




作者:通用视频组
我们提出了一个仅基于状态空间模型(SSM)的高效视频理解架构VideoMamba,并通过大量的实验证明了它具备一系列良好的特性,包括 (1) Visual Domain Scalability; (2) Short-term Action Sensitivity; (3) Long-term Video Superiority; (4) Modality Compatibility。这使得VideoMamba在一系列视频benchmark上取得不俗的结果,尤其是长视频benchmark,为未来更全面的视频理解提供了更高效的方案。
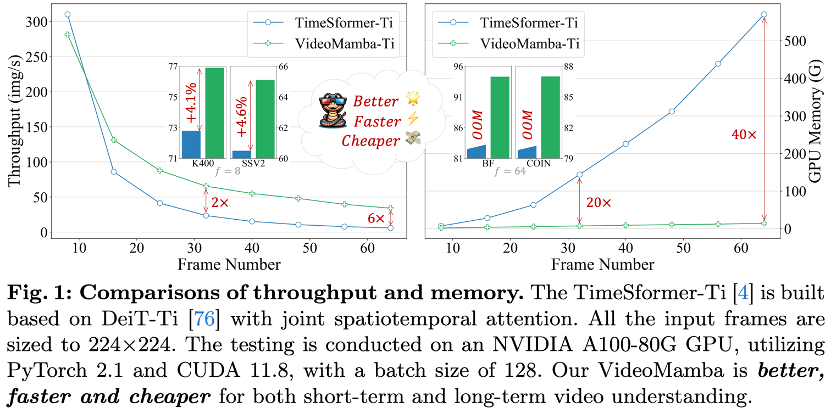

论文题目:
VideoMamba: State Space Model for Efficient Video Understanding
论文链接:
https://arxiv.org/abs/2403.06977
开源代码:
https://github.com/OpenGVLab/VideoMamba
Huggingface:
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









