



 本文深入探讨了C语言中指针的基本概念及其在变量、数组、字符和函数等不同场景下的应用。详细解释了指针与数组名的区别,以及如何在实际编程中正确使用指针进行操作。
本文深入探讨了C语言中指针的基本概念及其在变量、数组、字符和函数等不同场景下的应用。详细解释了指针与数组名的区别,以及如何在实际编程中正确使用指针进行操作。
指针是存储地址的变量。
下面是C语言中指针在不同应用场景下的设定。
一、变量
在仅有变量的应用场景中,仅多用到*与&两个字符并且它们的含义很明确。
如下图(value与变量名等效):
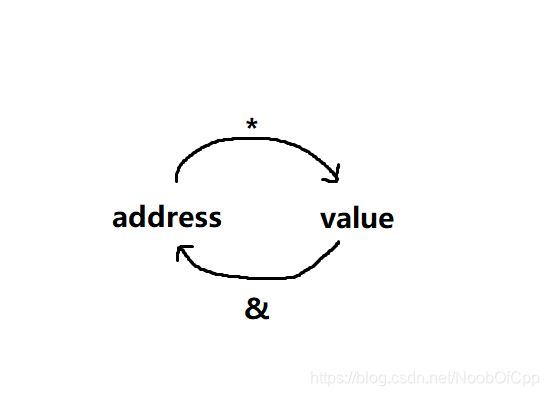
有几处例外,定义指针时用 * 作为标志。
例子如下:
int x, y, z;
int *a,*b,*c;
//*a是value,
//&x是address。
a=&x;
*a=1;
其次,函数定义形参时的&是引用的意思。(当然了,这是cpp的内容。)
二、数组
相比于变量,数组场景下不仅增加了+,*和&的含义也有所拓展。
需要注意的是,一维数组下的a[1]以及二维数组下的a[1][2]算是变量。
数组只有在维度残缺的情况下才能显露出地址的痕迹。
另外,数组名不是value,而是address。
我先总结数组名的用法,它与指针的区别仅仅在于有没有用指针名替换数组名罢了。
二维数组具有更强的普适性,且较为常用,故以其为例。
对二维数组的看法的不同产生了两种不同的表示方法。
首先定义一个n行m列的二维数组。
1.以行为标准
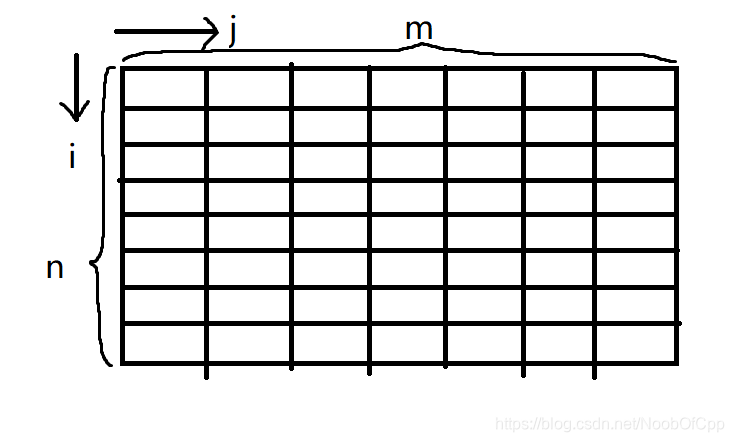
以上图的方式看待它。
表示行的地址(其实也就是行的首列的地址)的格式是a+i或 &a[i] ,需要注意的是,即便 a[i] 也有同样的功能,但是它也不被提倡用于 以行为标准 的思想。
如果a+i是新的设定的话,那么&a[i]中的&似乎显得多余,我认为这是C语言刻意为之的,用于区分两种对数组的看法。(使区分这些显得更为重要的一个原因是,在某些设定下这几种写法不等效。)
i为0时的表示可以简写为a。
在一维数组的情况下会略有冲突,一维数组的数组名a指第一个元素的地址,实质上是下一种分类的思想,&a[0]也是, 一维数组的行的概念很弱,所以&a这个格式专用于一维数组。
2.以列为标准
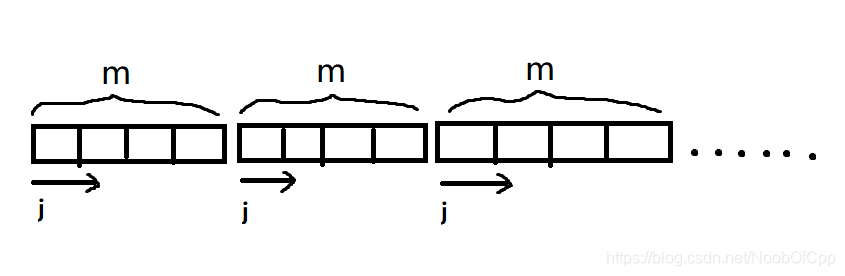
以上图的方式看待它。
行的概念被弱化,每个元素似乎都是直接属于数组,而不经由“行”这一单位。
表示每一行的第一个列的元素地址的格式为 *(a+1) 和 a[1]。
i为0时的表示可以简写为 *a。
表示第i行第j列的元素的地址的格式是a+(i*m+j) 和 &a[0][0]+(i*m+j) 。
比较两次的不同,a+1与 *(a+1):*的存在看起来是要将a+1这个address转换为value,但是这是不可能的,因为缺少了一维,所以“转换”之后仍然是一个address。
&a[1]和a[1]:a[1]本来就是个address,如果再进行寻址的话,那必然也会得到address。
以上,就是两种思考方式以及相应的格式。
另外,按照上面的四种格式,C语言又拓展出了每个元素的value以及address不同的表示方法。
当然,这两者其实早就有了 简洁的表示方法:即a[1][2]和&a[1][2]。
这些拓展有:
地址: *(a+1)+2 和 a[1]+2
值: *(*(a+1)+2) 和 *(a[1]+2) 和 *(a+(i*m+j))
看起来这四种拓展大都是对*的使用(第二个是[]的使用)。
而[]看似简洁,但是它不能像 *( )一样进行扩展以适用更高维度的数组。
按照两种思考方式,相应地有两种不同的针对数组的指针。
1.列指针
列指针把数组看作很多个变量排在一起,弱化了行的概念,所以使用上和第一部分没有不同。
它所涉及的数组元素地址表示应该使用列思想里的表示方法。
列指针示例:
int a[3][4];
int *p;
for(p=a[0];p<a[0]+12;p++){
printf("%d ",*p);
}
2.行指针
行指针的不同在于,在定义时便给出涉及数组的行数。使用时更突出行的概念。
它涉及到的数组地址应该使用行思想里的表示方法。
(之前特地声明了一维数组的不同之处,在此也要遵循。)
行指针使用示例:
int a[4];
int (*p)[4];
p=&a;
//一维数组仅有一种表示方法。
int b[3][4];
int (*q)[4];
q=b+0;
q=b;
q=&b[0];
//以上三种赋值方法等效。
return 0;
三、字符指针
不想写,因为完全可以被字符数组代替。
四、函数指针
…

















 1587
1587




 到【灌水乐园】发言
到【灌水乐园】发言







