




在上一篇内容中,我们介绍了 PieCloudVector 如何助力构建基于图片数据的商品推荐系统,详细描述从数据集的准备到数据向量化处理,再到向量数据的存储和相似性搜索的完整流程。本文将进一步探讨如何将 PieCloudVector 应用于音频数据,以实现音频内容的识别和分类。
音频数据是一种丰富且动态的非结构化数据形式,PieCloudVector 作为大模型时代的分析型数据库升维,其在音频数据处理上的应用,不仅能够提升音频内容识别的准确性,还能增强音频分类的效率。本文为《PieCloudVector 进阶系列》的第二篇,将以音频数据为例, 详细介绍利用向量数据库助力音频数据的向量化处理、存储以及相似性搜索的过程。 (本文演示数据均来自 Hugging Face)
基于 PieCloudVector 打造音乐推荐系统
音频数据在转化成向量的过程中,其采样率(即每秒采样数量)是控制数据质量和向量大小的关键之一。采样率越大,数据质量越高,但数据大小也随着变大。本文使用的实例数据是来自 Hugging Face 的 MInDS-14 数据集[1],该数据包含了 14 种不同语言的电子银行领域客户音频数据,共 14 个意图种类(intent_class)。
本文将对音频数据向量化,通过音频相似度对比实现音乐推荐系统。下面将从「数据集准备」、「数据降维与存储」、「音频相似性搜索」三个方面进行介绍。完整逻辑如下图所示:
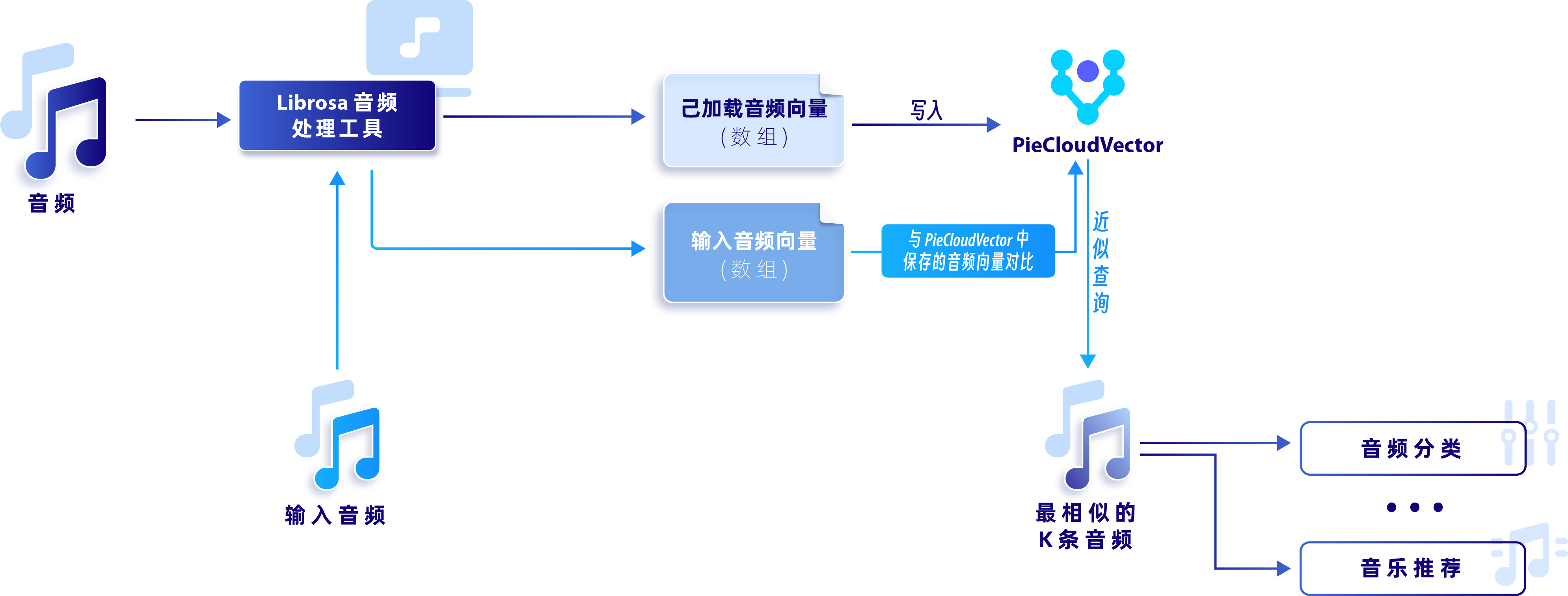
完整逻辑过程
1.数据集准备
首先,我们将对音频数据进行读取和调整,使其转变为向量存入数据库,以便后续的计算。Hugging Face 和后续的步骤需要以下两个 Python 包:
- soundfile
- librosa
从 Hugging Face 下载 MInDS-14 数据。由于该数据集较小,这里我们加载所有共 563 条训练数据。
from datasets import load_dataset
dataset_minds = load_dataset("PolyAI/minds14", "en-US", split="train")
为避免反复下载数据,可将该数据集保存至本地。
dataset_minds.save_to_disk('minds14_dataset')
# 读取本地数据
dataset_minds = load_from_disk('minds14_dataset')
本数据集包括以下特征:路径、音频、转录、英文转录、意图种类和语言,这里我们将重点关注“audio”(音频)、“intent_class”(意图种类)、“lang_id”(语言)这几个特征。
dataset_minds.features
{ 'path': Value(dtype='string', id=None),
'audio': Audio(sampling_rate=8000, mono=True, decode=True, id=None),
'transcription': Value(dtype='string', id=None),
'english_transcription': Value(dtype='string', id=None),
'intent_class': Classlabel(names=['abroad', 'address', 'app_error', 'atm_limit', 'balance', 'business_loan', 'card_issues', 'cash_deposit', 'direct_debit', freeze', 'high_value_payment', 'joint_account', 'latest_transactions', pay_bill'], id=None),
'lang_id': Class 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 349
349

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









