




一.Kafka的系统架构
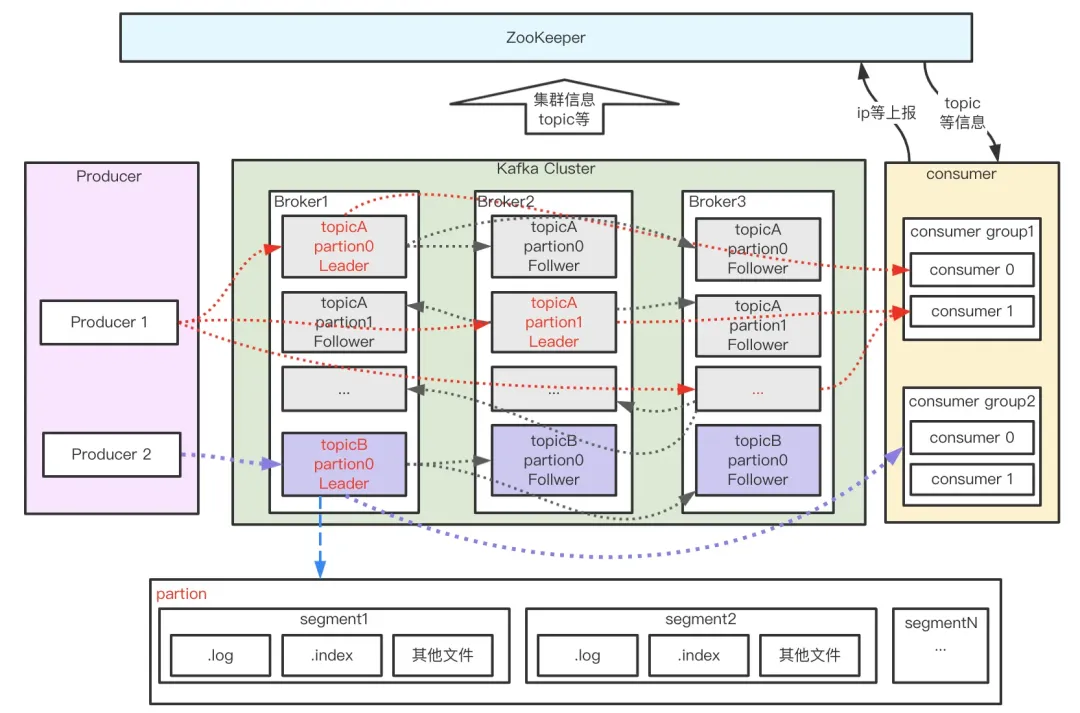
如上图所示,Kafka由Producer、Broker、Consumer 以及负责集群管理的 ZooKeeper 组成,各部分功能如下:
- Producer:生产者,负责消息的创建并通过一定的路由策略发送消息到合适的 Broker
- Broker:服务实例,负责消息的持久化、中转等功能;
- Consumer:消费者,负责从 Broker 中拉取(Pull)订阅的消息并进行消费,通常多个消费者构成一个分组,消息只能被同组中的一个消费者消费;
- ZooKeeper:负责 broker、consumer 集群元数据的管理等;
上图消息流转过程中,还有几个特别重要的概念—主题(Topic)、分区(Partition)、分段(segment)、位移(offset)。
- topic:消息主题。Kafka 按 topic 对消息进行分类,我们在收发消息时只需指定 topic。
- partition:分区。为了提升系统的吞吐,一个 topic 下通常有多个 partition,partition 分布在不同的 Broker 上,用于存储 topic 的消息,这使 Kafka 可以在多台机器上处理、存储消息,给 kafka 提供给了并行的消息处理能力和横向扩容能力。另外,为了提升系统的可靠性,partition 通常会分组,且每组有一个主 partition、多个副本 partition,且分布在不同的 broker 上,从而起到容灾的作用。
- segment:分段。宏观上看,一个 partition 对应一个日志(Log)。由于生产者生产的消息会不断追加到 log 文件末尾,为防止 log 文件过大导致数据检索效率低下,Kafka 采取了分段和索引机制,将每个 partition 分为多个 segment,同时也便于消息的维护和清理。每个 segment 包含一个 .log 日志文件、两个索引(.index、timeindex)文件以及其他可能的文件。每个 Segment 的数据文件以该段中最小的 offset 为文件名,当查找 offset 的 Message 的时候,通过二分查找快找到 Message 所处于的 Segment 中。
- offset:消息在日志中的位置,消息在被追加到分区日志文件的时候都会分配一个特定的偏移量。offset 是消息在分区中的唯一标识,是一个单调递增且不变的值。Kafka 通过它来保证消息在分区内的顺序性,不过 offset 并不跨越分区,也就是说,Kafka 保证的是分区有序而不是主题有序。
二.Kafka的高可靠性(不丢失)
Kafka 高可靠性的核心是保证消息在传递过程中不丢失,涉及如下核心环节:
- 消息从生产者可靠地发送至 Broker;-- 网络、本地丢数据。
- 发送到 Broker 的消息可靠持久化;-- PageCache 缓存落盘、单点崩溃、主从同步跨网络
- 消费者从 Broker 消费到消息且最好只消费一次 -- 跨网络消息传输。
如何保障消息从生产者可靠地发送至 Broker
Producer 发送消息后,能够收到来自 Broker 的消息保存成功 ack;
- Request.required.acks = 0:请求发送即认为成功,不关心有没有写成功,常用于日志进行分析场景。
- Request.required.acks = 1:当 leader partition 写入成功以后,才算写入成功,有丢数据的可能。
- Request.required.acks= -1:ISR 列表里面的所有副本都写完以后,这条消息才算写入成功,强可靠性保证。
为了实现强可靠的 kafka 系统,我们需要设置 Request.required.acks= -1,同时还会设置集群中处于正常同步状态的副本 follower 数量 min.insync.replicas>2,另外,设置 unclean.leader.election.enable=false 使得集群中 ISR 的 follower 才可变成新的 leader,避免特殊情况下消息截断的出现。
三.Kafka的消息持久化
为了确保 Producer 收到 Broker 的成功 ack 后,消息一定不在 Broker 环节丢失,我们核心要关注以下几点:
- Broker 返回 Producer 成功 ack 时,消息是否已经落盘;
- Broker 宕机是否会导致数据丢失,容灾机制是什么;
- Replica 副本机制带来的多副本间数据同步一致性问题如何解决;
Broker 异步刷盘机制
kafka 为了获得更高吞吐,Broker 接收到消息后只是将数据写入 PageCache 后便认为消息已写入成功,而 PageCache 中的数据通过 linux 的 flusher 程序进行异步刷盘(刷盘触发条:主动调用 sync 或 fsync 函数、可用内存低于阀值、dirty data 时间达到阀值),将数据顺序写到磁盘。由于消息是写入到 PageCache ,单机场景,如果还没刷盘 Broker 就宕机了,那么 Producer 产生的这部分数据就可能丢失。为了解决单机故障可能带来的数据丢失问题,Kafka 为分区引入了副本机制。
Replica 副本机制
Kafka 每组分区通常有多个副本,同组分区的不同副本分布在不同的 Broker 上,保存相同的消息(可能有滞后)。副本之间是“一主多从”的关系,其中 leader 副本负责处理读写请求,follower 副本负责从 leader 拉取消息进行同步。分区的所有副本统称为 AR(Assigned Replicas),其中所有与 leader 副本保持一定同步的副本(包括 leader 副本在内)组成ISR(In-Sync Replicas),与 leader 同步滞后过多的副本组成 OSR(Out-of-Sync Replicas),由此可见,AR=ISR+OSR。follower 副本是否与leader同步的判断标准取决于 Broker 端参数 replica.lag.time.max.ms(默认为10秒),follower 默认每隔 500ms 向 leader fetch 一次数据,只要一个 Follower 副本落后 Leader 副本的时间不连续超过10秒,那么 Kafka 就认为该 Follower 副本与 leader 是同步的。在正常情况下,所有的 follower 副本都应该与 leader 副本保持一定程度的同步,即 AR=ISR,OSR 集合为空。
当 leader 副本所在 Broker 宕机时,Kafka 会借助 ZK 从 follower 副本中选举新的 leader 继续对外提供服务,实现故障的自动转移,保证服务可用。为了使选举的新 leader 和旧 leader 数据尽可能一致,当 leader 副本发生故障时,默认情况下只有在 ISR 集合中的副本才有资格被选举为新的 leader,而在 OSR 集合中的副本则没有任何机会(可通过设置un
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 957
957

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









