 宏与内联函数性能安全对比
宏与内联函数性能安全对比




上一讲我们深入探讨了goto语句的用法、典型陷阱及其在资源清理中的正确实践。今天进入 Day 36:宏与内联函数性能与安全对比,将从原理、陷阱、实践与底层实现等多角度,系统分析 C 语言中的宏(macro)与内联函数(inline function)的区别、优劣势和最佳设计方法。
1. 主题原理与细节逐步讲解
1.1 宏(Macro)
- 宏是由预处理器(preprocessor)在编译前简单文本替换实现的定义。
- 常用形式:
#define SQUARE(x) ((x)*(x)) - 宏不做类型检查、不分配存储空间、不产生函数调用开销。
1.2 内联函数(Inline Function)
- 内联函数是由编译器在合适时将函数体“嵌入”调用点,避免函数调用的栈开销。
- C99 标准引入 inline:
inline int square(int x) { return x*x; } - 内联函数有类型检查、作用域和函数语义,可能不被编译器实际内联(视具体实现和优化级别)。
2. 相关C语言典型陷阱/缺陷说明及成因剖析
2.1 宏的典型陷阱
2.1.1 参数副作用
- 宏展开时,参数表达式可能被多次求值,易引发副作用或性能损失。
#define SQUARE(x) ((x)*(x)) int a = 2; int b = SQUARE(a++); // 展开为 ((a++)*(a++)), 结果不可预测
2.1.2 运算优先级
- 宏文本替换不加括号易出错。
#define MUL(a, b) a*b int x = MUL(1+2, 3+4); // 实际为 1+2*3+4,优先级混乱
2.1.3 隐藏类型和作用域问题
- 宏不会做类型检查,不易调试。
- 宏定义中局部变量作用域混乱,易命名冲突。
2.1.4 调试和错误定位困难
- 错误发生在宏展开后,调试信息不明确,定位困难。
2.2 内联函数的陷阱与局限
2.2.1 内联并非强制
inline只是请求,编译器可选择是否真正内联,特别是有递归、复杂控制流时一般不会内联。
2.2.2 可移植性和多重定义问题
- 不同编译器对 inline 支持和语义存在差异,链接时可能遇到多重定义或未定义引用。
2.2.3 代码膨胀
- 过度内联会导致二进制膨胀(code bloat),影响指令缓存效率。
3. 规避方法与最佳设计实践
3.1 宏的安全编写规范
- 加括号包裹参数与整个宏定义,防止优先级错误。
#define SQUARE(x) ((x)*(x)) - 不要在宏参数中传递有副作用的表达式(如自增、自减、函数调用等)。
- 避免宏中定义局部变量,如需复杂操作,建议用 do-while(0) 包裹以保证单语句行为。
- 使用大写字母和下划线命名,明确区分宏与函数/变量。
3.2 内联函数的最佳实践
- 对频繁调用的短小函数(如 getters/setters、数学运算),优先用 inline 函数。
- 保持内联函数体简短,避免递归和复杂循环。
- 在头文件中定义 inline 函数时使用
static inline避免多重定义。static inline int square(int x) { return x * x; } - 保持函数接口类型安全,享受类型检查和调试友好性。
3.3 两者选用建议
- 涉及副作用参数、复杂逻辑时,优先用内联函数替代宏。
- 简单常量、条件编译、代码片段插入等场景,宏仍有不可替代性。
- 代码库要统一规范,避免混用、滥用。
4. 典型错误代码与优化后正确代码对比
错误代码1:宏副作用和优先级问题
#define SQUARE(x) x*x
int a = 3;
int res = SQUARE(a+1); // 实际为 3+1*3+1 = 3+3+1 = 7,错误
int b = 2;
int val = SQUARE(b++); // 展开为 b++*b++,b 会自增两次
优化后正确代码
#define SQUARE(x) ((x)*(x))
int a = 3;
int res = SQUARE(a+1); // ((3+1)*(3+1)) = 16
// 但仍不推荐 SQUARE(b++),副作用问题依旧
// 推荐用内联函数
static inline int square(int x) { return x*x; }
int val = square(b++); // b 只自增一次,类型安全,易调试
错误代码2:头文件内联函数未加 static,导致链接错误
foo.h
inline int foo(int x) { return x+1; } // C99下,多个.c包含会链接失败
bar.c
#include "foo.h"
int bar() { return foo(3); }
正确代码
foo.h
static inline int foo(int x) { return x+1; }
bar.c
#include "foo.h"
int bar() { return foo(3); }
5. 必要底层原理补充
- 宏在预处理阶段完成,文本替换后再由编译器编译,完全无类型、作用域、语义检查。
- 内联函数在编译阶段由编译器决定是否直接插入调用点,对类型、作用域、符号表有完整检查,调试器可跟踪。
- 现代编译器常会自动做内联优化(即便未加
inline),但加inline可提示优化器更积极地考虑。
6. SVG辅助图:宏与内联函数流程对比
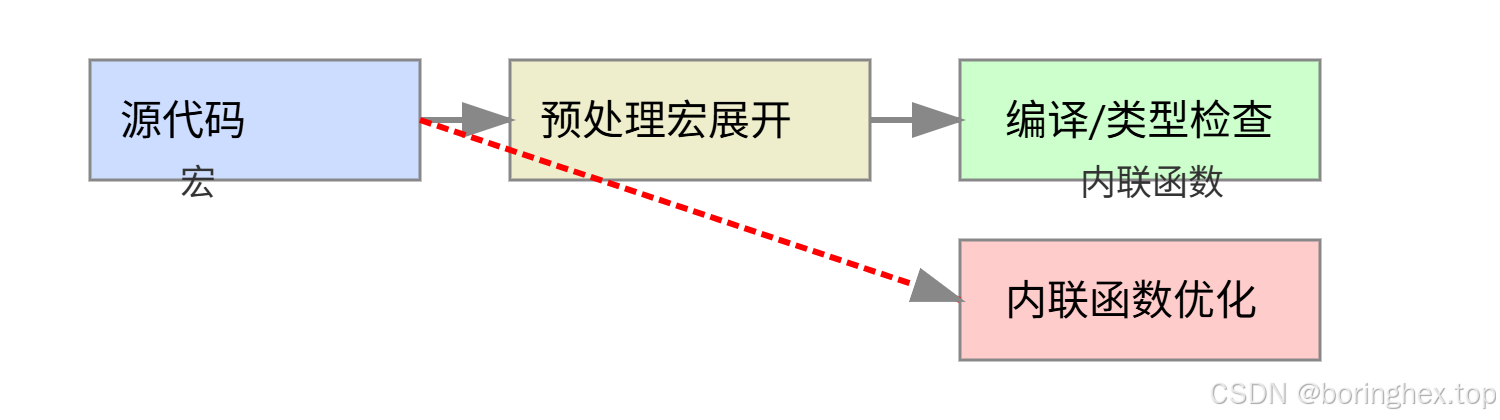
图示说明:宏在预处理阶段直接展开,内联函数在编译阶段优化插入,类型检查完整。
7. 总结与实际建议
- 宏不做类型检查、多次求值副作用极大,易出难查Bug,仅适合简单常量或短代码片段。
- 内联函数类型安全、调试友好,推荐用于短小、频繁调用的逻辑。
- 头文件定义内联函数需加
static inline,防止多重定义。 - 复杂逻辑、涉及副作用参数,务必用内联函数或普通函数,避免用宏。
- 团队代码规范要明确宏与内联函数的边界,防止混用带来维护隐患。
结论:正确区分和使用宏与内联函数,是写出高效、安全、可维护C代码的关键。宏只用于不能用函数替代的场景,业务逻辑、性能关键路径首选内联函数。
公众号 | FunIO
微信搜一搜 “funio”,发现更多精彩内容。
个人博客 | blog.boringhex.top


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









