



 本文探讨了机器学习与人工智能的基础原理及应用,介绍了计算机视觉中的图像处理技术,解析了自然语言处理中的语言理解与生成方法,并讨论了机器人技术的发展现状。
本文探讨了机器学习与人工智能的基础原理及应用,介绍了计算机视觉中的图像处理技术,解析了自然语言处理中的语言理解与生成方法,并讨论了机器人技术的发展现状。
本系列为作者学习记录
感谢Jack-Cui视频的启发
视频地址:【计算机科学速成课】[40集全/精校] - Crash Course Computer Science
系列文章目录
从零开始的自我提升计划:计算机科学(一)
从零开始的自我提升计划:计算机科学(二)
从零开始的自我提升计划:计算机科学(三)
从零开始的自我提升计划:计算机科学(四)
从零开始的自我提升计划:计算机科学(五)
从零开始的自我提升计划:计算机科学(六)
从零开始的自我提升计划:计算机科学(七)
从零开始的自我提升计划:计算机科学(八)
前言
本文内容包括:
- 机器学习与人工智能-Machine Learning & Artificial Intelligence
- 计算机视觉-Computer Vision
- 自然语言处理-Natural Language Processing
- 机器人-Robots
一、机器学习与人工智能
机器学习算法让计算机可以从数据中学习,然后自行作出预测和决定。机器学习算法的应用之一就是分类,用来分类的算法叫做“分类器”,虽然我们可以直接使用图片等信息来训练,但是大多数算法会简化信息,将数据简化为“特征”。我们需要使用标记的数据来训练分类器,利用一些条件来达成分类,这些条件就是“决策边界”。如图中,记录正确数和错误数的表叫做“混淆矩阵”,机器学习算法的目的是最大化正确分类并且最小化错误分类。得到模型后,我们可以使用分类器来推测未标记数据的种类。

这种把决策空间切割成几个盒子的简单方法可以使用“决策树”来表示,生成决策树的机器学习算法需要选择用什么特征来分类,每个特征使用什么值。有些算法使用多个决策树来预测,因此这些算法称为“森林”。
也有一些不适用树的方法,例如“支持向量机”,本质上是使用任意线段来切分决策空间,不一定是直线,也可以使多项式或者其他数学函数,机器学习算法负责找到最准确的决策边界。当特征数量与分类种类数量较多时,决策空间将会变得十分复杂,因为决策边界将会变成“超平面”,没有很好的办法可视化。
决策树和支持向量机这些算法发源自统计学,也有不使用统计学的方法,例如人工神经网络。人工神经元可以接受多个输入,整合处理后得到一个输出,它们被放置成一层一层的结构,组成神经网络。神经网络的第一层是输入层,提供需要被分类目标的数据,最后一层是输出层,输出分类结果。输入层和输出层之间有若干隐藏层,来将输入转化为输出。神经元接受到输入数据后,将每个输入乘以权重求和后再加入一个偏置,然后经过一个激活函数处理。这些权重和偏置在训练中会得到不断的优化。
有些只能做特定任务的算法称为“弱AI”或者“窄AI”。真正通用的,像人一样聪明的AI叫做“强AI”,目前没人能做出来,有人也认为做不出来。AI不仅可以吸收大量信息,也可以不断学习进步,而且一般比人类要快得多。
学习什么有用,什么无用,自己发现成功的策略,这叫“强化学习”,是一种非常强大的学习方法。
二、计算机视觉

计算机视觉目的是让计算机理解图像和视频。最简单的计算机视觉算法是跟踪一个颜色物体,记录物体最中心像素的RGB值,然后给程序输入图像,让程序寻找最接近这个颜色的像素,计算和目标颜色的差异,事实上不止图片,我们可以在视频的每一帧图片都运行这个算法来跟踪球的位置。但是这种算法会受到许多因素的影响,例如光照或者环境颜色,因此很少使用这类颜色跟踪算法,除非环境可以严格控制。
这种颜色跟踪算法不适合占有多个像素的特征,例如物体的边缘,是由多个像素组成的,为了识别这些特征,算法需要在一个个像素区域来处理,每个区域都叫“块(patch)”。例如垂直边缘检测算法,某像素是垂直边缘的可能性取决于左右两边像素颜色的差异,左右像素差异越大,这个像素越可能是边缘,这个算法的检测算子如图所示。
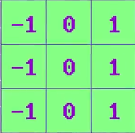
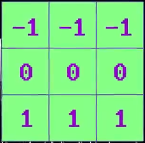
这个检测算子叫“核”或者“滤波器”,把核应用于像素块进行计算的操作叫“卷积”,如果将检测算子用于图片的所有块,会发现图中的垂直边缘像素值很高,其他部分几乎看不见。想要检测不同的部分,需要选用不同的核来进行。这两个边缘检测的核叫“Prewitt算子”,以发明者的名字命名。有许多不同的核能进行不同的图像转换,例如有的核可以锐化图像,有的可以模糊图像。
如今非常热门的算法是“卷积神经网络(CNN)”,神经网络中的核与预定义的不同,可以学习对自己有用的核来识别图像中的特征,CNN使用一堆神经元来处理图像,每个神经元都会输出一个新图像,输出再被下一层神经元处理,随着层数增多,特征的复杂度也逐渐增加,直到某一层把所有特征放在一起,然后输出分类结果。
用人脸识别举例,使用算法识别出脸之后,可以使用其他算法来定位面部标志,比如眼角、嘴角等位置,就得到了定位点。有了这些定位点,就可以判断眼睛是否张开,只需要判断标志点之间的距离即可。根据嘴部的标志点可以检测微笑,根据眉毛的标志点可以判断出表情等。这些面部标记点也可以用来进行生物识别,让有摄像头的计算机认出你。此外,跟踪人身体部位的标记点也有较大突破,让计算机理解用户的肢体语言。
三、自然语言处理

自然语言处理(NLP)的目的是让计算机理解语言。早期NLP的一个基本问题是如何将句子切块,这样更容易处理。通过单词词性可以一定程度上划分句子成分,但是无法解决有些单词具有多重含义的问题。所以电脑也需要知道语法,于是开发了“短语结构规则”来代表语法规则,利用这些规则可以做出分析树,标明句子的结构。计算机可以回答问题并且处理命令,但是当句子复杂一点,就无法理解了。“短语结构规则”和其他把语言结构化的方法也可以用来生成句子,数据存在语义信息网络时,这种方法特别有效,语句实体连接在一起,提供构造句子的所有成分。处理,分析,生成文字是聊天机器人的最基本部件,早期的聊天机器人大多数使用规则,专家把用户可能说的话和机器人应该回复什么写成大量的规则,显然这很难维护并且对话不能太复杂。如今聊天机器人多数使用机器学习,用真人聊天数据来训练机器人。
使计算机从声音中提取词汇,这个领域就是“语音识别”。贝尔实验室在1952年开发出了第一个语音识别系统——自动数字识别器,但是要求输入语音十分慢。后来IBM也推出了自己的语音识别系统,总之在那时,语音转文字,经常要比实时说话要慢十倍或以上。在1980,1990年代,计算机性能的大幅提升使得实时语音识别可行,同时也出现了NLP的新算法,不制定规则,而是使用机器学习。通过观察元音的波形,可以看出不同声音之间波形的差异,使用“频谱图”来观察可以更加直观的看出区别,这种时频转换是通过**快速傅里叶变换(FFT)**做到的,不同元音的频谱图的峰值有所不同,可根据这个差异来识别元音,进而识别出整个单词。通过观察句子的频谱,可以看出不同“因素”的片段,进而划分出不同的单词。
因为口音和发音错误等原因,人们说单词的方式有所不同,所以结合语言模型后,语音转文字的准确度会大大提高。让计算机输出语音即“语音合成”,它与语音识别十分相似,但是过程相反。
四、机器人

机器人是由计算机控制,可以自动执行一系列动作的机器。早期有许多不用电的自动装置,叫做“自动机”,例如法国的“吃饭鸭”,它是一个像鸭子的机器,能吃东西然后排便。第一台计算机控制的机器,出现在1940年代晚期,这些计算机数控机,简称CNC机器可以执行一连串程序指定的操作。第一个商业贩卖的可编程工业机器人叫Unimate,它可以把压铸机做出来的热金属成品提起来然后堆起来,机器人行业由此开始,很快,机器人开始做越来越多的工作。
对于简单的运动,例如机械爪在轨道上来回移动,可以指示移动的位置,这种行为可以用简单控制回路完成,通过不断的判断机器人的位置来控制电机。因为在不断缩小当前位置和目标位置的距离,因此也叫“负反馈回路”。但是这种简单的回路因为其他因素的影响可能会导致机械爪在目标位置周围来回震荡,因此需要更加复杂的控制逻辑,即“比例-积分-微分控制器”,简称PID控制器。PID控制器通过当前状态和目标状态之间的差距算出三个值,一是比例值,之前简单的控制回路就是使用比例值来控制的;二是积分值,就是一段时间内误差的总和,帮助弥补误差;三是微分值,是期望值和实际值之间的变化率,有助于解决未来可能出现的错误,也叫预期控制。这三个值会一起使用,每个值有不同的权重来控制机器。
近年来机器人领域最大的突破是无人驾驶汽车,无人驾驶汽车有许多传感器,它十分依赖计算机视觉算法。机器人发展越来越快,在军事等方便也有重要应用,因此产生了许多伦理道德问题。机器人三定律就是对机器人制定的一套行为准则,后面又加了定律0,这个定律让机器人不要伤害,特别是不要伤害人类。
总结
本文介绍了机器学习与人工智能、计算机视觉、自然语言处理以及机器人。

















 1646
1646

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









