




 极大似然估计是一种常用的参数估计方法,基于样本数据找出使样本出现概率最大的参数。本文介绍了极大似然估计的直观想法、定义、离散型与连续型的概率分布,以及求解步骤,并通过正态分布的例子进行深入解释。在机器学习中,极大似然估计在模型训练中发挥关键作用。
极大似然估计是一种常用的参数估计方法,基于样本数据找出使样本出现概率最大的参数。本文介绍了极大似然估计的直观想法、定义、离散型与连续型的概率分布,以及求解步骤,并通过正态分布的例子进行深入解释。在机器学习中,极大似然估计在模型训练中发挥关键作用。
极大似然估计
直观想法(举个例子)
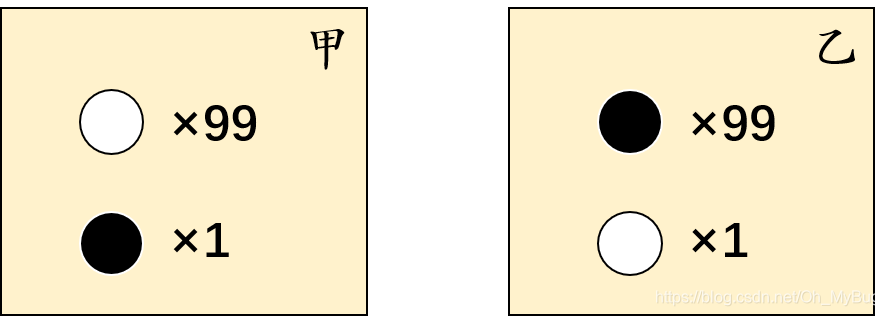
经典例题:有两个外形完全相同地箱子,甲箱中有99只白球,1只黑球;乙箱中有99只黑球,1只白球。一次试验取出一球,结果取出的是黑球。
问:黑球从哪个箱子中取出?
人们的第一印象就是:“此黑球最像是从乙箱中取出”,这个推断符合人们的经验事实。“最像”就是“最大似然”之意,这种想法常称为“最大似然原理”(maximum-likelihood)。
定义
极大似然估计说的是已知某个随机样本满足某种概率分布,但是其中具体的参数不清楚,参数估计就是通过若干次实验,观察其结果,利用结果推出参数地大概值。
极大似然估计是建立在这样的思想上:
已知某个参数能使这个样本出现的概率最大,我们当然不会再去选择其他小概率的样本,所以干脆就把这个参数作为估计的真实值。
离散型
若总体 X X X为离散型,其概率分布列为
P { X = x } = p ( x ; θ ) P\{X=x\}=p(x;\theta) P{ X=x}=p(x;θ)
其中 θ \theta θ为未知参数。设 ( X 1 , X 2 , . . . , X n ) (X_1,X_2,...,X_n) (X1,X2,...,Xn)是取自总体的样本容量为 n n n的样本,则 ( X 1 , X 2 , . . . , X n ) (X_1,X_2,...,X_n) (X1,X2,...,Xn)的联合分布律为 Π i = 1 n p ( x i ; θ ) \Pi_{i=1}^np(x_i;\theta) Πi=1np(xi;θ)。
又设 ( X 1 , X 2 , . . . , X n ) (X_1,X_2,...,X_n) (X1,X2,...,Xn)有一组观测值为 ( x 1 , x 2 , . . . , x n ) (x_1,x_2,...,x_n) (x1,x2,...,xn),易知样本 ( X 1 , X 2 , . . . , X n ) (X_1,X_2,...,X_n) (X1,X2,...,Xn)取到观测值 ( x 1 , x 2 , . . . , x n ) (x_1,x_2,...,x_n) (x1,x2,...,xn)的概率为
L ( θ ) = L ( x 1 , x 2 , . . . , x n ; θ ) = Π i = 1 n p ( x i ; θ ) L(\theta) = L(x_1,x_2,...,x_n;\theta) = \Pi_{i=1}^np(x_i;\theta) L(θ)=L(x1,x2,...,xn;θ)=Πi=1np(xi;θ)
这一概率随 θ \theta θ的取值而变化,它是 θ \theta θ的函数,称 L ( θ ) L(\theta) L(θ)为样本的似然函数。
连续型
若总体 X X X为连续型,其概率密度函数为
f ( x ; θ ) f(x;\theta) f(x;θ)
其中 θ \theta θ为未知参数。设 ( X 1 , X 2 , . . . , X n ) (X_1,X_2,...,X_n) (X1,X2,...,Xn)是取自总体的样本容量为 n n n的样本,则 ( X 1 , X 2 , . . . , X n ) (X_1,X_2,...,X_n)
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









