







文章声明
本文章中所有内容仅供学习交流,严禁用于商业用途和非法用途,否则由此产生的一切后果均与文章作者无关,若有侵权,请联系我立即删除!
概要
- 该篇文章是基于sm4的加密分析
- 不分析所有加密参数, 只分析 sm4算法
- 用到的工具 360浏览器
- 用到的在线加密测试网址
https://lzltool.cn/SM4
逆向目标
请求参数 encData,响应参数 encData
开始整活
抓包
打开F12 选择XHR请求 定位到搜索数据包
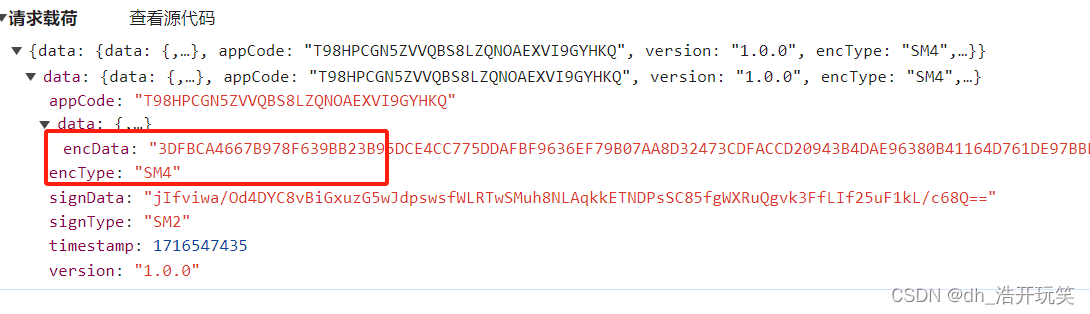
参数定位及分析
-
直接搜索关键词,这里推荐搜索
encType因为这个词出现的地方大概率是加密的位置 -
其实加密的算法请求体都已经告知了
encType: "SM4" -
通过关键字搜索最终定位到了这里(很好搜,总共就两处)
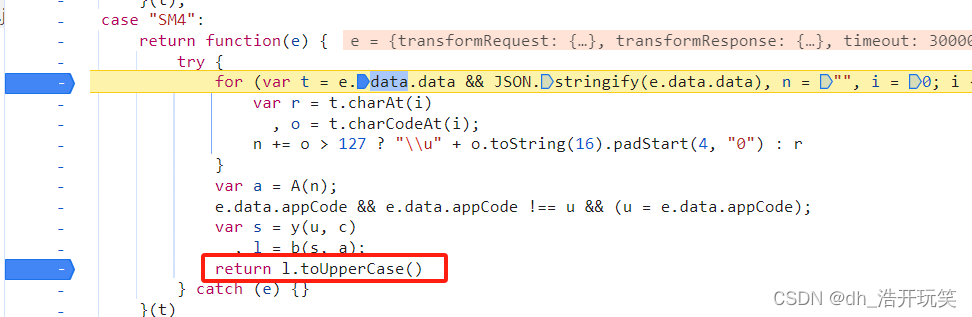
-
l.toUpperCase()就是生成的请求体密文 -
技巧1:像这种参数和响应数据都是加密的,我遇到的最多的就是这几种
AES, DES, 现在多了个 SM4 -
技巧2:
SM4算法的加密模式也分CBC, ECB同样分是否有iv两种情况
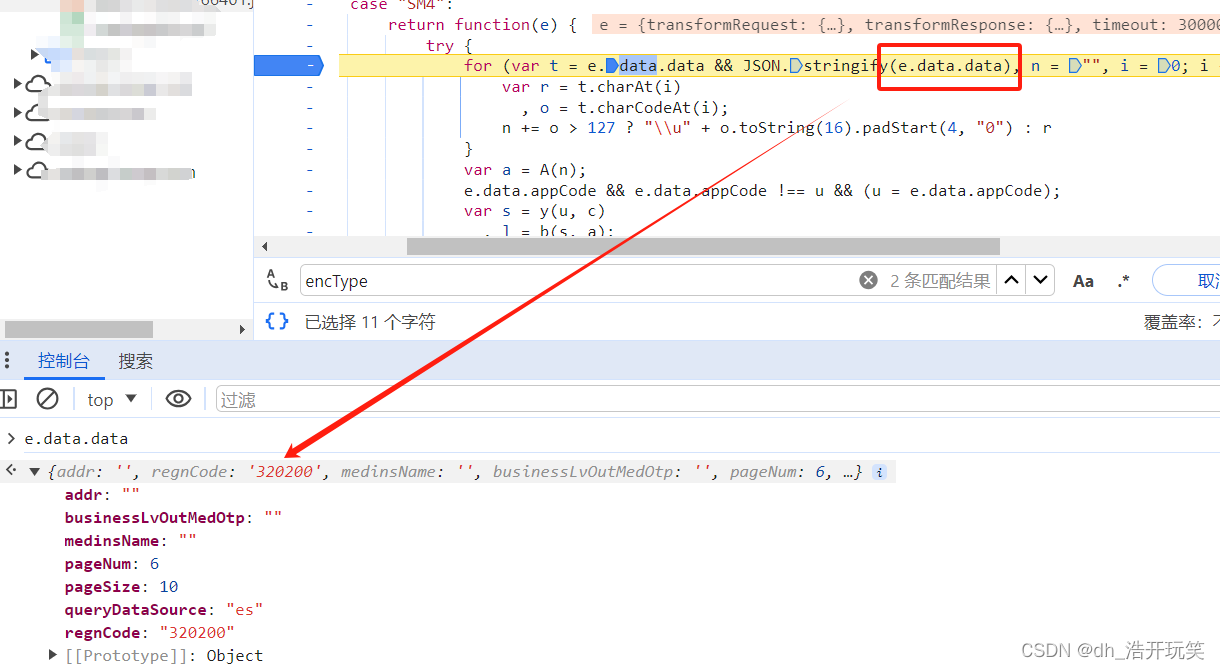
在上图中我们可以看到 请求体的数据在此处还是明文状态
而 l 就是加密后的请求体,经过查看一番后,锁定了加密处就是 s = y(u, c) 和 l = b(s, a);
直接断点到 l = b(s, a) 处, 这时候我们先大胆猜想一下, 既然 sm4 是有两种加密模式,如果是cbc模式,那应该有 key, iv, 加密的明文 这三个数据;
而这里却只有 s, a 两个数据,这不得不让我们怀疑使用的是 ecb模式加密的
先把请求体复制下来
{"addr":"","regnCode":"320200","medinsName":"","businessLvOutMedOtp":"","pageNum":6,"pageSize":10,"queryDataSource":"es"}
-
在控制台分别输出 s, a, 发现原始数据都被转成了字节数组
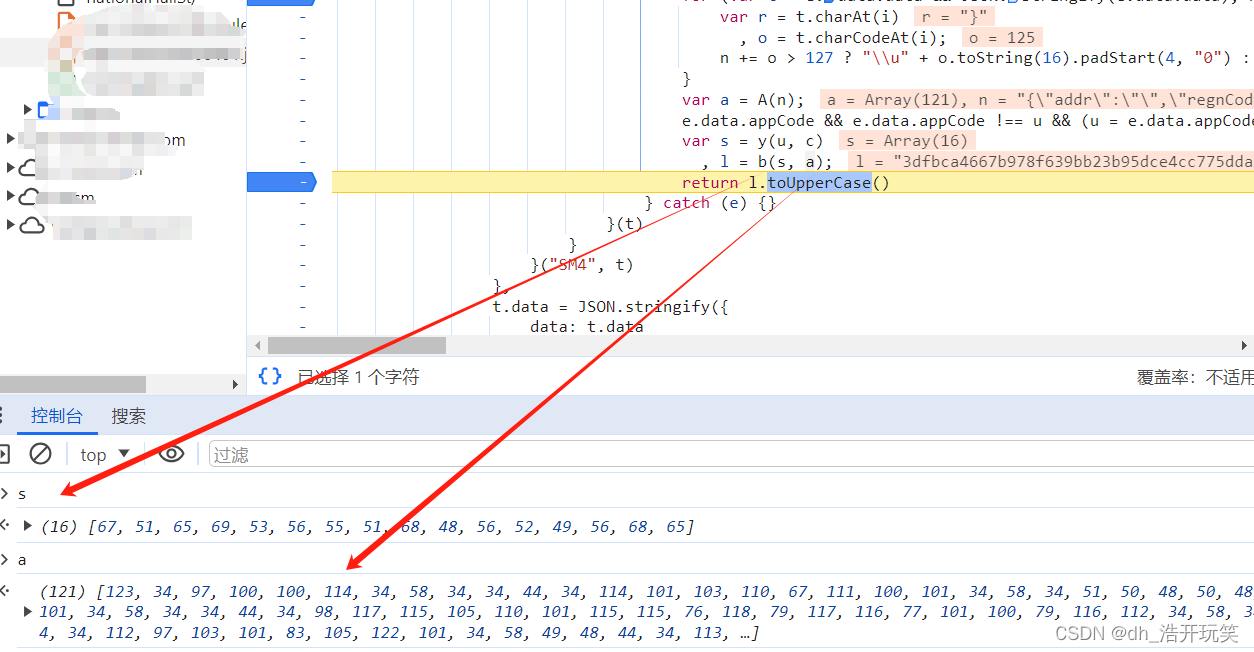
-
字节数组
a其实就是上面复制的明文请求体(e.data.data)转成的字节数组 -
那么
s就一定是加密的密钥了,为了安全我这里就不暴露了 -
然后就开始测试, 测试网站:
https://lzltool.cn/SM4

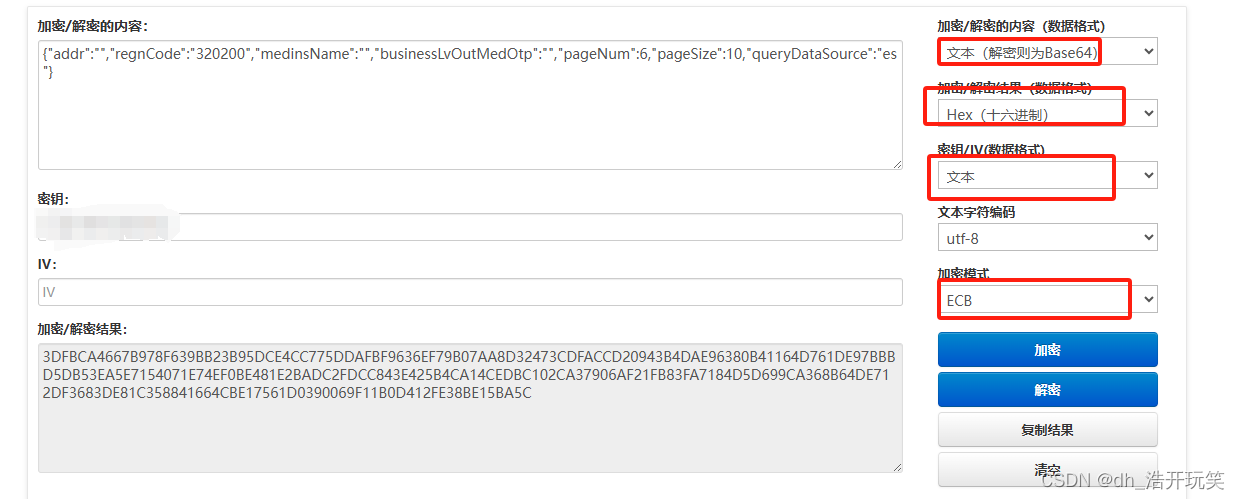
- 发现加密结果一致,说明我们分析的没有问题,然后放开断点测试下响应数据的解密
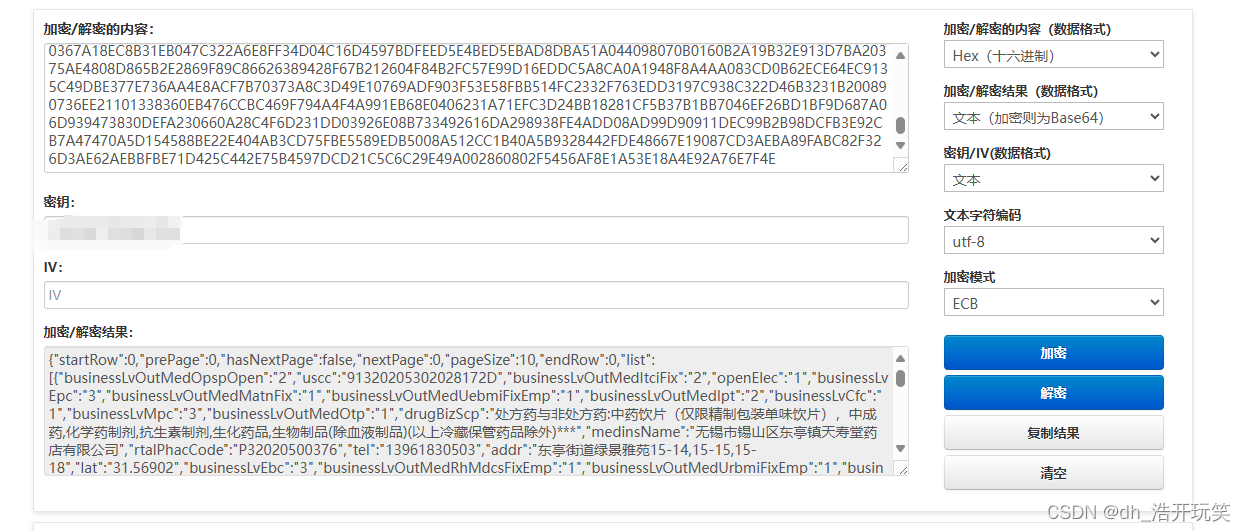
- 也是能正常解密的,至此就分析结束了
总结
- sm4 加密算法之前都没遇到过,第一次搞得时候也是一脸懵,还好这是第二次...
- 请牢记文章中的两个小技巧,有时候这些不起眼的小技巧能让你事半功倍


















 1093
1093

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











