



引言
【Z-Image-Turbo】(https://huggingface.co/Tongyi-MAI/Z-Image-Turbo) 是阿里巴巴通义团队最新推出的高性能文生图模型,基于 Diffusion Transformer (DiT) 架构,6B参数量,仅需不到10个steps的采样,就能够快速生成高质量图像。本文将详细介绍如何使用 Intel® OpenVINO™ 工具套件来优化和部署 Z-Image-Turbo 模型,在 Intel平台上上获得出色的推理性能。

内容列表
1. 环境准备
2. 模型下载和转换
3. 模型部署
第一步,环境准备
基于以下命令可以完成模型部署任务在Python上的环境安装。
python -m venv py_venv./py_venv/Scripts/activate.batpip uninstall -y optimum transformers optimum-intel diffuserspip install git+https://github.com/huggingface/diffuserspip install git+https://github.com/openvino-dev-samples/optimum-intel.git@zimagepip install nncfpip install torch==2.8.0 torchvision==0.23.0 torchaudio==2.8.0 --index-url https://download.pytorch.org/whl/cpupip install openvino==2025.4
第二步,模型下载和转换
在部署模型之前,我们首先需要将原始的PyTorch模型转换为OpenVINO™的IR静态图格式,并对其进行压缩,以实现更轻量化的部署和最佳的性能表现。通过Optimum提供的命令行工具optimum-cli,我们可以一键完成模型的格式转换和权重量化任务:
optimum-cli export openvino --model Tongyi-MAI/Z-Image-Turbo --task text-to-image Z-Image-Turbo-ov --weight-format int4 --group-size 64 --ratio 1.0其中Tongyi-MAI/Z-Image-Turbo为模型在HuggingFace上的model id, 可用原始模型的本地路径替换;--weight-format int4 --group-size 64 --ratio 1.0为模型量化参数,如果考虑出图质量,也可以用--weight-format fp16 替换。
第三步,模型部署
除了利用Optimum-cli工具导出OpenVINO™模型外,我们还在Optimum-intel中重构了Z-Image模型的Pipeline,将官方示例示例中的的ZImagePipeline替换为OVZImagePipeline便可快速利用OpenVINO™进行模型部署,完整示例可参考以下代码流程。
import torchfrom optimum.intel import OVZImagePipeline# 1. Load the pipelinepipe = OVZImagePipeline.from_pretrained("Z-Image-Turbo-ov", device="cpu")prompt = "Young Chinese woman in red Hanfu, intricate embroidery. Impeccable makeup, red floral forehead pattern. Elaborate high bun, golden phoenix headdress, red flowers, beads. Holds round folding fan with lady, trees, bird. Neon lightning-bolt lamp (⚡️), bright yellow glow, above extended left palm. Soft-lit outdoor night background, silhouetted tiered pagoda (西安大雁塔), blurred colorful distant lights."# 2. Generate Imageimage = pipe(prompt=prompt,height=512,width=512,num_inference_steps=9, # This actually results in 8 DiT forwardsguidance_scale=0.0, # Guidance should be 0 for the Turbo modelsgenerator=torch.Generator("cpu").manual_seed(42),).images[0]image.save("example_zimage_ov.png")
生图结果如下:

除此以外我们在OpenVINO™ notebook仓库中构建了更为完整的demo示例,展示效果如下:
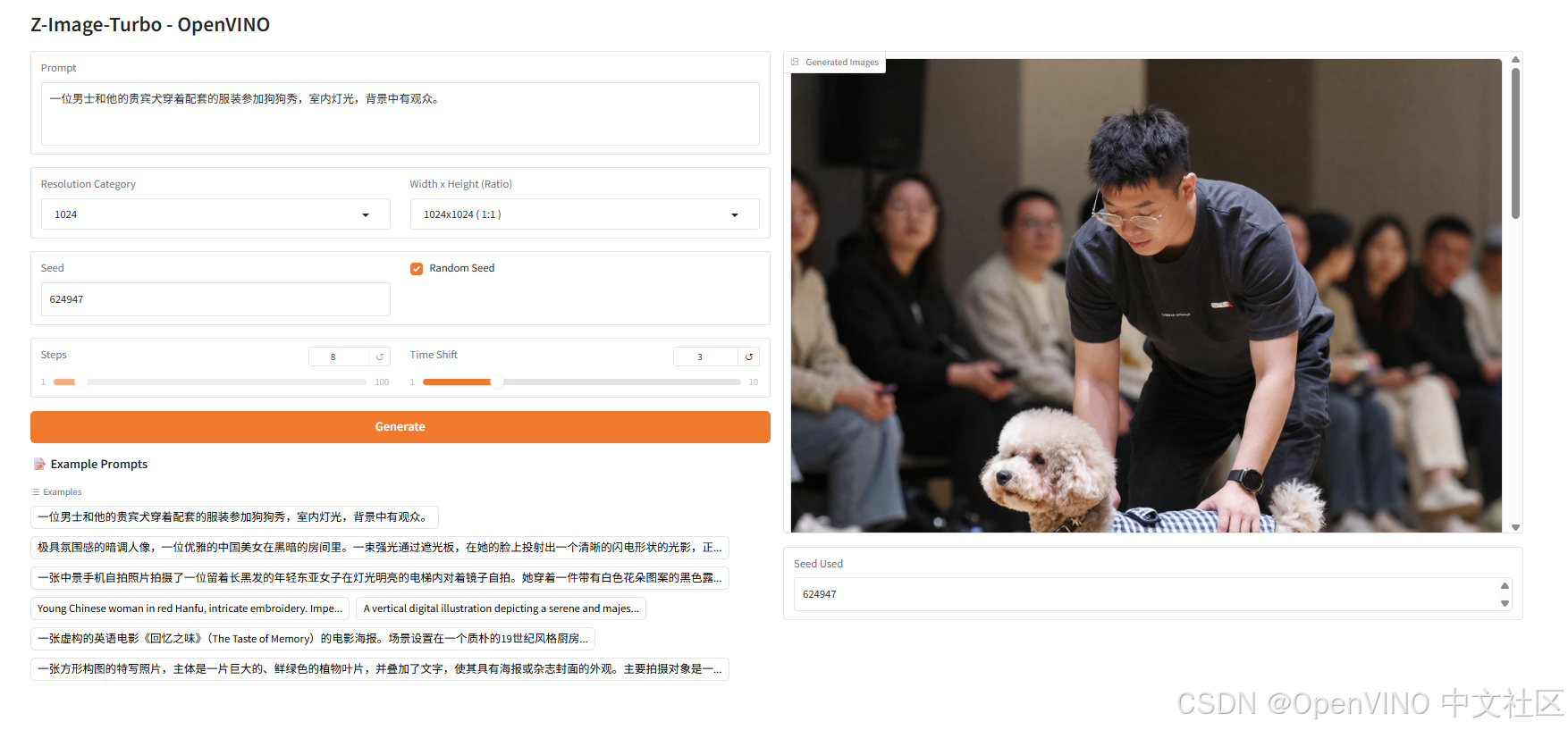
总结
本文详细介绍了如何使用 OpenVINO™ 部署通义Z-Image-Turbo 模型,OpenVINO™为 Z-Image-Turbo 提供了显著的性能提升,作为轻量化模型的代表,Z-Image-Turbo特别适合在 Intel CPU/GPU 上进行推理部署。
参考资源
-
【Z-Image-Turbo 模型卡片】https://huggingface.co/Tongyi-MAI/Z-Image-Turbo
-
【OpenVINO™ 官方文档】https://docs.openvino.ai/
-
【Optimum Intel GitHub】https://github.com/huggingface/optimum-intel
-
【Diffusers 库文档】https://huggingface.co/docs/diffusers

















 185
185

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









