




 本文总结了《python3网络爬虫实战分析》第三章的重难点,包括处理print()的seq参数错误、cookies.txt的使用、headers的设置要求以及在爬取过程中遇到的登录状态维持问题。尽管在爬取过程中遇到了验证码验证,但通过替换URL为其他网站(如'http://localhost:5000'->'http://sso.toutiao.com/',使用手机号和验证码)可以获取200响应。文中还提供了猫眼电影排行的爬虫代码实例。
本文总结了《python3网络爬虫实战分析》第三章的重难点,包括处理print()的seq参数错误、cookies.txt的使用、headers的设置要求以及在爬取过程中遇到的登录状态维持问题。尽管在爬取过程中遇到了验证码验证,但通过替换URL为其他网站(如'http://localhost:5000'->'http://sso.toutiao.com/',使用手机号和验证码)可以获取200响应。文中还提供了猫眼电影排行的爬虫代码实例。
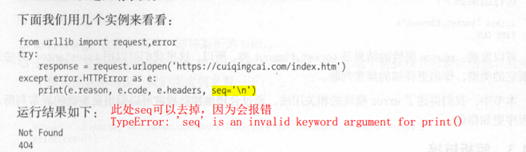
此处seq可以省略不用,因为会报错:
TypeError: ‘seq’ is an invalid keyword argument for print()

cookies.txt文件保存在你正在编程python文件运行的文件夹中
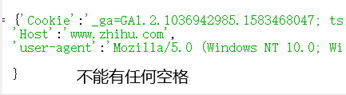

在维持知乎登陆方法介绍中,从网页中复制的headers内容,其中Cookie、Host和user-agent 后不能出现空格,不然报错。
但是爬取的页面,却无法维持登陆知乎状态,会出现验证问题。(待解决)

有时候点开爬取内容会加载很慢,导致软件卡顿。可以右键复制,然后新建文本,进行保存观察。
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









