




 研究发现,传统的Seq2Seq模型在对话生成中倾向于生成安全、平淡的回复。为解决此问题,论文提出使用最大相互信息(MMI)作为优化目标,以增强回复的多样性和相关性。实验表明,MMI模型在两个对话数据集和人工评估中提高了回复的质量和多样性。在训练中采用了四层LSTM结构,并在解码过程中应用MMI-antiLM和MMI-bidi策略,以平衡输入输出的依赖。通过调整参数,避免了无语法结构的回复和局部最优解,显著提升了对话的有趣性和多样性。
研究发现,传统的Seq2Seq模型在对话生成中倾向于生成安全、平淡的回复。为解决此问题,论文提出使用最大相互信息(MMI)作为优化目标,以增强回复的多样性和相关性。实验表明,MMI模型在两个对话数据集和人工评估中提高了回复的质量和多样性。在训练中采用了四层LSTM结构,并在解码过程中应用MMI-antiLM和MMI-bidi策略,以平衡输入输出的依赖。通过调整参数,避免了无语法结构的回复和局部最优解,显著提升了对话的有趣性和多样性。
Paper 链接
0. Abstract部分
0.1 用于生成对话的Seq2Seq NN(序列到序列神经网络模型)
倾向于产生安全,平常的反应(例如,我不知道,任何问题都能这么回答)而不考虑输入如何。
我们发现使用传统的目标函数,即输出的可能性(响应)
给定的输入(消息)不适合回复生成任务(Response generation task)。 因此,我们建议使用最大相互信息(MMI)作为神经模型中的目标函数。 实验结果表明,提出的MMI模型可产生更加多样化,有趣且适当的回复,从而在两个会话数据集和人工评估中的BLEU得分中获得实质性收益。
1. Introduction部分
1.1 对话代理(Conversational agent)越来越重要于促进人与人之间(及其电子设备)的顺畅互动,然而传统的对话系统仍在继续面临重大挑战。健壮性,可伸缩性和领域适应性的形式。 因此,注意力转向了从数据中学习会话模式:研究人员已经开始在统计机器的框架内探索数据驱动的会话响应的生成翻译, 要么基于句子(phrase-based), 要么通过神经网络,要么直接就通过sequence2sequence的模型。SEQ2SEQ模型提供了可扩展性和语言独立性的承诺,以及隐式学习线对之间的语义和句法关系以及以传统SMT方法无法实现的方式捕获上下文相关性的能力。
1.2 一个好的的回复生成系统应该能够输出多种多样且有趣的语法,连贯的句子回复。 但是在实践中,神经对话模型往往会产生琐碎的
或不置可否的回应,通常涉及一些高频短语比如I don‘t know, I’m OK(万能回答). 如table1(下方)所示,一个四层seq2seq模型,在2千万对话配对中学习

这种现象的部分原因可以归因于I don‘t know这种句子的高频率出现,相反,更具有意义的回复一般在数据集中比较稀疏(sparsity)。 因为神经网络在训练中会给这些安全的(万能的)回复分配更高的概率。这种模型中的目标函数,通常在类似于机器翻译等任务中非常常见,但可能不适合涉及输出本质上不同的任务。(就是说生成不了过于有意义,及新意的回复。)所以,直观上,似乎不仅要考虑响应对消息的依赖性,而且还要考虑将消息提供给给定响应的可能性的倒数。(出现频率小的回答,倒数更大,这里有点像Tfidf, 就是要考虑倒数,从而更加注意一些低频词,因为高频词通常都是the,a,that等一些没有实际意义的词)。
1.3 于是该文章提议用MMI,一个在对话识别(Speech recognition)中第一次被提到的东西,MMI可以作为一种优化目标函数,用来衡量输入和输出之间的相互依赖度(mutual dependence)。然后文章发现使用MMI可以有效减少万能回复所占的比例,以及生成一些显而易见的更有辨识度,更多样性,更有趣的回答。
2. Related works
2.1 反正说自己的模型好,以前的模型都是template模版化的,即时考虑了概率模型,也不够好。而他们的新模型,受启发于SMT(statistical machine translation 统计机器翻译)。然后提到有些用了LSTM的seq2seq模型可以捕捉隐式组成性和大跨度的依赖。但是,我们的目标是产生单个非平凡的输出,并且我们的方法不需要识别词汇重叠即可促进多样性
3. Sequence-to-Sequence Model
3.1
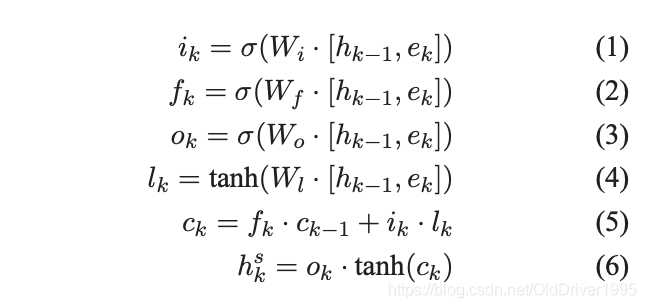
其中 e k e_k ek 是一个在时刻k关于词或者句子的向量, h k − 1 h_{k-1} hk−1就是上一个时刻的输入,把上一个时刻的输入和 e k e_k ek放到LSTM中从而生成新的 h k h_k hk。
3.2 会用到softmax
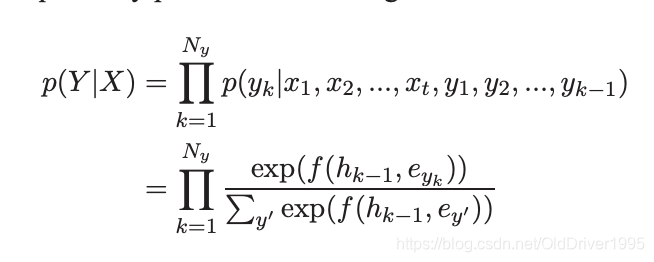
并且,输入和输出会用到不同的LSTM参数,从而捕捉不同的patterns。
3.3 解码过程中(把生成的向量转回人类可读的句子),一旦EOS token被识别就停止解码,解码可以用到贪心的算法(选择候选词表中概率最大的那个词作为当前位置的词),或者beam search
4. MMI models
4.1 Notation
S作为一个输入序列, S = { s 1 , s 2 , s 3 , s 4 . . . s N s } S=\{s_1, s_2, s_3, s_4...s_{Ns}\} S={ s1,s2,s3,s4...sNs} ,其中 N s N_s Ns是S中词表的长度。 T是一个回复序列 T = { t 1 , t 2 , t 3 . . . t N t , E O S } T = \{t_1, t_2, t_3... t_{Nt}, EOS\} T={ t1,t2
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









