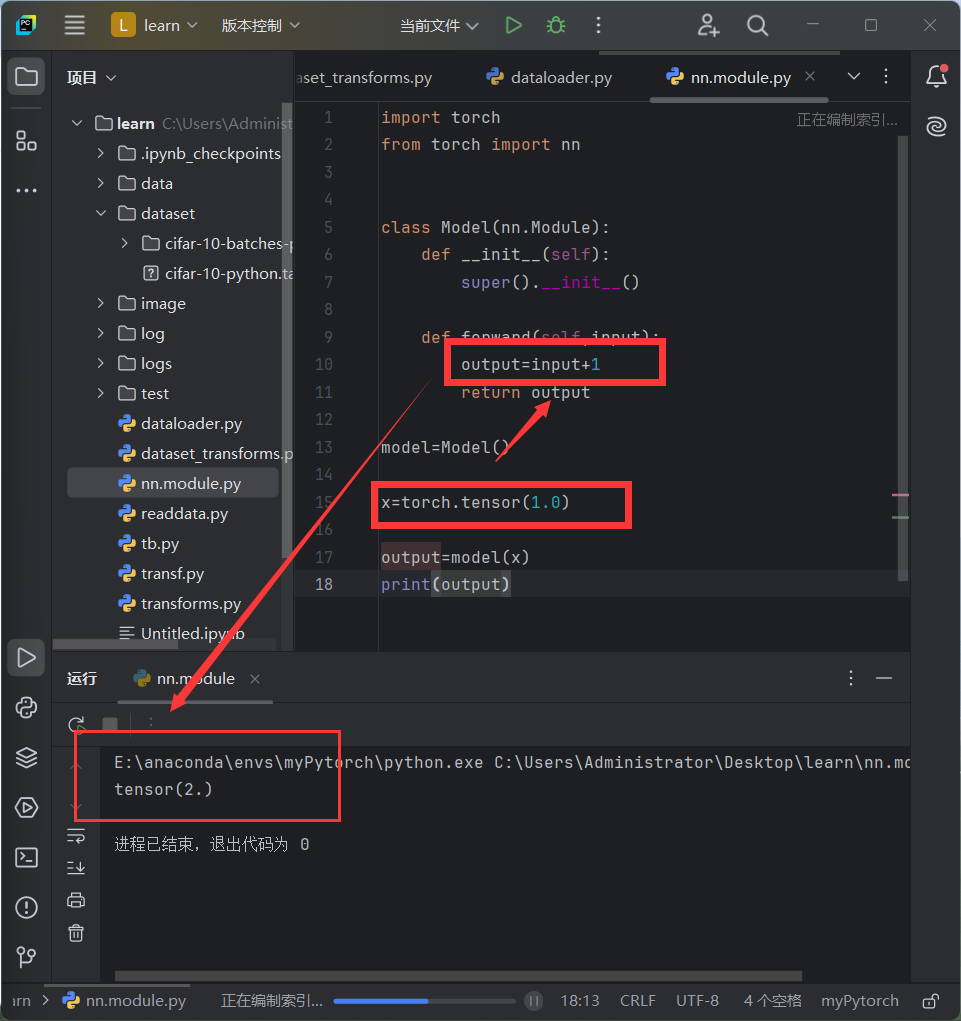


















 2825
2825

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









