




一.分布式事务介绍
分布式事务指事务的参与者、支持事务的服务器、资源服务器以及事务管理器分别位于不同的分布式系统的不同节点之上。简单的说,就是一次大的操作由不同的小操作组成,这些小的操作分布在不同的服务器上,且属于不同的应用,分布式事务需要保证这些小操作要么全部成功,要么全部失败。本质上来说,分布式事务就是为了保证不同数据库的数据一致性。
可以归结为以下几种场景:
- 单体系统访问多个数据库
- 多个微服务访问同一个数据库
- 多个微服务访问多个数据库
二.分布式理论(CAP,BASE)
1.CAP
CAP 指的是在分布式环境下,一个系统需要满足一致性/可用性/分区容错性这三个特性,而经过无数系统的实践,最终我们发现一个分布式系统,无法同时满足这三点。
C: 一致性 => 一 个分布式系统,在任意情况下,所有实例都应该返回最新一致的数据。
A: 可用性 => 一 个分布式系统,在任意情况下,所有实例都应该能够随时响应成功数据给客户端,哪怕数据是旧数据。
P: 分区容错性 => 一 个分布式系统,要保证在任意情况下,至少有一个网络分区是可用的,从另一方面来说,就是存在多个网络分区时,能够容忍有部分分区不可用。
分区更多意义上,指的是网络分区(一个一个机房)
由于每个系统都基本要满足分区容错性,而分区容错也就意味着服务实例可能存在多个不同的网络分区中,而一旦在多个不同的网络分区时,A/C之间就产生了互斥性,也就证明了确实一个系统无法实现 CAP 三点同时满足。由于分区容错性是绝大部分系统都应该满足的特性,因此真正的系统设计更多考虑的特性只有 CP/AP 两种类型的系统。
2.BASE理论
BASE (Basically Available Soft state Eventually consistent)基本可用软状态(中间状态)的最终一致
- BA: 基本可用 =>在一个分布式系统中,只要满足基本可用即可,无需所有节点都可用。
- S: 中间状态 =>在一个分布式系统中,不需要满足强一致性,允许其存在中间状态。
- E:最终一致性 =>在一个分布式系统中,允许存在中间状态,但是最终(时效性)一定要达成一致。
BASE 理论更多是针对 CAP 的一个优化版本,核心是最终一致以及中间状态,保证服务实例基本可用就行,目前绝大部分系统的设计其实都是按照 BASE 理论去进行设计的。
三.分布式事务的解决方案
1.全局事务XA
全局事务基于DTP模型实现。DTP是由X/Open组织提出的一种分布式事务模型——X/Open
Distributed Transaction Processing Reference Model。它规定了要实现分布式事务,需要三种角色:
- AP: Application 应用系统 (微服务)
- TM: Transaction Manager 事务管理器 (全局事务管理)
- RM: Resource Manager 资源管理器 (数据库)

1.二阶段提交
整个事务分成两个阶段(2PC):
阶段一:准备阶段(Prepare Phase)
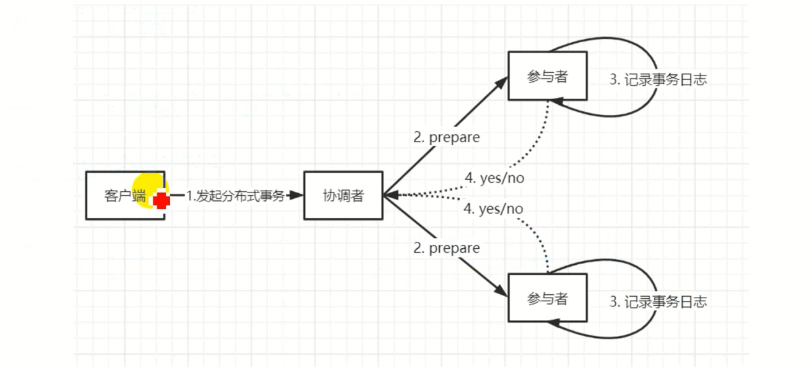
- 协调者(Coordinator)向所有参与者(Participants)发送
prepare请求,询问它们是否准备好提交事务。 - 每个参与者检查本地事务的状态,确定是否可以提交事务。
- 如果参与者能够提交事务(例如,没有冲突、资源可用等),它会锁定相关资源,并返回
prepared响应给协调者。 - 如果某个参与者无法提交事务(例如,资源不足或发生错误),它会返回
abort响应给协调者。 - 协调者等待所有参与者的响应。如果所有参与者都返回
prepared,则进入第二阶段;如果有任何一个参与者返回abort,则整个事务将被回滚。
阶段二: 提交阶段(Commit
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 3098
3098

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









