




 本文详细介绍了Decoder模型的构建过程,包括target数据处理、Decoder的构造,涉及Embedding、RNN单元、输出层的构建以及训练与预测Decoder的区别。通过对Decoder的深入理解,为后续的模型分析打下基础。
本文详细介绍了Decoder模型的构建过程,包括target数据处理、Decoder的构造,涉及Embedding、RNN单元、输出层的构建以及训练与预测Decoder的区别。通过对Decoder的深入理解,为后续的模型分析打下基础。
2021SC@SDUSC
文章目录
本周在上一周对Encoder-Decoder模型的数据集和Encoder的构建部分学习的基础上进一步对 Decoder的构建部分展开了学习,整理笔记和代码实操记录如下。
一、Decoder模型构建
在Decoder端,主要完成:
- 对target数据进行处理
- 构造Decoder
1.target数据处理
target数据有两个作用:
- 在训练过程中,需要将target序列作为输入传给Decoder端RNN的每个阶段,而不是使用前一阶段预测输出,以此来提升模型的准确性。
- 需要用target数据来计算模型的loss。
首先需要对target端的数据进行预处理。将target中的序列作为输入给Decoder端的RNN时,序列中的最后一个字母(或单词)实际上是无用的。

如图,右边的Decoder端,可以看到target序列是[< go >, W, X, Y, Z, < eos >],其中< go >,W,X,Y,Z是每个时间序列上输入给RNN的内容。在此处,< eos >并没有作为输入传递给RNN,因此需要将target中的最后一个字符去掉,同时还需要在前面添加< go >标识,告诉模型这代表一个句子的开始。
使用**tf.strided_slice()**来进行这一步处理。
def process_decoder_input(data, vocab_to_int, batch_size):
'''
补充<GO>并移除最后一个字符
'''
ending = tf.strided_slice(data,[0, 0],[batch_size, -1], [1, 1])
decoder_input = tf.concat([tf.fill([batch_size, 1], vocab_to_int['<GO>']), ending], 1)
return decoder_input
其中tf.fill(dims, value)参数会生成一个dims形状并用value填充的tensor。
例如,tf.fill([2,2], 7) => [[7,7], [7,7]]。
tf.concat()按照某个维度将两个tensor拼接起来。
2.构造Decoder
定义decoding_layer函数构造Decoder层。
def decoding_layer(target_letter_to_int, decoding_embedding_size, num_layers,
rnn_size, target_sequence_length, max_target_sequence_length,
encoder_state, decoder_input)
参数说明:
-target_letter_to_int: target数据的映射表
-decoding_embedding_size:embed向量大小
-num_layers:堆叠的RNN单元数量
-rnn_size:RNN单元的隐层结点数量
-target_sequence_length:target数据序列长度
-max_target_sequence_length:target数据序列最大长度
-encoder_state:encoder端编码的状态向量
-decoder_input:decoder端输入
(1)Embedding
在decoding_layer中首先对target数据进行embedding。
# 1.Embedding
target_vocab_size = len(target_letter_to_int)
decoder_embeddings = tf.Variable(tf.random_uniform([target_vocab_size, decoding_embedding_size]))
decoder_embed_input = tf.nn.embedding_lookup(decoder_embeddings,decoder_input)
(2)构造Decoder中的RNN单元
其次,构造Decoder中的RNN单元。
#2.构造Decoder中的RNN单元
def get_decoder_cell(rnn_size):
decoder_cell = tf.contrib.rnn.LSTMCell(rnn_size,initializer=tf.random_uniform_initializer(-0.1, 0.1, seed=2))
return decoder_cell
cell=tf.contrib.rnn.MultiRNNCell([get_decoder_cell(rnn_size) for _ in range(num_layers)])
(3)构造输出层
接着构造输出层,从而得到每个时间序列上的预测结果。
#3.Output全连接层
output_layer = Dense(target_vocab_size,kernel_initializer = tf.truncated_normal_initializer(mean = 0.0, stddev=0.1))
(4)构造training decoder
出于对模型robust稳健性的考虑,将decoder分为training和predicting。使这两个decoder共享参数,即,通过training decoder学得的参数,给predicting用来预测。
在training阶段,为了能够让模型更加准确,不把t-1的预测输出作为t阶段的输入,而是直接使用target data中序列的元素输入到Encoder中,从而保证模型的准确性。如图。
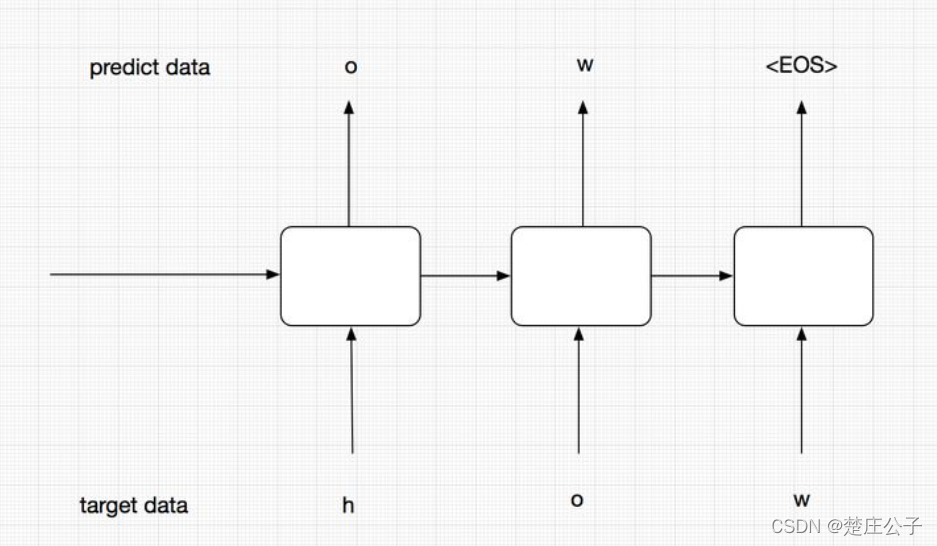
training decoder构造实现:
#4.Training decoder
with tf.variable_scope("decoder"):
#得到help对象
training_helper = tf.contrib.seq2seq.TrainingHelper(inputs=decoder_embed_input,
sequence_length=target_sequence_length,
time_major=False)
#构造decoder
training_decoder = tf.contrib.seq2seq.BasicDecoder(cell,
training_helper,
encoder_state,
output_layer)
training_decoder_output, _ = tf.contrib.seq2seq.dynamic_decode(training_decoder,
impute_finished=True,
maximum_iterations=max_target_sequence_length)
(5)构造predicting decoder
在predicting阶段,没有target data,有的只是t-1阶段的输出和隐层状态,在此把前一阶段的预测结果作为下一阶段的输入。training训练好的参数供predicting使用。
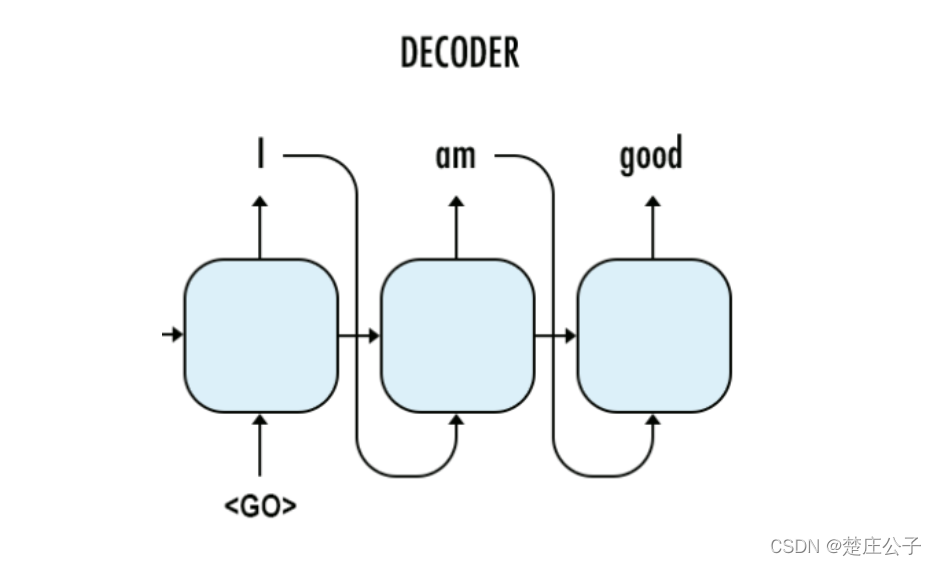
predicting decoder构造实现:
#5. Predicting decoder
# 与training共享参数
with tf.variable_scope("decoder",reuse=True):
#创建一个常量tensor并复制为batch_size的大小
start_tokens = tf.tile(tf.constant([target_letter_to_int['<GO>']], dtype=tf.int32), [batch_size],name='start_tokens')
predicting_helper = tf.contrib.seq2seq.GreedyEmbeddingHelper(decoder_embeddings,
start_tokens,
target_letter_to_int['<EOS>'])
predicting_decoder = tf.contrib.seq2seq.BasicDecoder(cell,
predicting_helper,
encoder_state,
output_layer)
predicting_decoder_output, _ = tf.contrib.seq2seq.dynamic_decode(predicting_decoder,
impute_finished=True,
maximum_iterations=max_target_sequence_length)
return training_decoder_output,predicting_decoder_output
二、总结
本周接上周的学习,对Encoder-Decoder剩余部分Decoder模型的构建进行了学习,通过代码实操对模型构建有了基本的了解与熟悉。下周将开展对Model.py中的模型分析。

















 3979
3979

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









