




 本文详细介绍了Scrapy框架,包括概念、作用、工作流程及核心组件,教你如何快速创建爬虫并深入理解response对象的属性。掌握Scrapy,提升网络数据抓取能力。
本文详细介绍了Scrapy框架,包括概念、作用、工作流程及核心组件,教你如何快速创建爬虫并深入理解response对象的属性。掌握Scrapy,提升网络数据抓取能力。
文章目录
Scrapy框架的基本介绍
Scrapy的概念
Scrapy是一个Python编写的开源网络爬虫框架。它是一个被设计用于爬取网络数据、提取结构性数据的框架。
Scrapy 使用了Twisted['twɪstɪd]异步网络框架,可以加快我们的下载速度。
Scrapy框架的作用
少量的代码,就能够快速的抓取
Scrapy的流程
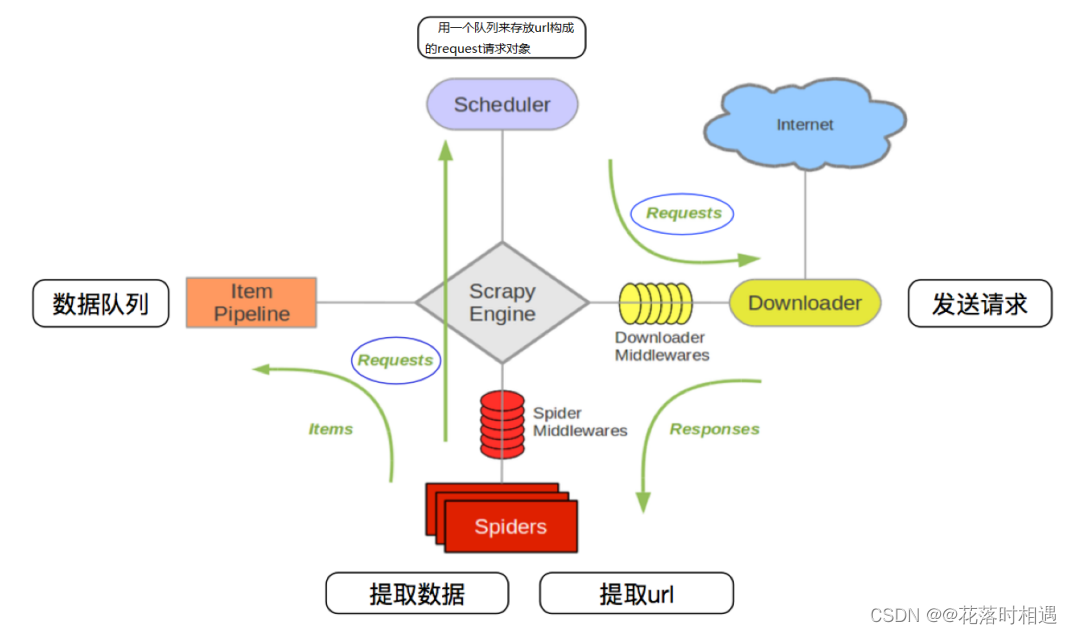
其流程可以描述如下:
- 爬虫中起始的url构造成request对象–>爬虫中间件–>引擎–>调度器
- 调度器把request–>引擎–>下载中间件—>下载器
- 下载器发送请求,获取response响应---->下载中间件---->引擎—>爬虫中间件—>爬虫
- 爬虫提取url地址,组装成request对象---->爬虫中间件—>引擎—>调度器,重复步骤2 5. 爬虫提取数据—>引擎—>管道处理和保存数据
注意:
- 图中中文是为了方便理解后加上去的
- 图中绿色线条的表示数据的传递
- 注意图中中间件的位置,决定了其作用
- 注意其中引擎的位置,所有的模块之前相互独立,只和引擎进行交互
组成部分介绍:
- 引擎器:负责总体调度
- 调度器(scheduler):接收引擎发送过来的request对象。
- 下载器(downloader):接受引擎发过来的request对象,发送请求,获取响应,把相应交给引擎
- 爬虫组件(spider):接收引擎传递过来的request,解析response,把提取的数据交给引擎,提取url,构造Requests请求,交给引擎
- 管道(pipeline):保存数据
Scrapy的三个内置对象
- request请求对象:由url method post_data headers等构成
- response响应对象:由url body status headers等构成
- item数据对象:本质是个字典
scrapy中每个模块的具体作用

Scrapy的基本使用
安装:
- pip install scrapy
创建项目
scrapy startproject 项目名字
创建爬虫
scrapy genspider 爬虫的名字 允许爬取的域名
- 爬虫的名字:作为爬虫运行时的参数
- 允许爬取的域名:设置爬取的范围
- 例:scrapy genspider job xx.com
启动scrapy
要保证在根目录下启动
- 启动方式1:scrapy crawl 爬虫的名字
- 启动方式2:scrapy crawl 爬虫的名字 --nolog
- (nolog可以不显示调度信息)
response响应对象的常用属性
- response.url:当前响应的url地址
- response.request.url:当前响应对应的请求的url地址
- response.headers:响应头
- response.requests.headers:当前响应的请求头
- response.body:响应体,也就是html代码,byte类型
- response.status:响应状态码


















 3万+
3万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











