



随着这精彩纷呈的一年即将走到尾声,我们也迎来了 2025 年度最后一个 OpenVINO™ 版本发布。这是我们今年发布的第五个版本,开发团队一直夜以继日地工作,只为在 Intel® 硬件上为你带来最佳的优化体验。从全新的生成式 AI 能力、不断扩展的 NPU 支持,到持续增强的模型性能,每一次发布都在前一版本的基础上迭代升级,逐步构建出一个完整的工具包,赋能像您这样的开发者。我们也十分感激这一路上选择将 OpenVINO™ 作为自己 AI 旅程一部分的开发者与创新者社区;是你们持续的信任与反馈,指引着我们前进。现在,让我们一起看看本次版本如何继续推动我们的使命——让 AI 模型在 Intel 硬件上的部署变得更快、更高效、更易用。
目录
1. 新模型和应用场景
2. 扩展 GenAI 能力以更好支持 Agentic智能体集成
3. 加密Blob格式支持
4. 性能提升
新模型和应用场景
本次版本在 CPU 和 GPU 上引入了多款经过优化的新模型,以满足不同的 AI 需求:
-
Qwen3-Embedding-0.6B 和 Qwen3-Reranker-0.6B:非常适合用于构建高精度的 RAG 流水线,更好地理解查询并检索相关上下文。
-
Mistral-Small-24B-Instruct-2501:一款小巧而强大的大语言模型,适用于算力资源受限但仍需要快速响应的场景。
-
在 NPU 上,我们通过 Gemma-3-4b-it 和 Qwen2.5-VL-3B-Instruct 等模型进一步扩展了多模态覆盖,为边缘部署提供更高的灵活性。
这些模型可以与 OpenVINO™ GenAI 中的 TextEmbeddingPipeline、TextRerankPipeline 等流水线无缝集成——只需几行代码即可开始使用。
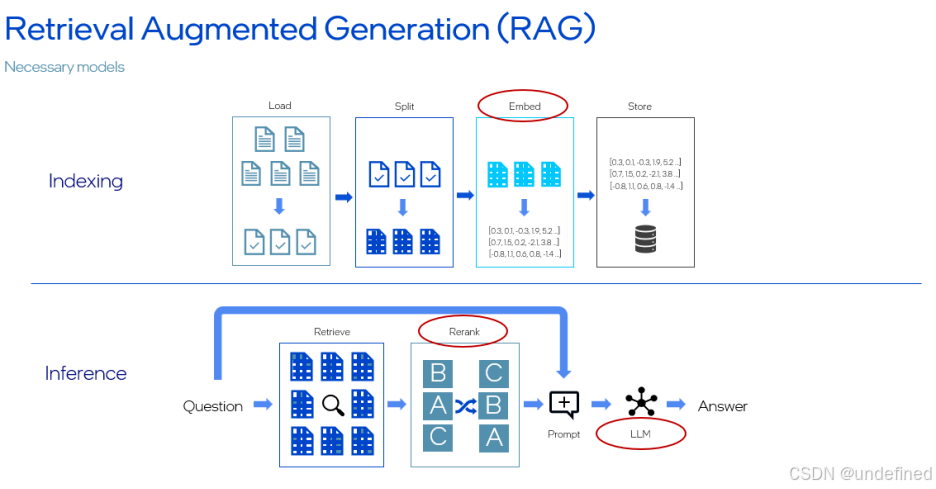
TextRerankPipeline(https://github.com/openvinotoolkit/openvino.genai/blob/master/samples/python/rag/text_rerank.py)代码示例
本次版本中最令人兴奋的特性之一,是在 CPU 和 GPU 上对 Mixture of Experts(MoE)架构的 Qwen3-30B-A3B 模型提供预览支持。MoE 架构是一项重要的模型技术进步,它可以智能地将输入路由到针对特定任务的专家子网络,而无需在推理时激活整个模型。这样既能获得接近更大稠密模型的效果,又能保持更快的推理速度和更低的内存占用。
扩展 GenAI 能力以更好支持 Agentic智能体集成
在已有 Agentic AI 支持的基础上,OpenVINO™ Model Server 和 OpenVINO™ GenAI 进一步扩展了 agentic 功能,使多轮对话更加可靠且更易管理。新特性包括:
-
结构化输出解析(Structured Output Parsing)——自动将模型回复整理为如 original_content、reasoning_content 和 tool_calls 等组件,再也不需要手动解析。
-
改进的聊天模板(Improved Chat Templates)——可以将完整聊天历史直接传入 generate 调用,在多轮对话中简化会话管理并更好地保留上下文。
这些特性让你无需额外负担,就能构建会思考、会回答、还能执行动作的智能 Agent。请参见下方代码示例。
pipe = openvino_genai.LLMPipeline(args.model_dir, device)chat_history = [{"role": "system", "content": "..."}, {"role": "user", "content": "..."}]result = pipe.generate(chat_history, parsers=["ToolParser"], tokenizer_encode_kwargs={"tools": tools, "thinking": True})# result.parsed == {"role": "assistant", "tool_calls": [{"name": "...", "arguments": {...}}]}chat_history.append(result.parsed)result = pipe.generate(chat_history, parsers=["ToolParser"], tokenizer_encode_kwargs={"tools": tools, "thinking": False})print(result)
加密Blob格式支持
安全至关重要。在 OpenVINO™ 2025.4 中,开发者可以通过 OpenVINO™ GenAI 新增的加密 Blob 格式(Encrypted Blob Format),安全地部署各类 GenAI 模型。该特性确保模型权重和相关工件在存储与传输过程中都以加密形式存在,从而在部署阶段保护专有的 LLM、VLM 和扩散模型(diffusion models),避免在企业环境、Agentic AI 场景以及多设备部署中发生知识产权被窃取或模型被篡改的风险。加解密过程全部在 OpenVINO™ 内部完成,对 Text2TextPipeline、VLMPipeline 等核心 API 的代码改动极少,对推理性能的影响也可以忽略不计。
对大多数开发者而言,这一特性是“开箱即用、完全透明”的。如果你已经在直接使用 GenAI pipelines,则无需做任何修改。需要注意的是,加密后的 blob 在运行时是只读的——若需要更新模型权重,则必须基于解密后的模型重新导出。通过这一增强功能,GenAI 部署在安全性与合规性方面变得前所未有的简单,同时又不会打乱你现有的开发与部署工作流。
性能提升
本次版本在底层做了多项重要优化,旨在全面加速你的 AI 工作负载:
-
新增 ENABLE_WEIGHTLESS 参数,简化了“无权重(weightless)”模型的管理,并在大模型和多设备部署场景下显著减少内存中权重数据的重复占用。
-
我们精简了 NPU 的模型编译流程,通过消除 NPU 插件与编译器之间的权重序列化环节,降低了内存占用——同一时间内内存中只需保留一份模型权重。
-
GPU 插件方面,引入了更高效的前缀缓存(prefix caching),可在处理重复提示词与长对话历史的聊天应用中减少时延与计算开销;同时增加对 INT8 动态量化(dynamic quantization) 的支持,相比 INT4 能提供更好的大模型精度,同时保持显著的性能优势,在精度与速度之间取得平衡。
-
通过使用优化后的 GPU kernel,多 Token 生成(multi-token generation)得到加速,用于 GenAI 推理时可实现更快的响应;同时结合更智能的 KV-cache 复用机制,显著提升大语言模型在规模扩展(模型更大、并发更多、上下文更长)时的可扩展性。
这些优化带来的直接收益包括:更快的模型加载速度、更低的内存压力以及响应更敏捷的 AI 应用体验。
结语
2025 年对 OpenVINO™ 以及我们的开发者社区来说,是极不平凡的一年。从 GenAI 的突破到 Agentic AI 的演进,每一次版本更新都凝聚着你们的反馈与建议。感谢你一路相伴!你可以随时回看 OpenVINO™ DevCon 2025 的所有会议回放,内容涵盖 AI 助手、Hugging Face、机器人以及 Agentic AI 等丰富主题。代表整个 OpenVINO™ 团队,感谢你们让 2025 年变得如此精彩。让我们共同期待来年更多的创新,也感谢这个让一切成为可能的社区。节日快乐,编码愉快!
参考资料
-
OpenVINO 2025.4 Documentation:https://docs.openvino.ai/2025/index.html
-
OpenVINO Hugging Face collection:https://huggingface.co/collections/OpenVINO/llms-optimized-for-npu-686e7f0bf7bc184bd71f8ba0
-
AI Reference Kits from Intel:https://www.intel.com/content/www/us/en/developer/topic-technology/edge-5g/open-potential.html
-
OpenVINO™ GenAI:https://github.com/openvinotoolkit/openvino.genai
-
OpenVINO™ Model Hub:https://www.intel.com/content/www/us/en/developer/tools/openvino-toolkit/model-hub.html
注意事项及免责声明
*文中提及的其他名称和品牌可能为他人所有。
性能会因使用方式、配置以及其他因素而有所不同。详情请参见 Performance Index(https://edc.intel.com/content/www/us/en/products/performance/benchmarks/overview/) 网站。
性能结果基于配置中所示日期时的测试,可能未能反映所有公开可用的更新。
任何产品或组件都不能做到绝对安全。
您的成本和结果可能有所不同。
英特尔技术可能需要相应的硬件支持、软件支持或服务激活。
© Intel Corporation。Intel、Intel 徽标及其他 Intel 标识是 Intel Corporation 或其子公司的商标。

















 4105
4105

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









