






机器学习零散笔记
-
self.features(即vgg.features)是包含vgg网络的44个对features的操作
-
nn.softmax(dim=x)是对第x纬度进行归一化,x=0时通道重叠穿透做归一化,x=1时一列数据归一化,x=2时一行数据归一化
-
y.backward()是y对x求导,结果存放到x.grad(),通过访问它就知道导数
-
默认情况下pytorch会累加梯度,所以我们要清理之前的值,用x.grad.zero_()
-
学习率:步长的超参数,不能太大或太小
-
沿梯度方向将增加损失函数,故沿着反方向更新参数。每次计算梯度都要将整个数据拿出来算,消耗太大,所以使用小批量batch
-
flatten(dim)表示,从第dim个维度开始展开,将后面的维度转化为一维.也就是说,只保留dim之前的维度,其他维度的数据全都挤在dim这一维。
-
损失函数:
- 均方损失:L2 Loss
- 绝对值损失:L1 Loss
-
训练流程:数据读取,整理成batch_size,初始化模型参数,定义模型,定义损失函数,定义优化函数,训练
-
loss.sum().backward()的理解:一个向量是不进行backward操作的,而sum()后变为标量可以。
-
对y求导即y.backward()之后才能得到参数的梯度,用参数x.grad访问梯度。所以先使用反向传播函数backward()之后才能更新参数。
-
img通道一般为3(“RGB”),特殊情况下通道数可能为4(“RGB+Alpha”)。Alpha用来衡量一个像素或图像的透明度。比如Alpha为0时,该像素完全透明,Alpha为255时,该像素是完全不透明。img通道数从4变为3:
from PIL import Image
image = Image.open(filename).convert('RGB')
-
nvidia-smi详解:链接
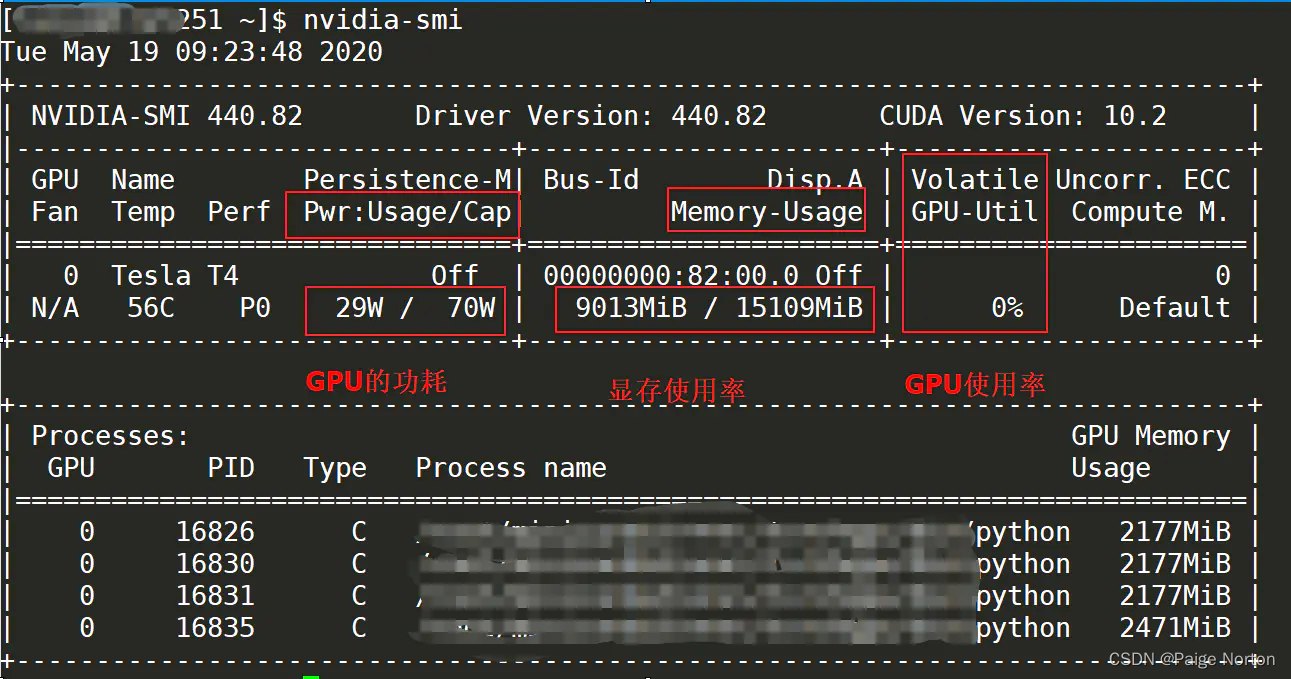
-
batch_size:(链接)表示单次传递给程序用以训练的数据(样本)个数。比如我们的训练集有1000个数据。这是如果我们设置batch_size=100,那么程序首先会用数据集中的前100个参数,即第1-100个数据来训练模型。当训练完成后更新权重,再使用第101-200的个数据训练,直至第十次使用完训练集中的1000个数据后停止。
-
num_worker:(链接)加载到内存中的待处理的batch数量
num_worker=0时每次从硬盘中加载1个batch到内存,然后加载给显卡处理。
num_worker=3时每次从硬盘中加载3个batch到内存,然后加载给显卡处理,这样程序运行速度更快,但更占内存。 -
__call__:用法和__forward__类似,
class Person(object):
def __init__(self, name, gender):
self.name = name
self.gender = gender
def __call__(self, friend):
print('My name is %s...' % self.name)
print('My friend is %s...' % friend)
使用person():
>>> p = Person('Bob', 'male')
>>> p('Tim')
My name is Bob...
My friend is Tim...

















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









