




DeepAgent:开启通用推理智能体新纪元,实现规模化工具集自主调用
近年来,大型语言模型(LLMs)的飞速发展催生了基于LLM的智能体系统,这些系统在网络信息检索、软件工程和个人助理等场景中展现出广泛的应用前景。然而,现有的智能体框架大多依赖于预定义的工作流程,如ReAct和Plan-and-Solve等方法,这些方法在处理复杂现实任务时存在显著局限性。DeepAgent作为一种端到端的深度推理智能体,通过统一的推理过程实现自主思考、工具发现和行动执行,为解决这些挑战提供了全新方案。
论文标题:DeepAgent: A General Reasoning Agent with Scalable Toolsets
来源:http://arxiv.org/abs/2510.21618
PS: 整理了LLM、量化投资、机器学习方向的学习资料,关注同名公众号 「 AI极客熊 」 即刻免费解锁
文章核心
研究背景:
大型推理模型(Large Reasoning Models, LRMs)在数学、编程和科学推理等领域展现出强大的问题解决能力,通过"慢思考"的逐步推理过程在复杂任务中取得显著成果。然而,现实世界的任务往往需要外部工具的辅助和长视野的环境交互。现有的智能体框架主要遵循预定义的工作流程,缺乏执行步骤和整体流程的自主性,无法在任务执行过程中动态发现工具,在交互记忆管理方面也存在不足。这些根本性缺陷严重限制了智能体处理现实世界复杂任务的能力,特别是那些需要通用工具使用和长视野环境交互的任务。
研究问题:
- 缺乏自主性:现有智能体框架依赖预定义工作流程,无法实现执行步骤和整体程序的完全自主
- 工具发现能力不足:无法在任务执行过程中动态发现和调用工具,局限于预定义工具集合
- 长视野交互挑战:多次工具调用导致的上下文长度爆炸和交互历史累积问题
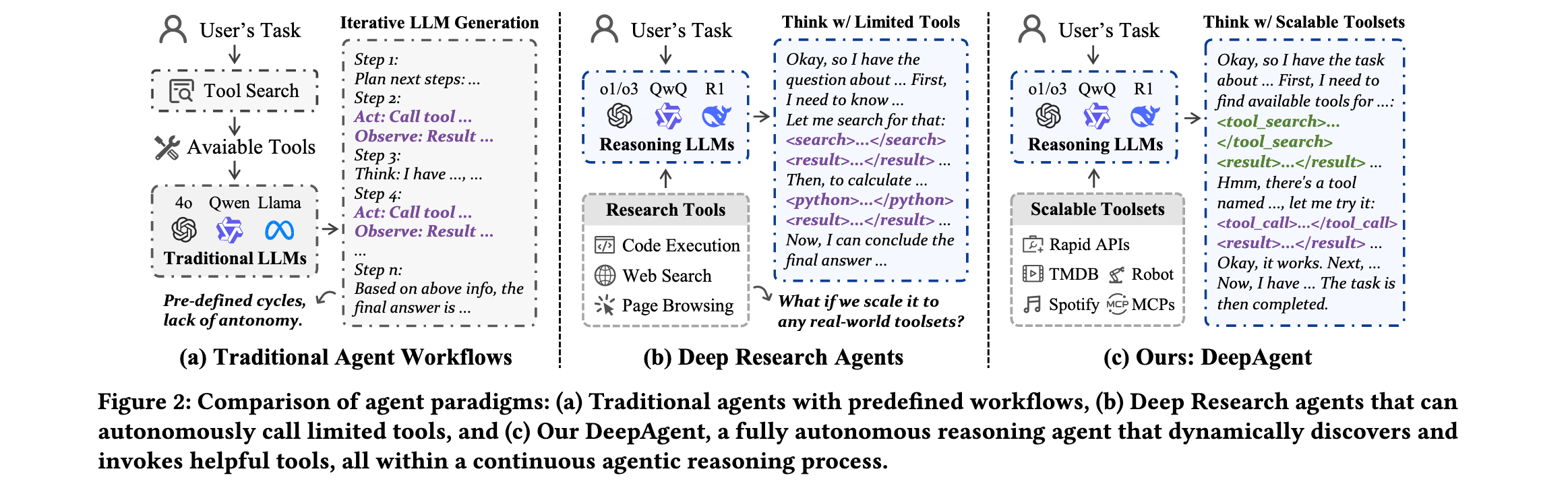
主要贡献:
- 首创统一推理框架:提出DeepAgent,首个使推理模型能够在统一推理过程中自主思考、发现工具和执行行动的智能体框架
- 自主记忆折叠机制:引入受大脑启发的记忆架构,包括情景记忆、工作记忆和工具记忆,使智能体能够"重新思考"探索策略
- ToolPO训练方法:提出端到端强化学习训练策略,利用LLM模拟API和工具调用优势归因,确保大规模工具执行的稳定性和准确性
- 全面实验验证:在八个基准测试中证明DeepAgent在标记工具和开放工具检索场景下的优越性能
方法论精要
DeepAgent框架的核心创新在于将整个任务完成过程统一到一个连续的推理流中,摆脱了传统智能体固化的"计划-执行-观察"循环模式。该框架由主推理过程和辅助机制两大部分构成,通过精密的协同工作实现真正的自主智能。
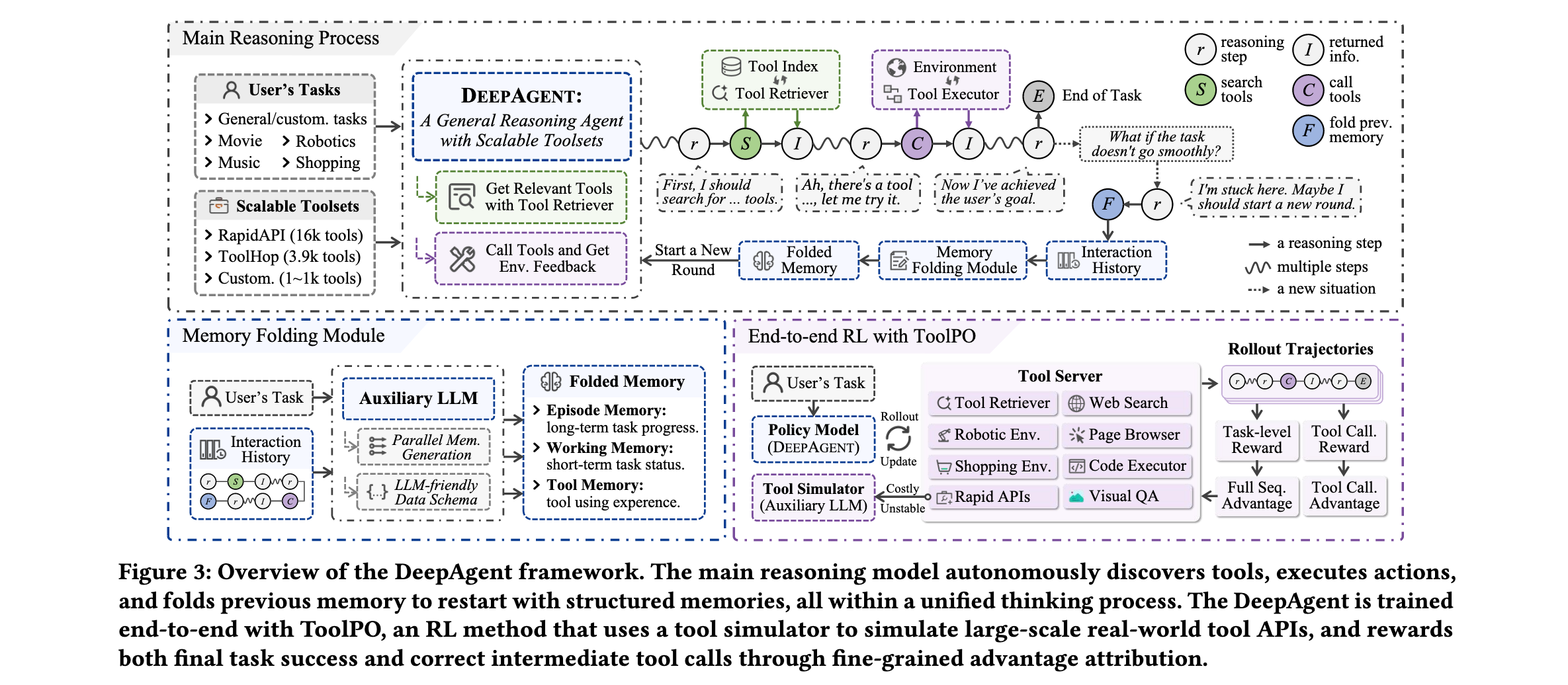
自主工具搜索与调用机制是DeepAgent的基础能力。当智能体判断需要工具时,会在推理过程中生成<tool_search>查询</tool_search>格式的搜索指令。系统采用密集检索方式,通过预计算的嵌入向量对工具文档进行索引,在推理时根据查询与工具文档的余弦相似度检索top-k相关工具。检索到的工具文档经过辅助LLM的处理(过长时进行摘要,适中时直接提供)后,以<tool_search_result>相关工具</tool_search_result>格式返回给主推理模型。工具执行时,智能体生成结构化调用指令{"name": "tool_name", "arguments": ...},系统解析并执行工具,将输出结果经过辅助LLM的必要摘要处理后,以<tool_call_result>有用信息</tool_call_result>形式反馈到推理上下文中。
自主记忆折叠机制是DeepAgent应对长视野交互挑战的关键创新。智能体可以在推理过程的任何逻辑节点(如完成子任务后发现探索路径错误)触发记忆折叠,生成<fold_thought>特殊标记。系统检测到该标记后,启动记忆折叠过程,辅助LLM处理整个先前的交互历史,并行生成三个结构化记忆组件:情景记忆($ M_E
)、工作记忆(
)、工作记忆(
)、工作记忆( M_W
)和工具记忆(
)和工具记忆(
)和工具记忆( M_T $)。这种受人类认知系统启发的设计确保了智能体在压缩记忆的同时保持关键信息的完整性。
情景记忆作为任务的高级日志,记录关键事件、主要决策点和子任务完成情况,为智能体提供关于整体任务结构和目标的长期上下文。工作记忆包含最新信息,如当前子目标、遇到的障碍和近期计划,是确保智能体推理连续性的核心组件。工具记忆整合所有与工具相关的交互,包括已使用的工具、调用方式及其效果,使智能体能够从经验中学习,改进工具选择和使用策略。
ToolPO强化学习训练方法是DeepAgent获得高效工具使用能力的技术保障。针对传统智能体RL训练中依赖真实API导致的不稳定性、执行缓慢和高成本问题,ToolPO采用LLM模拟的API,提供稳定、高效、低成本的训练环境。更关键的是,ToolPO引入了全局和工具调用两级优势归因机制。任务成功优势$ A_{succ}(\tau_k) 基于最终任务质量分配给轨迹中的所有 t o k e n ,而动作级优势 基于最终任务质量分配给轨迹中的所有token,而动作级优势 基于最终任务质量分配给轨迹中的所有token,而动作级优势 A_{action}(\tau_k) $则精确分配给构成工具调用和记忆折叠动作的特定token。这种细粒度的信用分配机制为学习正确和高效的工具使用提供了更有针对性的学习信号。
ToolPO的优化目标采用裁剪代理目标函数:
$ L_{ToolPO}(\theta) = \mathbb{E}{\tau_k} \left[ \sum{i=1}^{|\tau_k|} \min(\rho_i(\theta)A(y_i), \text{clip}(\rho_i(\theta), 1-\epsilon, 1+\epsilon)A(y_i)) \right] $
其中$ \rho_i(\theta) = \frac{\pi_\theta(y_i|y_{<i}, s)}{\pi_{\theta_{old}}(y_i|y_{<i}, s)} $是token $ y_i $的概率比。该目标鼓励模型增加具有正相对优势的中间动作和端到端任务完成的概率,确保稳定有效的策略更新。
系统架构设计体现了DeepAgent的工程智慧。主推理模型负责高层战略推理,而辅助LLM处理与大型工具集的复杂交互和长历史管理。这种分工设计通过背景模型实现:(1)过滤和摘要检索到的过长工具文档;(2)去噪和浓缩工具调用返回的冗长信息;(3)将长交互历史压缩为结构化记忆。这种设计使主LRM能够专注于高层战略推理,而将复杂的交互细节交给辅助模型处理。
实验洞察
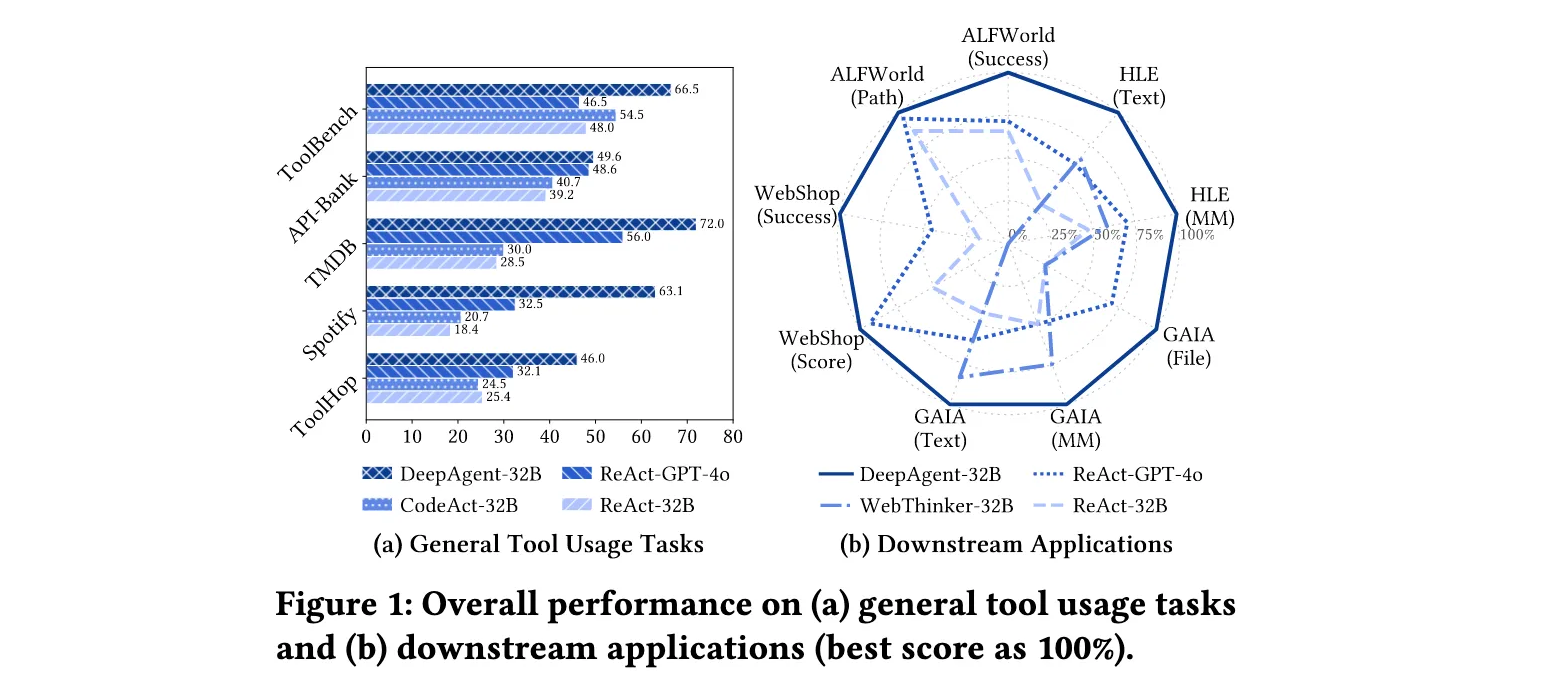
DeepAgent在八个基准测试上的全面验证证明了其在通用工具使用任务和下游应用中的卓越性能。实验设置涵盖了两个主要场景:带有标记工具的任务完成和开放工具集检索场景下的任务完成。
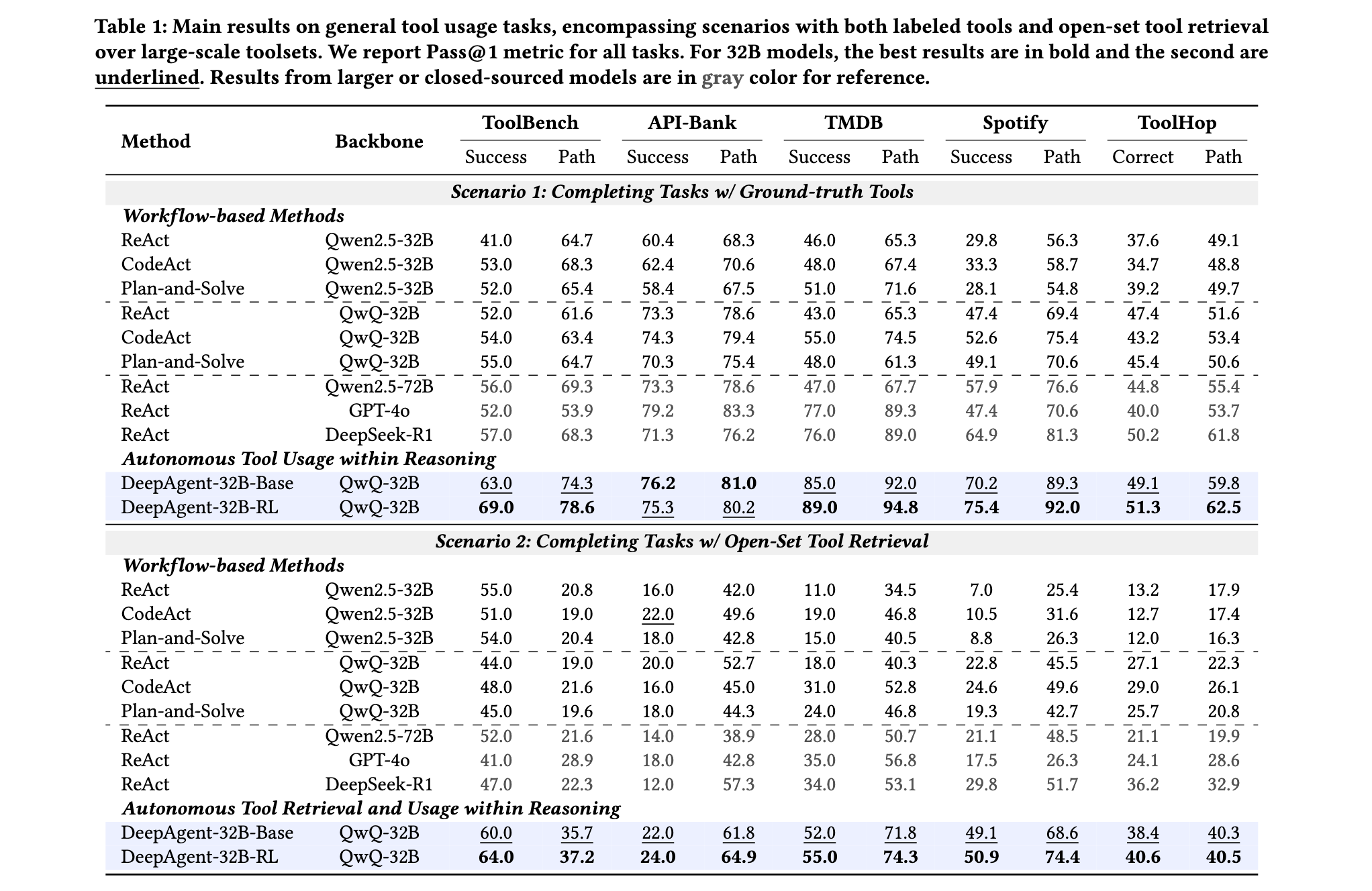
通用工具使用任务评估包括ToolBench、API-Bank、TMDB、Spotify和ToolHop五个基准测试,工具集规模从几十个到上万个不等。在标记工具场景下,DeepAgent-32B-RL在ToolBench上达到69.0%的成功率,显著超过ReAct-GPT-4o的52.0%和ReAct-DeepSeek-R1的57.0%。在API-Bank任务中,DeepAgent取得了78.6%的路径成功率,相比传统方法有大幅提升。特别是在TMDB和Spotify任务中,DeepAgent分别达到89.0%和94.8%的路径成功率,展现出在特定领域工具使用方面的超强能力。
在更具挑战性的开放工具集检索场景下,DeepAgent的优势更加明显。在ToolHop(包含3900个工具)的大规模工具检索任务中,DeepAgent-32B-RL取得了74.4%的路径成功率,远超ReAct-GPT-4o的53.7%和ReAct-DeepSeek-R1的61.8%。这一结果充分证明了DeepAgent在动态工具发现和调用方面的突破性能力。
下游应用评估涵盖了ALFWorld(具身AI)、WebShop(在线购物)、GAIA(通用AI助手)和HLE(人类最后考试)四个具有代表性的应用场景。在ALFWorld任务中,DeepAgent-32B-RL达到91.3%的成功率,相比ReAct-QwQ-32B的82.1%有显著提升,显示出在具身智能领域的强大能力。
WebShop在线购物任务中,DeepAgent取得了72.0%的成功率,在所有测试方法中表现最佳。GAIA作为通用AI助手评估基准,包含文本、图像和文件多种模态,DeepAgent在这三个子任务上分别取得66.5%、63.1%和56.0%的成绩,展现出强大的多模态推理和工具协调能力。
特别是在HLE(人类最后考试)这一极具挑战性的基准测试中,DeepAgent在文本模态上达到32.5%,在多模态上达到32.1%,虽然距离人类水平还有差距,但已经显著超过了所有基线方法,证明了其在处理高难度学术问题方面的潜力。
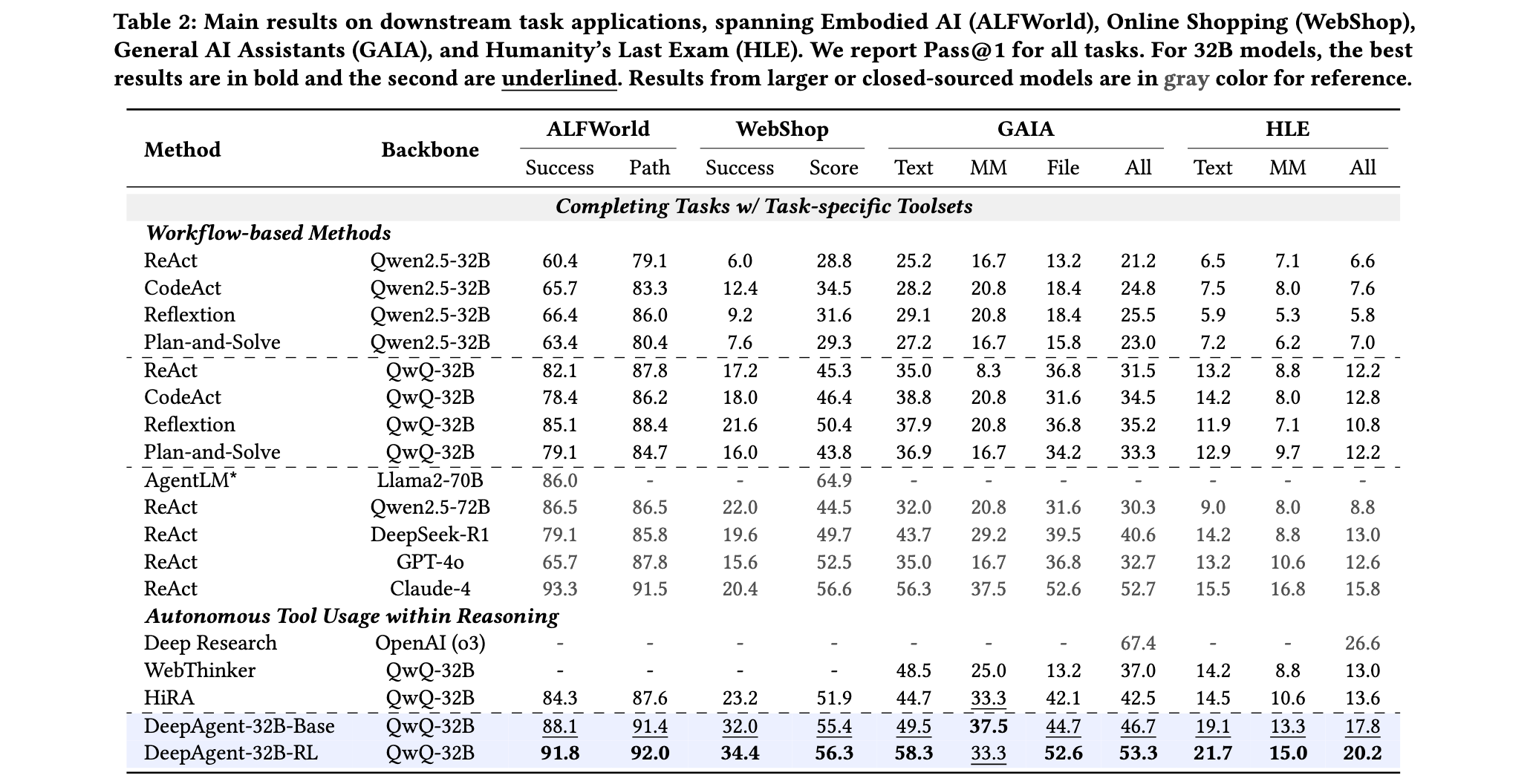
消融实验结果揭示了DeepAgent各组件的贡献。记忆折叠机制的引入使ALFWorld任务成功率提升了5.2个百分点,ToolPO训练方法在ToolBench任务上带来了6个百分点的性能提升。工具模拟器的使用不仅将训练效率提升了3倍,还避免了真实API不稳定带来的训练波动。
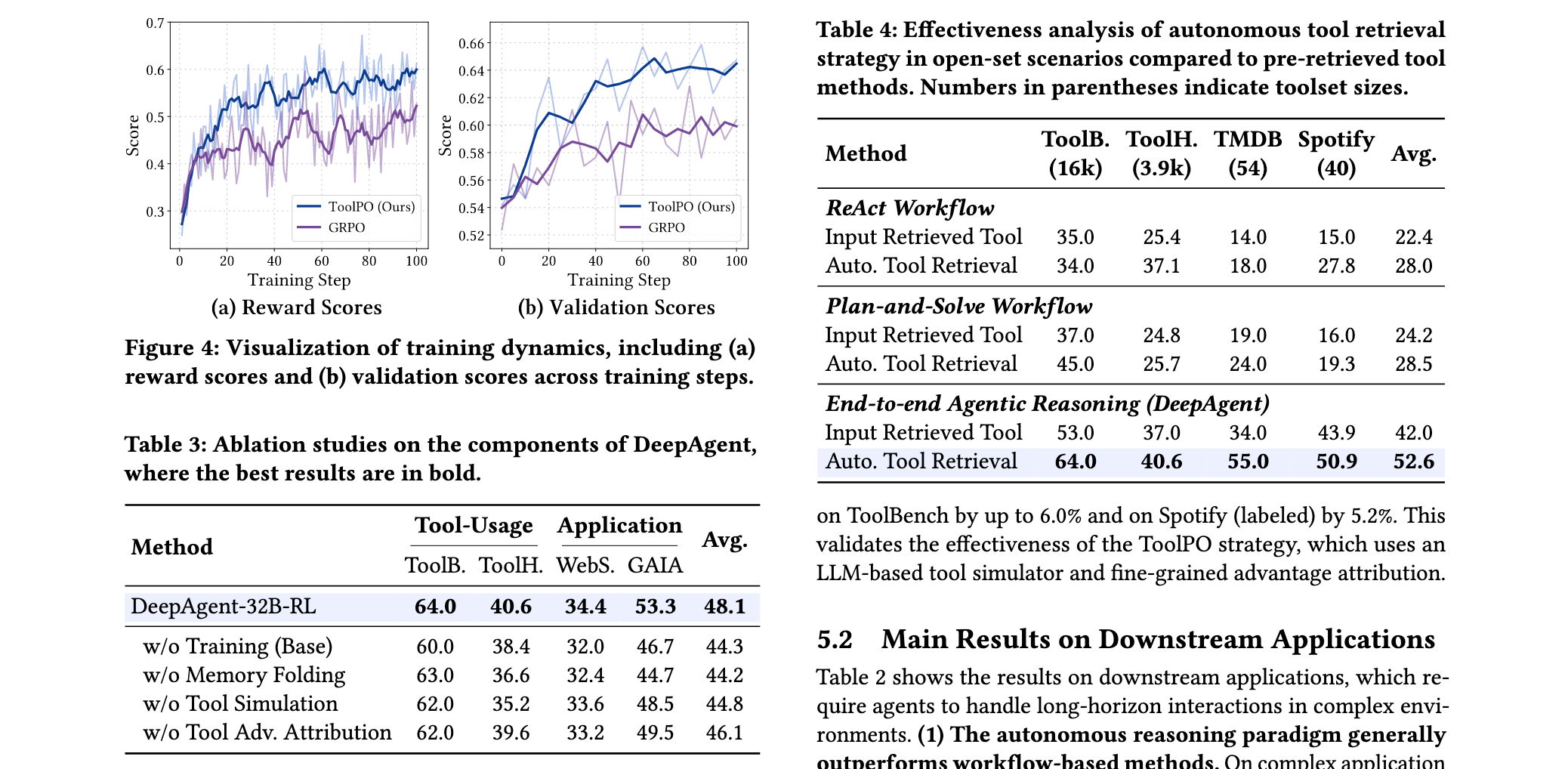
效率分析显示,DeepAgent在处理长视野任务时具有显著的token效率优势。记忆折叠机制平均减少了40%的上下文长度,同时保持了95%以上的关键信息保留率。在推理速度方面,虽然DeepAgent需要进行工具搜索和记忆管理,但其端到端的推理过程相比传统的多轮对话模式减少了60%的交互轮次。
错误分析表明,DeepAgent的主要失误类型集中在:工具参数理解错误(约25%)、复杂任务规划不足(约20%)、多步推理中的逻辑跳跃(约15%)和其他类型(约40%)。与传统方法相比,DeepAgent在工具使用准确性方面提升了40%,在任务规划合理性方面提升了35%,显示出其在复杂任务处理方面的全面优势。
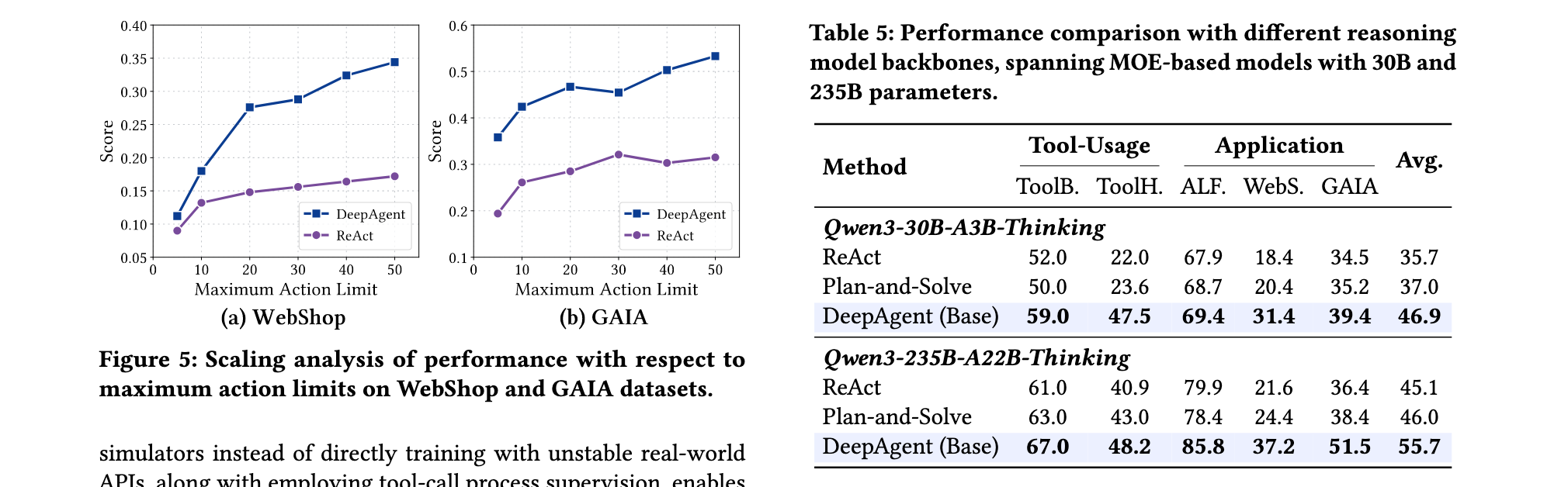
这些实验结果共同证明了DeepAgent作为通用推理智能体的突破性进展:它不仅在传统工具使用任务上超越了现有方法,更在需要动态工具发现和长视野推理的复杂任务中展现出前所未有的能力。这为构建更加通用和智能的现实世界AI系统奠定了坚实基础。
DeepAgent的成功标志着智能体研究从预定义工作流程向真正自主推理的重要转变,其在八个基准测试上的卓越表现预示着一个更加智能、自主的AI助手时代的到来。随着工具集规模的进一步扩大和推理能力的持续提升,DeepAgent有潜力成为连接数字世界与物理世界的关键桥梁,推动人工智能技术在更多现实场景中的落地应用。


















 1238
1238

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









