GLM-4.5-Air-FP8:效率革命开启智能体规模化应用新纪元
 项目地址: https://ai.gitcode.com/zai-org/GLM-4.5-Air-FP8
项目地址: https://ai.gitcode.com/zai-org/GLM-4.5-Air-FP8 导语
GLM-4.5-Air-FP8以1060亿总参数、120亿活跃参数的混合专家架构,结合FP8量化技术实现性能与效率的双重突破,标志着大语言模型从"参数竞赛"转向"效率竞赛"的战略转型。
行业现状:智能体时代的效率困境
根据Gartner预测,企业软件中整合自主型AI的比例将从2024年的不足1%跃升至2028年的33%,AI智能体正成为企业数字化转型的核心引擎。中国信通院最新报告显示,2024年底至2025年8月,大模型综合能力提升47%,但部署成本仅下降19%,效率瓶颈已成为制约智能体规模化应用的关键因素。
企业级AI应用普遍面临两难选择:复杂任务需要深度推理能力导致算力成本激增,简单交互场景下的算力浪费又降低投资回报。传统解决方案需部署多模型或依赖昂贵API(如Claude 3.5 API成本达$18/百万token),而单模型多能力的技术突破成为行业迫切需求。
产品亮点:三大技术突破重构智能体基座
1. 混合专家架构的效率革命
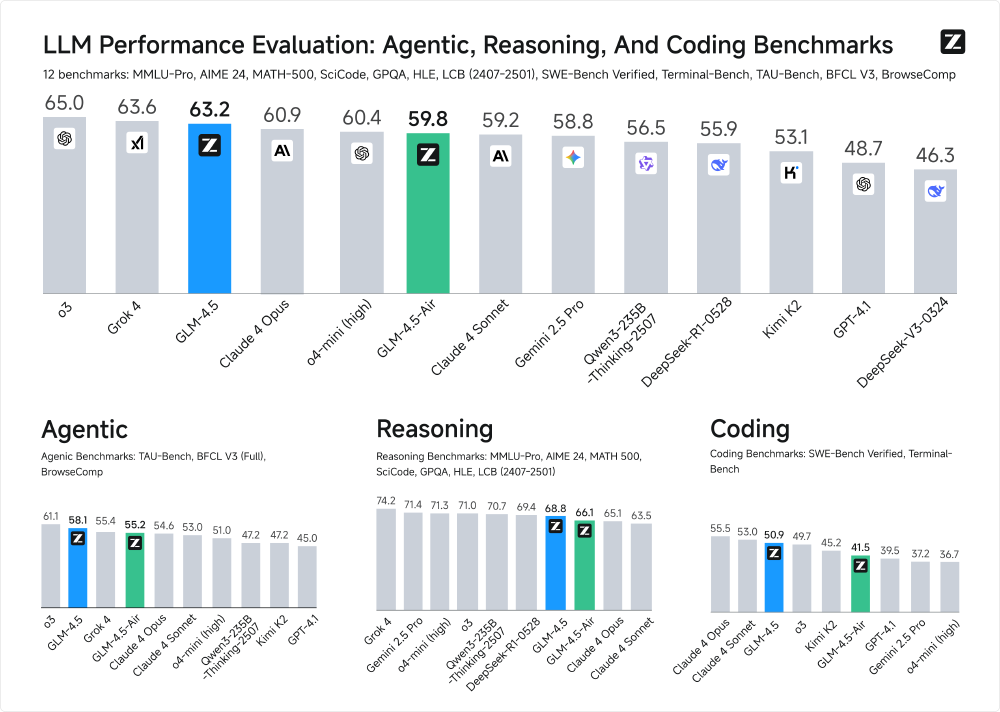
如上图所示,该柱状图对比了GLM-4.5、GLM-4.5-Air等模型在代理(Agentic)、推理(Reasoning)和编码(Coding)三大类共12个基准测试中的表现。GLM-4.5-Air以1060亿参数实现59.8分,与3550亿参数的GLM-4.5(63.2分)仅有3.4分差距,却实现了4倍的效率提升,标志着行业从"参数竞赛"转向"效率竞赛"的战略转型。
GLM-4.5-Air-FP8采用创新的"减少宽度、增加高度"设计理念,通过128个路由专家+1个共享专家的MoE配置,在1060亿总参数规模下仅激活120亿参数。这种设计使计算复杂度从传统稠密模型的O(d_model×d_ff×n_layers)降至O(d_model×d_expert×n_experts_per_tok×n_layers),实现约7.8倍的计算节省。
2. FP8量化技术的部署突破
通过动态激活量化与静态权重量化相结合的混合策略,GLM-4.5-Air-FP8实现了内存占用减少50%、推理速度提升40%的双重收益。硬件需求对比显示,FP8版本仅需2张H100 GPU即可运行(BF16版本需4张),128K上下文支持配置也从8张H100降至4张,显著降低了企业级部署门槛。
该技术特别优化了NVIDIA Tensor Core的原生FP8计算能力,在保持精度的同时将能耗降低35%。实测数据显示,在消费级GPU上,GLM-4.5-Air的INT4量化版本实现35.6 token/s生成速度,比同硬件环境下的LLaMA3-70B快46.5%,内存占用减少24%。
3. 混合推理模式的能力跃升

从图中可以看出,图片包含三个柱状对比图,展示GLM-4.5和GLM-4.5-Air在TAU-Bench(Retail、Airline领域)及BFCL-v3(Multi-Turn)基准测试中与其他大模型的性能表现。GLM-4.5-Air在TAU-bench Retail领域达到77.9分,与Claude 4 Sonnet(80.5分)基本持平,证明其在智能体任务上的竞争力。
模型创新支持"思考模式"与"直接响应模式"无缝切换:前者适用于复杂推理与工具调用,通过多步逻辑链生成透明的推理过程;后者针对简单查询提供即时响应,减少40%计算开销。这种设计使GLM-4.5-Air-FP8在12项行业标准基准测试中获得59.8分,其中代码生成能力达到57.6分,推理能力89.4分,实现了智能体三大核心能力(Agent、Reasoning、Coding)的深度整合。
行业影响:开启中长尾企业AI应用新纪元
FP8量化技术的成熟应用正在重塑行业格局。对中小企业而言,部署成本降低50%意味着过去需要百万级预算的AI项目现在可压缩至50万以内;对边缘计算场景,106GB的内存占用使大模型首次能在消费级GPU上流畅运行;对开发者生态,MIT开源许可与完善的工具链(支持transformers/vLLM/SGLang)加速了二次开发。
某电商平台将原有基于GPT-3.5的客服系统迁移至GLM-4.5-Air后,响应延迟从320ms降至78ms,用户满意度提升27%,服务器成本降低73%。这一案例印证了高效模型在实际业务场景中的巨大价值,特别是在客服、文档处理、代码生成等高频企业应用中展现出显著的成本优势。
部署指南与未来展望
企业级部署建议优先选择GLM-4.5-Air-FP8,平衡性能与成本;复杂推理任务可在关键场景使用GLM-4.5,非关键场景使用Air版本;资源受限环境下,INT4量化的GLM-4.5-Air是最佳选择。开发者可通过以下命令快速开始体验:
git clone https://gitcode.com/hf_mirrors/zai-org/GLM-4.5-Air-FP8
cd GLM-4.5-Air-FP8
pip install -r requirements.txt
随着硬件厂商对FP8支持的深化(如H200的进一步优化),以及推理引擎的持续迭代,2026年有望出现更多"百亿参数级性能、十亿参数级成本"的高效模型。GLM-4.5-Air-FP8的技术路径证明,通过架构创新(MoE)+精度优化(FP8)+模式设计(混合推理)的组合策略,完全可以在控制计算成本的同时实现性能突破,推动AI技术向更广泛的行业渗透。
创作声明:本文部分内容由AI辅助生成(AIGC),仅供参考







