




InternVid 是一个开源的大规模视频-文本数据集,旨在促进视频理解和生成任务的发展,由上海人工智能实验室与南京大学、中国科学院等单位联合发布,相关的工作已经被ICLR2024接收。它包含超过 700 万个视频,总时长近 76 万小时,并附带详细的文本描述。InternVid 的发布将推动文本-视频的多模态理解和生成的进步,并为相关研究和应用提供新的机遇,包含以下特点:
-
规模庞大:InternVid 是目前公开的最大的视频-文本数据集之一,包含超过 700 万个视频,总时长近 76 万小时。
-
内容丰富: 视频内容涵盖日常生活、体育运动、娱乐、教育等多个领域,能够满足不同研究和应用的需求。
-
高质量: 视频和文本都经过精心挑选和处理,保证了数据集的高质量,提供了丰富的描述,CLIP-SIM,视频美学分数。
InternVid 可用于以下任务:
-
视频理解: 视频分类、视频检索、视频描述生成、视频摘要生成等。
-
视频生成: 视频编辑、视频合成、视频特效等。
-
多模态学习: 视频-文本语义匹配、视频-文本检索、视频-文本生成等。

论文:
https://arxiv.org/abs/2307.06942
开源链接:
https://github.com/OpenGVLab/InternVideo/tree/main/Data/InternVid
HuggingFace:
https://huggingface.co/datasets/OpenGVLab/InternVid

一 InternVid的出发点
学习可迁移的视频-文本表示对于视频理解至关重要,尤其是在自动驾驶、智能监控、人机交互和视觉搜索等实际应用中。近期,OpenAI发布的Sora模型在文生视频领域取得了显著进展。Sora不仅打破了视频连贯性的局限,还在多角度镜头切换中保持一致性,并展示出对现实世界逻辑的深刻理解。这一突破为视频-语言领域的多模态对比学习提供了新的可能性,尽管目前Sora尚未开放给公众使用,2但其在视频生成领域的GPT-3时刻,预示着通用人工智能的实现可能比预期来得更快。
但是限制住目前探索的一个关键原因是缺乏用于大规模预训练的高质量视频-语言数据集。当前的研究依赖于如HowTo100M [1]、HD-VILA [2] 和 YT-Temporal [3, 4] 等数据集,其文本是使用自动语音识别(ASR)生成的。尽管这些数据集规模庞大,但它们在视频和相应文本描述之间的语义相关性通常较低。这类的数据一方面不太符合文生视频等生成任务的需要,另一方面提高这种相关性(例如,通过将视频与描述对齐以改善它们的匹配度)显著有利于下游任务,如视频检索和视频问答。
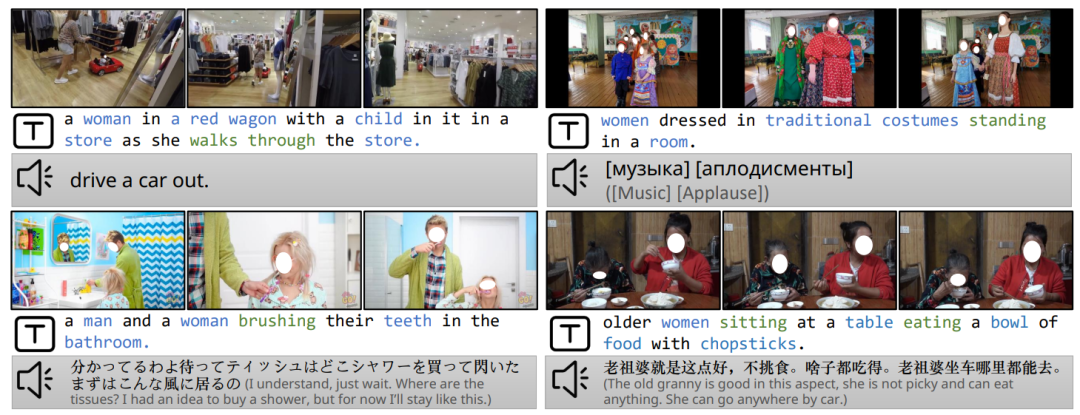
为了解决扩大视频语言建模规模的挑战,同时保持高视频-文本对应性,我们提出了一个大规模的以视频为中心的数据集InternVid,见图1。ASR转录几乎没有描述视频中的视觉元素,而生成的描述则涵盖有更多的视觉内容。该数据集包含高度相关的视频-文本对,包括超过700万视频,总计760,000小时,产生234M个视频片段,涵盖16种场景和约6,000个动作描述。为了提高视频-文本匹配度,我们采用了多尺度方法生成描述。在粗略尺度上,我们对每个视频的中间帧进行描述,并使用描述作为视频描述。在精细尺度上,我们生成逐帧描述,并用语言模型对它们进行总结。
通过InternVid,我们学习了一个视频表示模型ViCLIP,实现了较强的零样本性能。对于文生视频,我们筛选了一个具有美学的子集InternVid-Aes,并涵盖1800万个视频片段。与WebVid-10M[5]一起,InternVid可以显著提高基于diffusion的视频生成模型的生成能力。
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 2991
2991

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









