 DeepSeek-V3.2发布,开源挑战GPT-5
DeepSeek-V3.2发布,开源挑战GPT-5




在ChatGPT发布三周年之际,科技圈又迎来重磅消息!深度求索(DeepSeek)正式发布了其大模型家族的最新成员——DeepSeek-V3.2。这不仅是一次常规升级,更是开源AI领域向闭源巨头发起的一次强有力挑战。官方直接将其性能对标GPT-5,一场AI世界的巅峰对决已然拉开序幕。
在正式发布之前,DeepSeek于两个月前推出了实验性的V3.2-Exp版本,并收到了众多热心用户的反馈与对比测试结果。这次大规模的公测验证了一个关键结论:V3.2-Exp在任何特定场景中都未显著差于V3.1-Terminus,这充分证明了DSA(DeepSeek Sparse Attention)稀疏注意力机制的有效性。
这种"先实验、再正式"的发布策略,不仅展现了DeepSeek对技术的严谨态度,更体现了开源社区的力量——通过真实用户的广泛测试,确保新技术在实际应用中的可靠性。如今,经过两个月的打磨与优化,V3.2正式版终于揭开面纱。

一体两面:认识V3.2的“全能选手”与“推理怪才
本次发布最大的亮点是“一体两面”的策略,同时推出了两个版本,满足不同用户的需求。
DeepSeek-V3.2:全能日用选手
这是一款平衡了推理能力与输出效率的“日用旗舰”。它适用于日常问答、长文本处理和通用智能体(Agent)任务,旨在成为开发者和用户手中最得力的AI助手,性能直逼GPT-5级别,同时拥有更高的性价比。更重要的是,与Kimi-K2-Thinking相比,V3.2的输出长度大幅降低,这意味着更少的计算开销、更短的等待时间,以及更低的使用成本。
DeepSeek-V3.2-Speciale:极限推理怪才
这是一个为极限推理任务而生的“特化版本”。它融合了DeepSeek-Math-V2的强大数学能力,在国际数学、编程等顶级竞赛中展现出金牌水准。不过,由于其推理链长、计算量大,目前主要面向研究领域,对话体验未经优化。
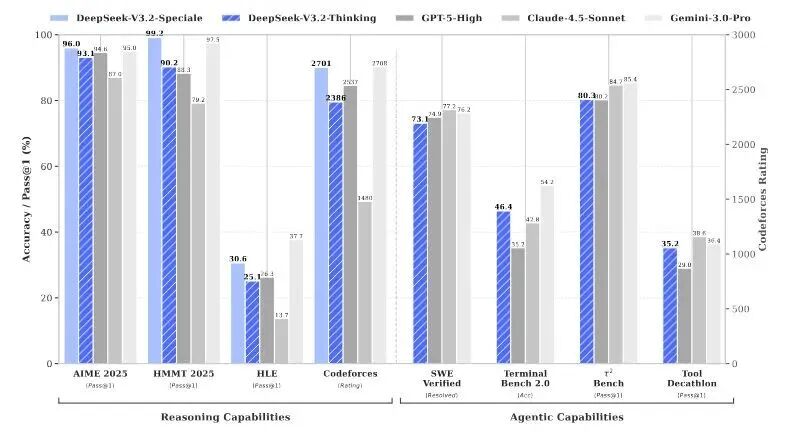
硬核数据:性能究竟有多强?
“口说无凭,数据为证”。在多个国际权威的公开基准测试中,DeepSeek-V3.2的表现令人瞩目。
-
数学能力 (AIME): V3.2得分93.1%,与GPT-5 (High)的94.6%处于同一梯队,展现了顶尖的逻辑推理实力。
-
编程能力 (LiveCodeBench): V3.2达到83.3%,紧随GPT-5的84.5%,代码生成和理解能力一流。
-
软件开发 (SWE Multilingual): 这是高光时刻!V3.2以70.2%的成绩,显著超越了GPT-5的55.3%,证明其在解决真实世界GitHub问题的能力上更胜一筹。
-
输出效率优势: 相比Kimi-K2-Thinking,V3.2在保持相近性能的同时,输出长度显著缩短,这在实际应用中意味着更快的响应速度和更低的Token消耗成本。
而Speciale版本更是将“天才”一词诠释到了极致,在IMO 2025(国际数学奥林匹克)、ICPC World Finals 2025(国际大学生程序设计竞赛世界总决赛)等竞赛模拟中均斩获金牌,部分成绩甚至达到了人类顶尖选手的水平。其中,ICPC成绩相当于人类选手第二名,IOI(国际信息学奥林匹克)达到第十名水平,这在开源模型中可谓史无前例。

技术揭秘:驱动性能飞跃的三大创新
惊艳的性能背后,是DeepSeek在底层技术上的三大核心创新。
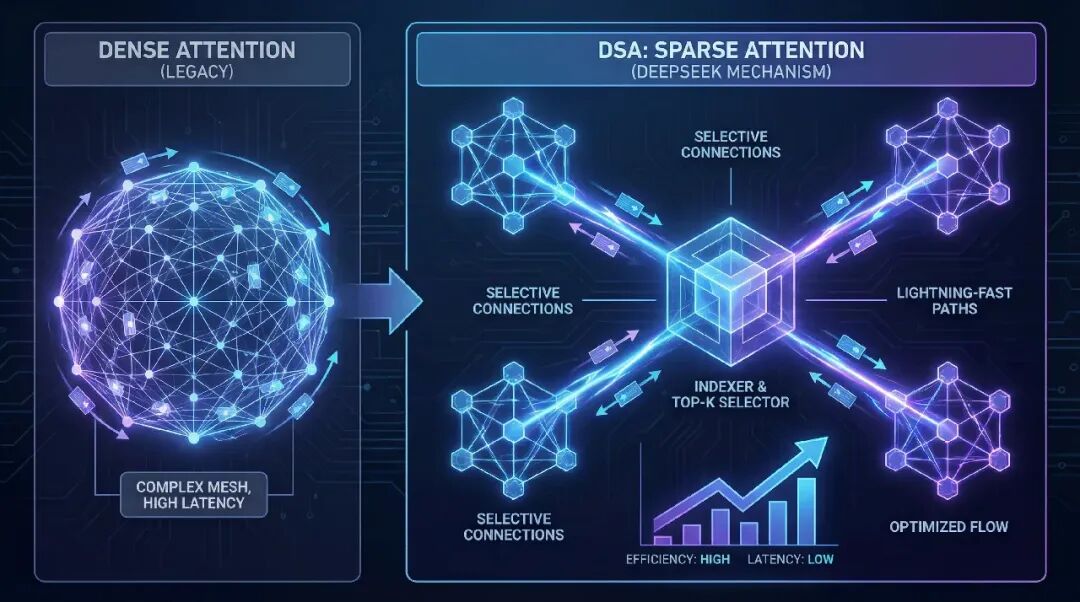
Deepseek Sparse Attention (DSA):AI的“智能索引”
传统模型处理长文本时,计算量会急剧增加。DSA技术就像为模型的记忆建立了一个智能索引,让它在回应时只关注最相关的历史信息,从而在不牺牲质量的前提下,大幅降低长文本处理的计算成本和延迟。
更聪明的Agent大脑:“思考式工具调用”
V3.2是首个将“思考”过程直接融入工具调用的模型。这意味着它不再是简单地执行指令,而是可以在使用外部工具(如代码解释器、搜索引擎)的同时进行结构化推理,从而更准确、更智能地完成复杂的多步骤任务。
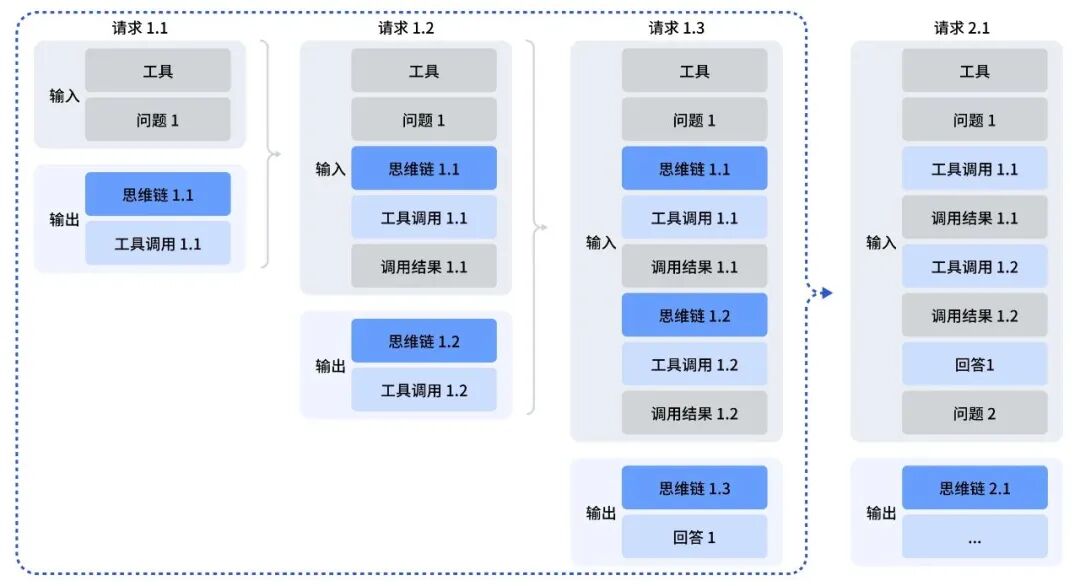
复杂的“思考模式”与多轮推理
模型支持“思考模式”(Thinking Mode),可以处理需要多轮深度推理的复杂问题。通过构建包含超过1800个环境和8.5万条复杂指令的数据集进行训练,V3.2的Agent能力和泛化潜力达到了开源模型的新高度。Agent能力:开源模型的新标杆
V3.2最令人兴奋的突破之一,是其在智能体(Agent)领域达到的新高度。不同于过往版本在思考模式下无法调用工具的局限,V3.2是DeepSeek首个将思考能力融入工具调用的模型,实现了思考与行动的深度融合。
训练数据的规模与质量
为了训练这一能力,团队采用创新的大规模Agent训练数据合成方法,构建了一个前所未有的训练数据集:
1800+真实环境: 涵盖代码执行、数据分析、网络搜索、文件操作等多种实际应用场景
85000+复杂指令: 包含大量"难解答、易验证"的任务,这类任务最能体现模型的推理深度
多轮交互设计: 支持模型在多步骤任务中进行结构化推理和工具调用
评测成绩与泛化能力
在主流Agent工具调用基准测试中,V3.2达到了当前开源模型的最高水平,大幅缩小了开源与闭源模型的差距。更值得一提的是,V3.2并没有针对这些测试集的特定工具进行过拟合训练——这意味着它在真实应用场景中能够展现出强大的泛化能力,面对新工具、新环境时依然能够快速适应。从理论到实践:它能为我们做什么?这些强大的能力不仅仅停留在跑分上,更能落地为实际应用。
DeepSeek-V3.2提供一系列实用工具,覆盖开发、企业运营和科研等多个场景。在软件开发方面,系统能自动审查代码,识别潜在的 bug、安全漏洞和性能问题,并给出具体的修复建议;还能根据需求文档自动生成测试用例,执行测试并输出报告;同时,它会分析整个代码库,自动生成并持续维护技术文档,减轻开发者负担。面向企业用户,工具可深入解析冗长的财务报表,提取关键指标,进行跨公司或跨年度的横向与纵向对比,形成有洞察力的分析报告;智能客服系统则结合企业知识库,有效处理复杂的多轮对话,精准解决客户问题;员工也能通过自然语言提问,快速从海量内部文档中获取所需信息。对于科研人员,系统支持复杂的数学定理推导,辅助完成严谨证明;在算法设计过程中,可验证逻辑正确性并探索优化方向;还能批量处理学术论文,自动提炼研究趋势与核心发现。这些能力已集成到常用开发环境,例如在 Claude Code 中按 Tab 键即可调用名为 deepseek-reasoner 的模型,无需复杂配置,开箱即用,让强大功能真正触手可及。
V3.2的发布,其意义远超一个模型的迭代升级,它代表着AI产业发展的几个重要趋势:
1. 开源与闭源差距大幅缩小
V3.2在多项关键指标上已经达到甚至超越GPT-5和Gemini-3.0-Pro,这打破了"开源模型永远落后闭源巨头"的刻板印象。开源社区正在证明,通过创新的技术路线和高效的训练方法,同样可以达到世界顶尖水平。
2. AI民主化进程加速
当顶级AI能力以开源形式释放,中小企业、独立开发者、科研机构都能平等地获取这些工具,不再被技术壁垒所限。这将催生更多创新应用,加速AI技术在各行各业的落地。
3. 成本优势带来普及可能
V3.2在保持高性能的同时,显著降低了输出长度和计算成本。这意味着更多的场景可以承担得起AI应用的成本,AI将从"奢侈品"变为"日用品"。
4. 推动全球AI产业繁荣
正如券商研究机构所言,全球AI产业已进入共振期,基建扩张与应用落地同步推进。DeepSeek的持续创新,不仅提升了中国AI的国际竞争力,更为全球AI生态注入了新的活力。展望2026年,AI基建与应用仍将是主线,而开源模型将在其中扮演越来越重要的角色。总结:开源AI的新标杆总而言之,DeepSeek V3.2的发布,是开源AI发展史上的一个重要里程碑。它不仅在多项关键指标上追平甚至超越了顶尖的闭源模型,更重要的是,它将这种强大的能力开放给了整个社区,极大地推动了AI技术的民主化。从DSA稀疏注意力机制的验证,到Agent能力的开源最高水平,再到"思考融入工具"的创新突破,V3.2的每一项进展都在书写着开源AI的新篇章。DeepSeek用行动证明,开源模型同样有能力攀登AI技术的顶峰,甚至在某些领域走得更远。现在,V3.2模型已在Hugging Face和OpenCSG社区开源,API也已全面上线。无论你是开发者、企业决策者还是AI爱好者,都可以立即体验这一突破性的技术成果。
社区地址
OpenCSG社区:https://opencsg.com/models/deepseek-ai/DeepSeek-V3.2
hf社区:https://huggingface.co/deepseek-ai/DeepSeek-V3.2
OpenCSG 是全球领先的开源大模型社区平台,致力于打造开放、协同、可持续生态,AgenticOps是人工智能领域的一种AI原生方法论,由OpenCSG(开放传神)提出。AgenticOps是Agentic AI的最佳落地实践也是方法论。核心产品 CSGHub 提供模型、数据集、代码与 AI 应用的 一站式托管、协作与共享服务,具备业界领先的模型资产管理能力,支持多角色协同和高效复用。


















 4550
4550

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









