




 本文概述了爬虫的基本概念,包括其作用、分类、流程,重点讲解了请求头、响应状态码、反爬策略,以及http和https的区别。详细介绍了网络通信过程,并列举了关键技术和术语,如数据采集、cookies、状态码200与404等。
本文概述了爬虫的基本概念,包括其作用、分类、流程,重点讲解了请求头、响应状态码、反爬策略,以及http和https的区别。详细介绍了网络通信过程,并列举了关键技术和术语,如数据采集、cookies、状态码200与404等。
目录
一、爬虫的基本概念
1、爬虫的概念
模拟浏览器、发送请求,获取响应
2、爬虫的作用
- 数据采集
- 软件测试
- 抢票
- 网络安全
- web漏洞扫描
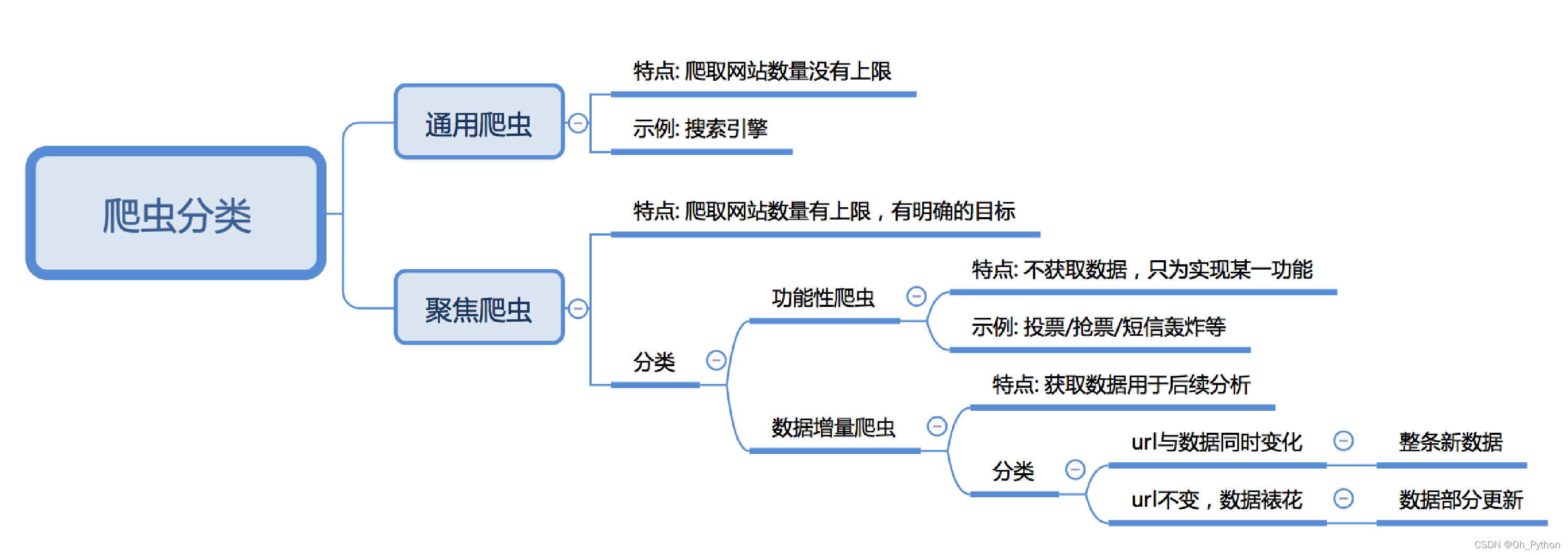
二、爬虫的分类
根据爬取网站的数量,可以分为:通用爬虫、聚焦爬虫
三、爬虫的基本流程
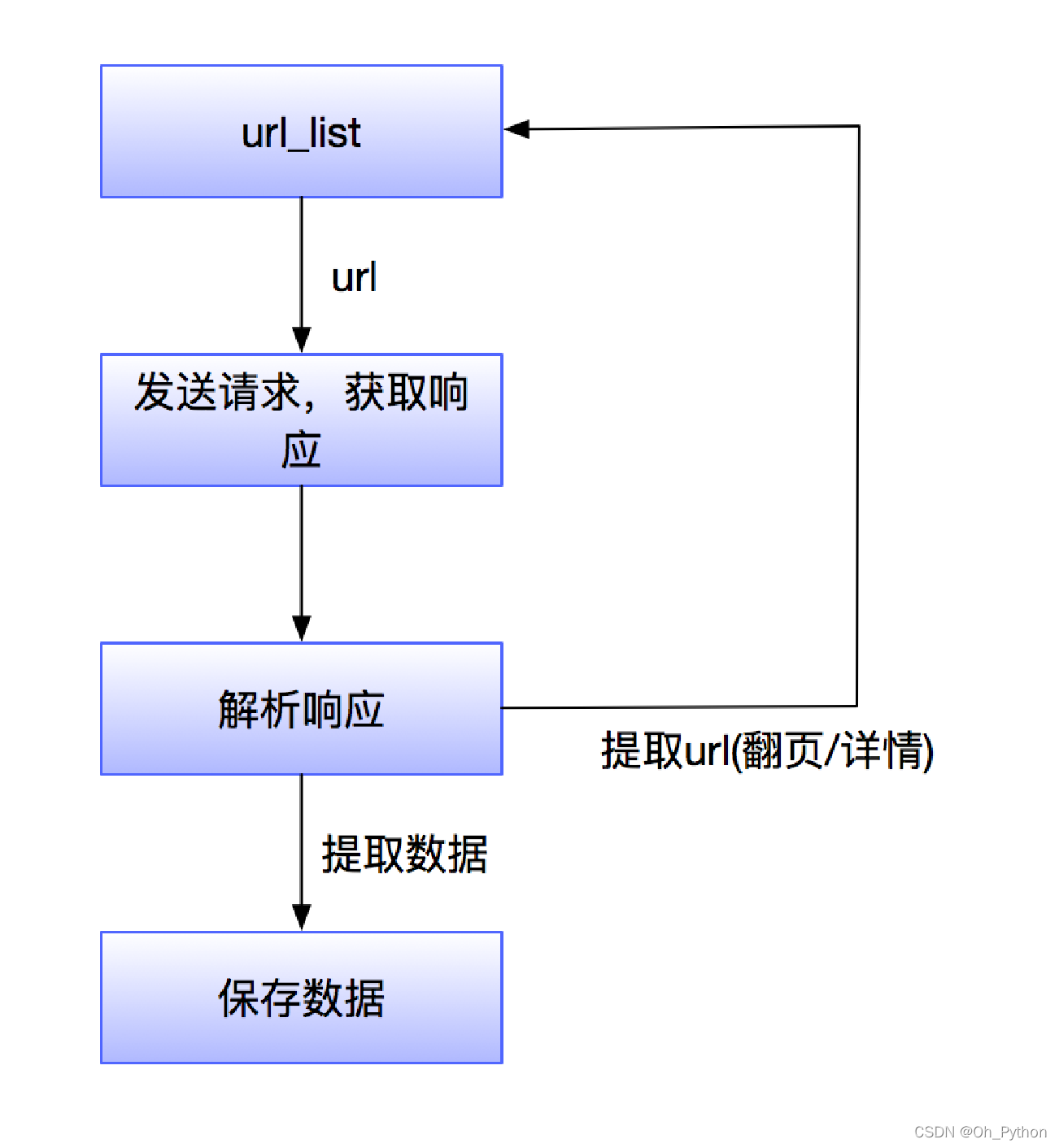
流程: url(网址资源定位符) ---> 对url发送网络请求,获取网络请求的响应 --> 解析响应,提取数据 --->保存数据
- 确认目标url:例 www.xxxx.com
- 发送请求:发送网络请求,获取到特定的服务器给我们的响应
- 提取数据:从响应中提取到特定的数据,如提取的方法:jsonpath、xpath、re
- 保存数据:文件操作、数据库
四、请求头
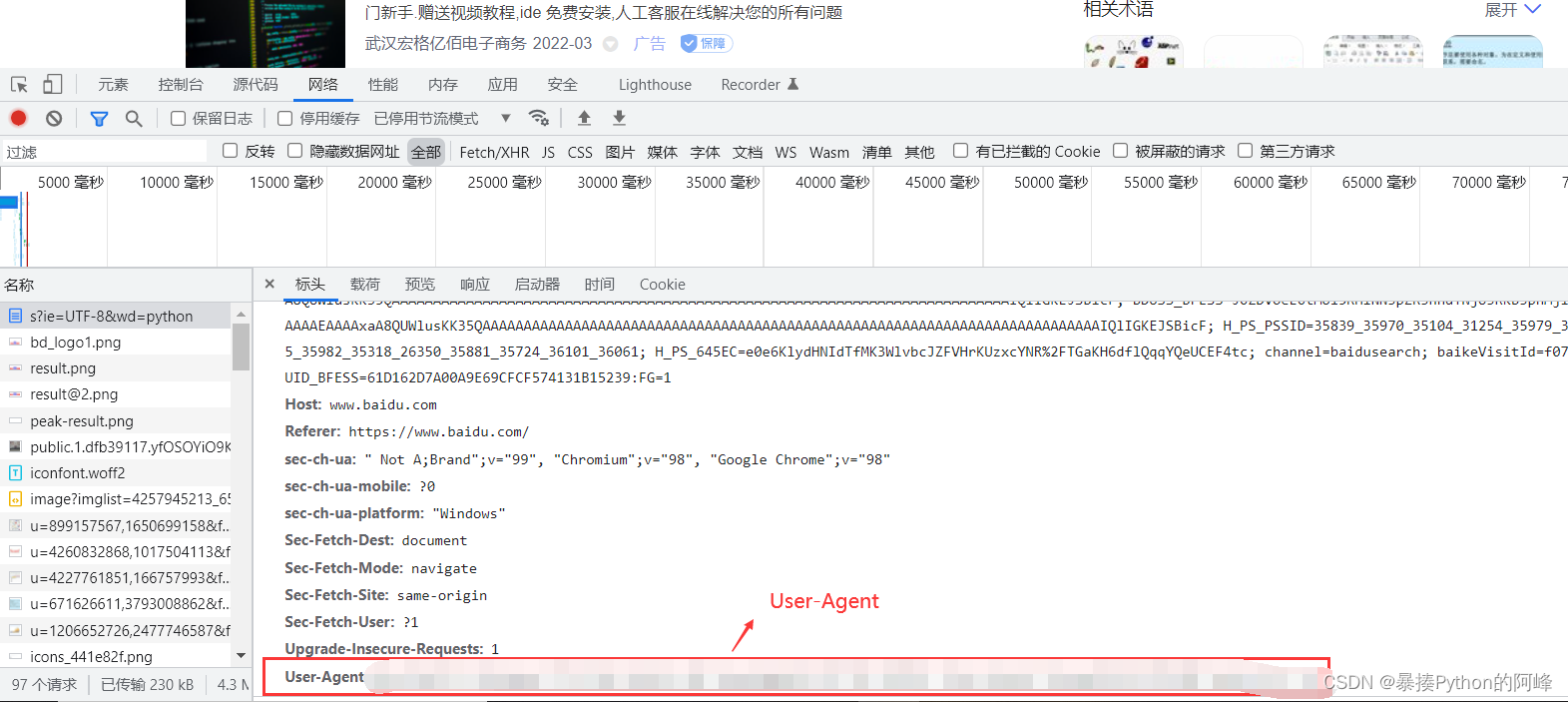
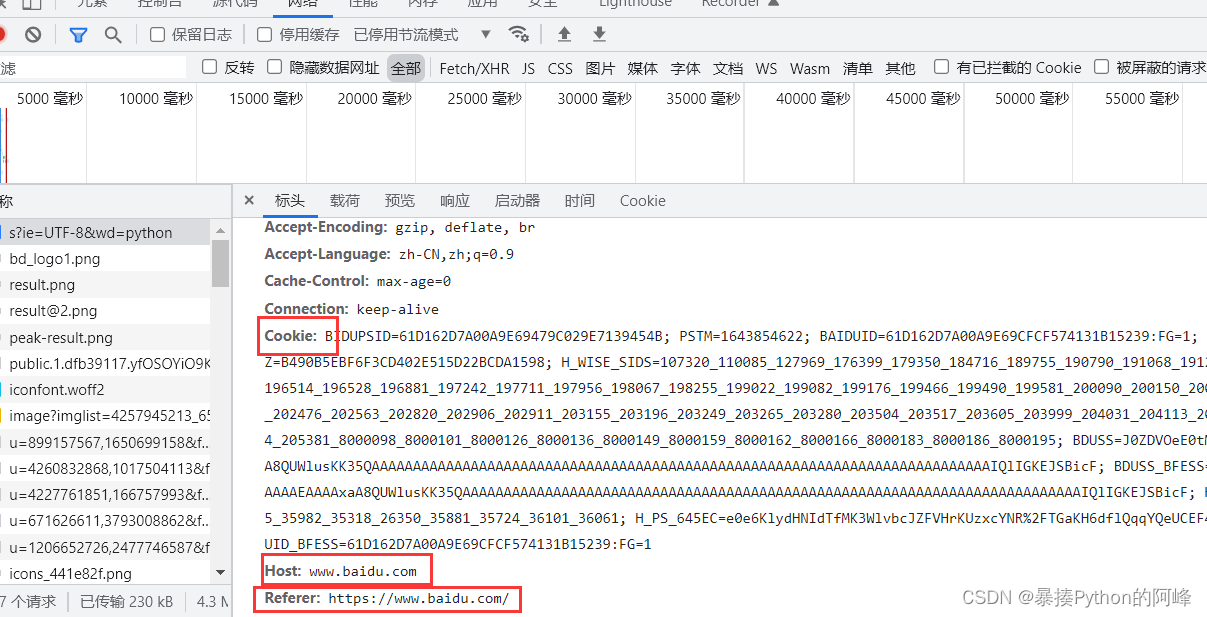
请求头:network
请求方式:
- get:向服务器要资源
- post:向服务器提交资源
- user-agent:标识用户是以什么身份访问的服务器
- cookie:登录状态保持
- referer:当前这一次请求是由那个请求过来的
例:在网页检查中的Network下的文件包中,可以查看 user-agent、cookie、referer
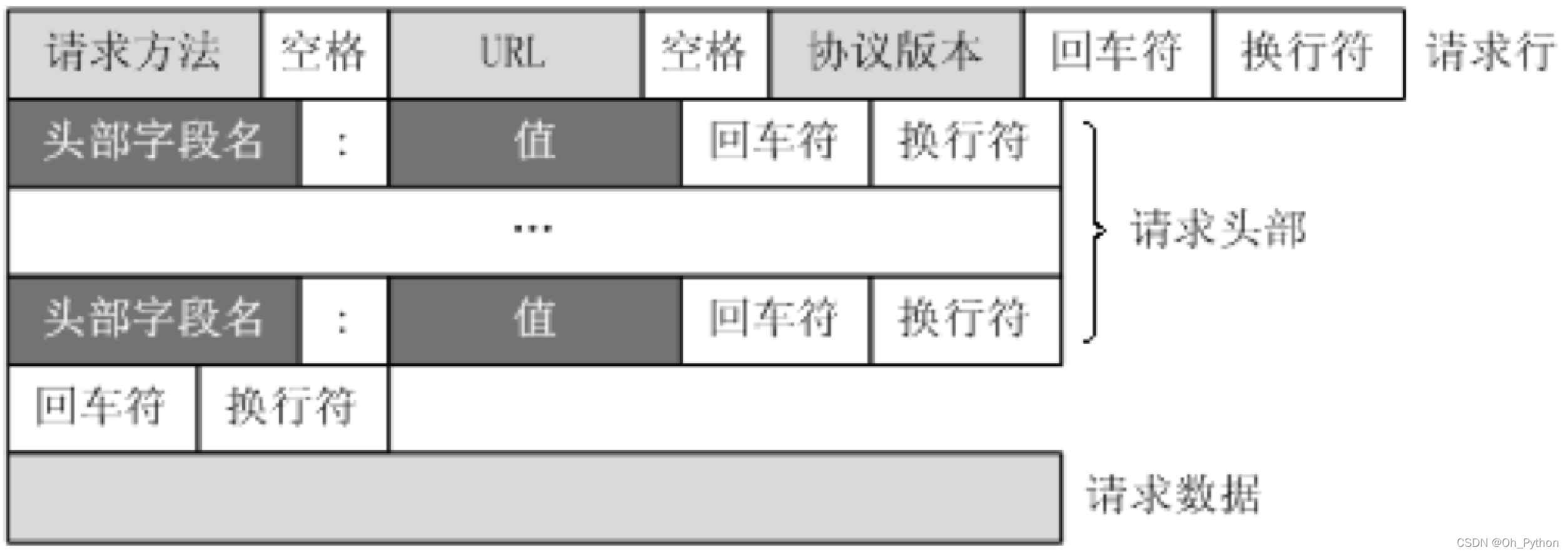
五、常见的响应状态码
- 200:成功
- 302:跳转,新的url在响应的Location头中给出
- 303:浏览器对于POST的响应进行重定向至新的url
- 307:浏览器对于GET的响应进行重定向至新的url
- 403:资源不可用;服务器理解客户的请求,但拒绝处理它(没有权限)
- 404:找不到该页面
- 500:服务器内部错误
- 503:服务器由于维护或者负载过重未能答应,在响应中可能会携带Retry-After响应头;有可能时因为爬虫频繁访问url,使服务器忽视爬虫的请求,最终返回503响应状态码
六、爬虫与反爬
爬虫:模拟客户端访问,爬取数据。——要做的事情
反爬:保护重要数据,阻止恶意网络攻击。——后端服务器要做的事情
七、http和https的概念
http:超文本传输协议,默认端口:80,规定了服务器和客户端互相通信的规则。
https:https = http + ssl(安全套接字层),默认端口:443,https比http更安全,但是性能更低。
八、网络通信
网络通信流程:
- 电脑(浏览器)url —— 例:www.xxxx.com
- DNS服务器:IP地址标注服务器。——IP地址
- DNS服务器返回IP地址给浏览器
- 浏览器拿到IP地址去访问服务器,返回响应
- 服务器返回的响应:html(文本信息)、css(css样式)、js



















 813
813

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











