




在人工智能迅猛发展和数据量不断膨胀的当下,传统数据库在面对高维度和大规模的数据处理时早已力不从心。为应对这一挑战,拓数派团队凭借在分布式数据库领域的深厚积累,打造了云原生向量数据库 PieCloudVector。本系列将分为三篇,分别以图片、音频、文本三种典型非结构化数据类型为例,为大家介绍 PieCloudVector 的应用。
拓数派旗下云原生向量数据库 PieCloudVector 采用了将业界成熟开源算法实现与自研的基于 postgres 内核的关系型数据库对接起来的技术路线,能够存储和管理原始数据的向量表示,同时支持精确查询与模糊查询功能,用户可以通过 Postgres 客户端进行高效的相似性搜索。
PieCloudVector 利用其分布式架构显著提升了向量计算的效率,并在此基础上提供了一整套上下游工具。在技术架构上,PieCloudVector 按照向量数据的实际应用流程划分为五个核心层级:原始数据存储、嵌入(Embedding)、索引构建、向量检索以及数据应用。这些层级分别对应于向量数据处理和分析过程中的不同应用场景,构成了一个完整的技术框架,如下图所示:
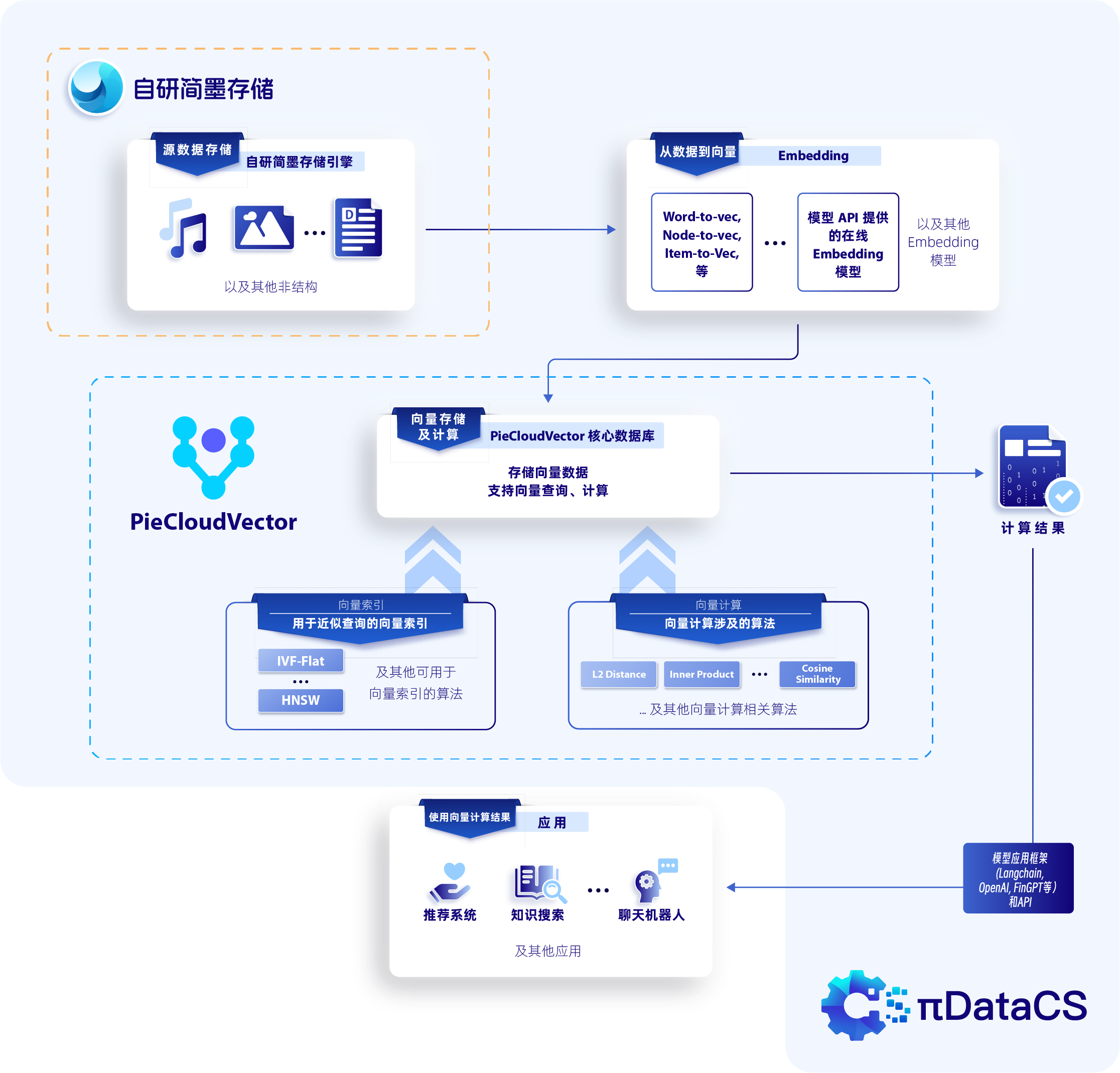
PieCloudVector 整体技术框架
本文为《PieCloudVector 进阶系列》的第一篇,将以图片数据为例,一步步展示如何使用 PieCloudVector 构建商品推荐系统,深入探讨数据向量化的关键步骤,包括 Embedding 计算、将向量写入数据库,以及相似性搜索。 (本文演示数据均来自 Hugging Face)
基于图片数据打造商品推荐系统
向量数据库在执行相似性查询任务中扮演着关键角色,以服装行业的应用场景为例,通过结合商品图片的向量表示与 K-最近邻(KNN)算法,PieCloudVector 能够帮助系统有效地在现有商品库中检索并推荐与目标商品相似的候选商品。整体框架如下图:
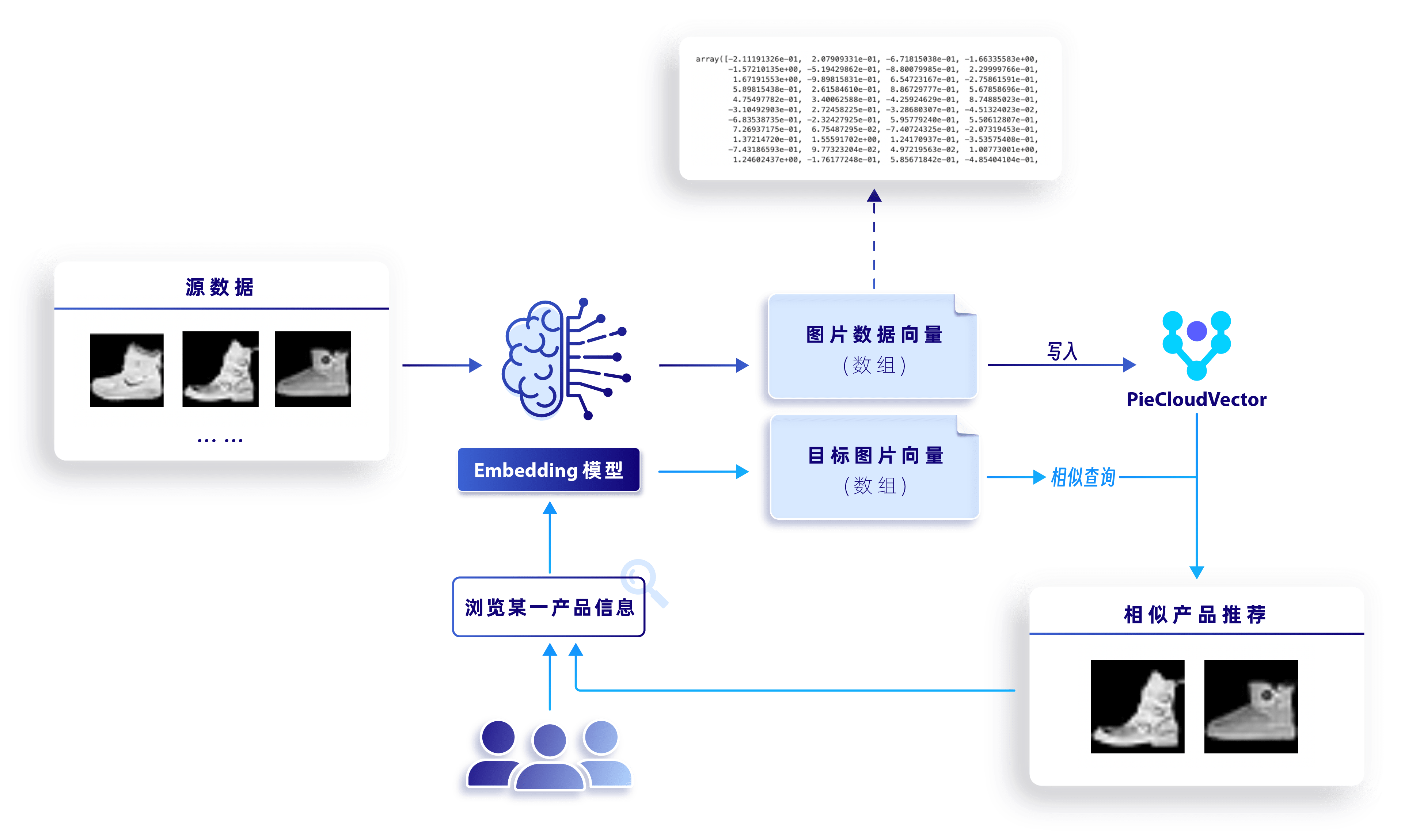
系统整体流程框架
接下来,本文将从「数据集准备」、「数据向量化处理」、「向量数据存储」以及「相似性搜索」四个关键环节,详细阐述利用 PieCloudVector 搭建商品推荐系统的整个流程。
1.数据集准备
首先,从 Hugging face 下载 fashion mnist 数据,该数据集包含了服装图片、类型等数据,详见 fa
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 129
129

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









