







 本文围绕分布式系统的远程调用过程及调用链跟踪系统展开。介绍了通过TraceID串联系统调用关系,用SpanID和ParentSpanID标识请求和响应顺序层级。还提到用业务系统订单号串联业务链。最后简述调用链跟踪系统由采集器、处理器和分布式存储系统组成。
本文围绕分布式系统的远程调用过程及调用链跟踪系统展开。介绍了通过TraceID串联系统调用关系,用SpanID和ParentSpanID标识请求和响应顺序层级。还提到用业务系统订单号串联业务链。最后简述调用链跟踪系统由采集器、处理器和分布式存储系统组成。
分布式系统的远程调用过程
典型的分布式系统的调用关系如下图所示,在用户的一个请求到达组合的前端服务后,前端服务会分发请求到内部的各个服务,每次调用都设计跨系统的一次请求和一次响应。
在有大规模、高并发请求量的系统中,我们如何标识这些请求及存储这些调用信息,并形成一个调用链呢?
如果系统的某两个服务之间出了问题,我们又如何提供可视化的方式展现调用链,并在调用链上标注产生问题的那条边呢?
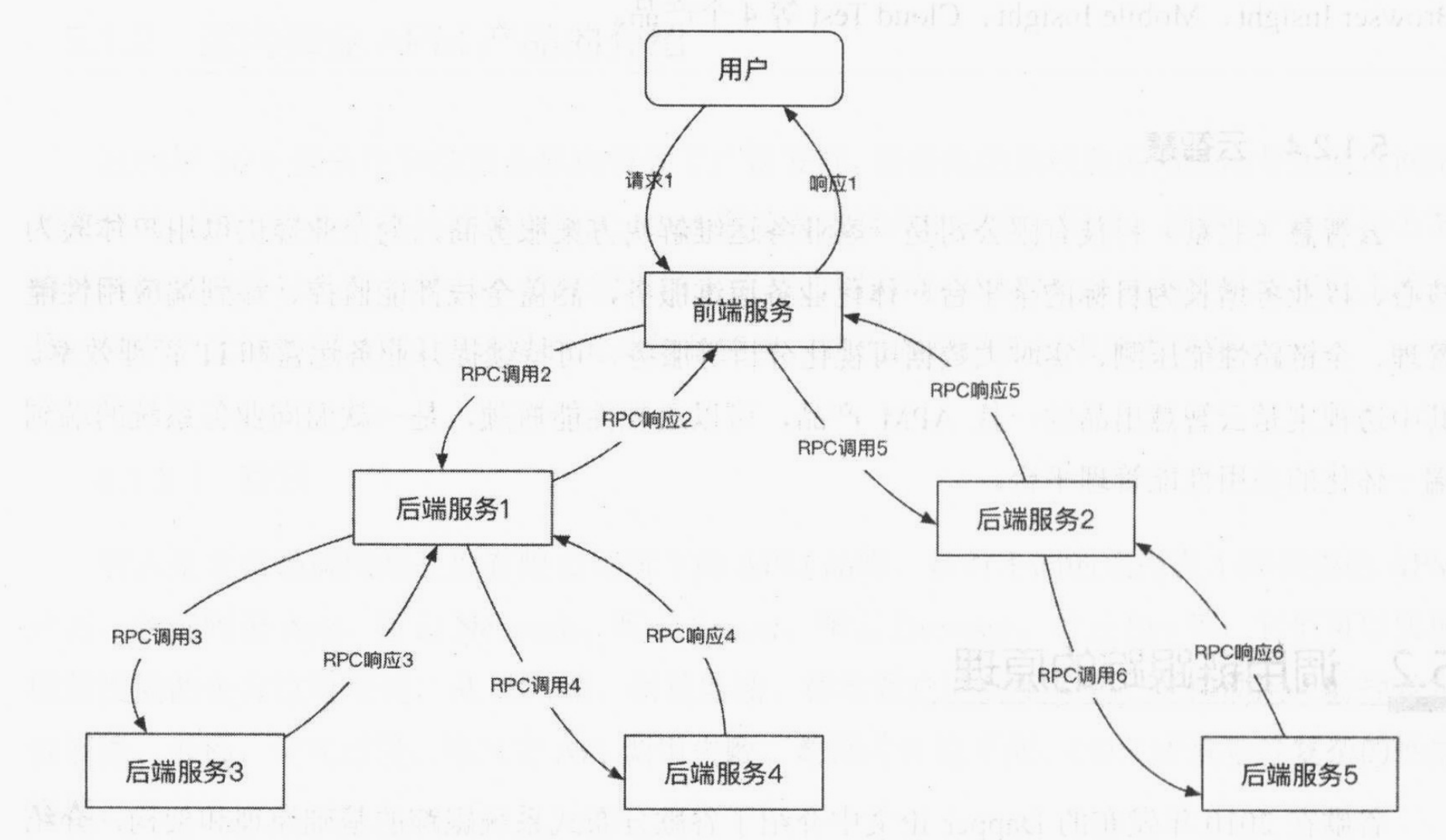
从上图可知,服务于一个请求的内部服务调用结构是一个树形结构,树节点是整个架构的基本单元,每个节点对应一个服务。
在谷歌的Dapper论文中,每个节点对应一个Span,节点之间的连线标识为Span与其Parent Span之间的关系(请求和响应的调用关系),并将请求调用和响应组成的数据称为调用信息。
现在,我们重点关注两个服务之间的通信,两个服务之间也许会有成千上万次通信,每一次都有成对的一次请求和响应,但是它们的顺序是不能保证的(发送请求1、2得到响应2、1)。所以,需要一种手段来标识请求和响应是一对。
谷歌的Dapper论文通过增加应用层的标记来对服务化中的请求和响应建立联系。例如,它通过HTTP协议头来携带标记信息,标记信息包括标识调用链的唯一流水ID(TraceID),以及标识调用层次和顺序的SpanID和ParentSpanID。
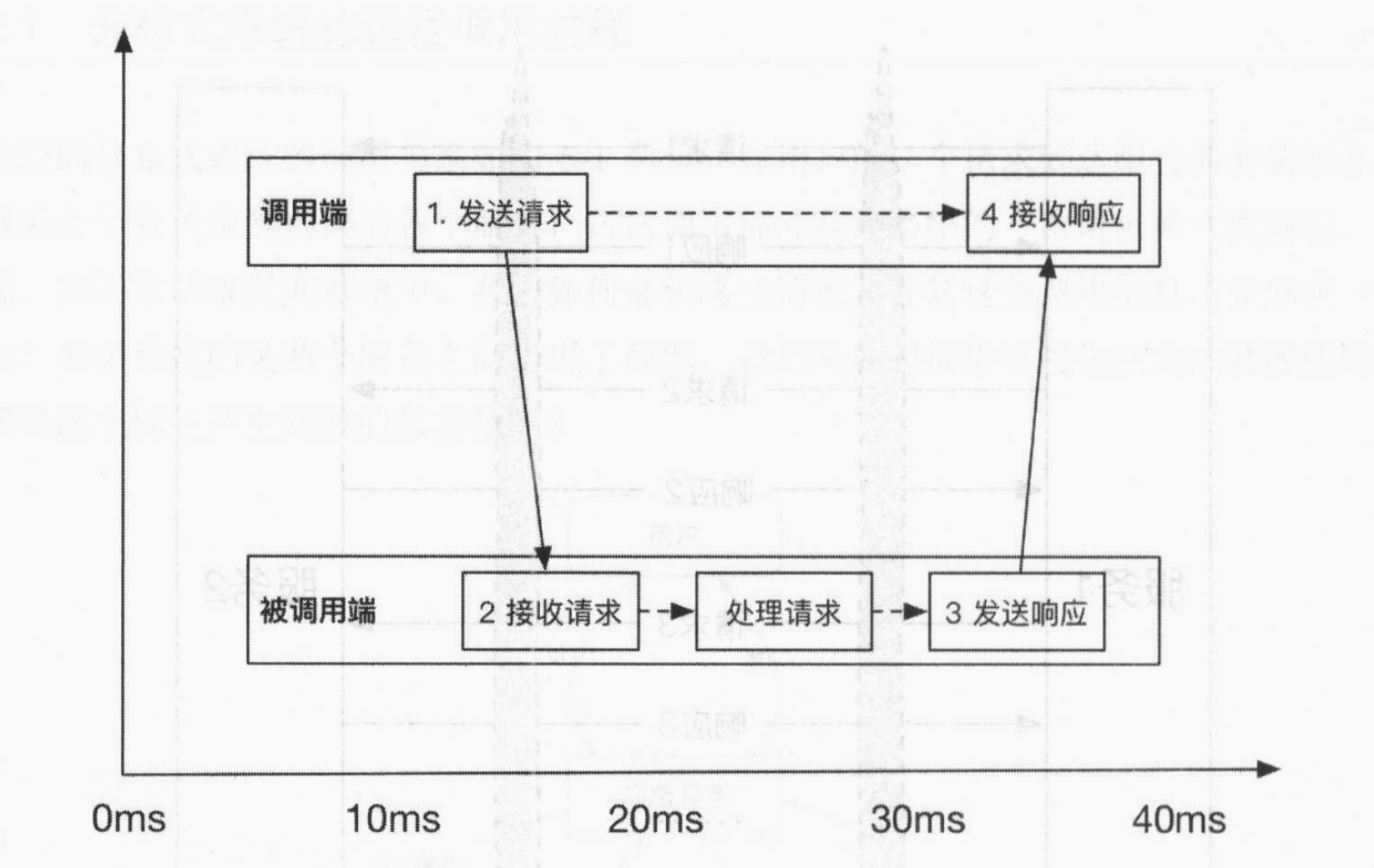
一次远程调用分为4个阶段,每个阶段对应一种远程调用信息的类型:
- 调用端 发送请求 的调用信息 RPCPhase.P1
- 被调用端 接收请求 的调用信息 RPCPhase.P2
- 被调用端 发送响应 的调用信息 RPCPhase.P3/E3
- 调用端 接收响应 的调用信息 RPCPhase.P4/E4
由于响应又被分为成功响应和异常响应。所以第三第四阶段的调用类型分为P/E。另外主线程与子线程之间的调用信息称为 RPCPhase.SIB。
上面每种调用信息都包含:调用端/被调用端的IP、系统ID;本次请求的TraceID、SpanID、ParentSpanID;时间戳、调用的方法名称及远程调用信息的类型等等。
TraceID
如下图所示,前端接收用户请求后,会为用户分配一个TraceID,然后在内部服务调用时,会依次传递。所以通过TraceID可以追踪到这个唯一ID所有的请求和响应,并定位问题发生的节点。
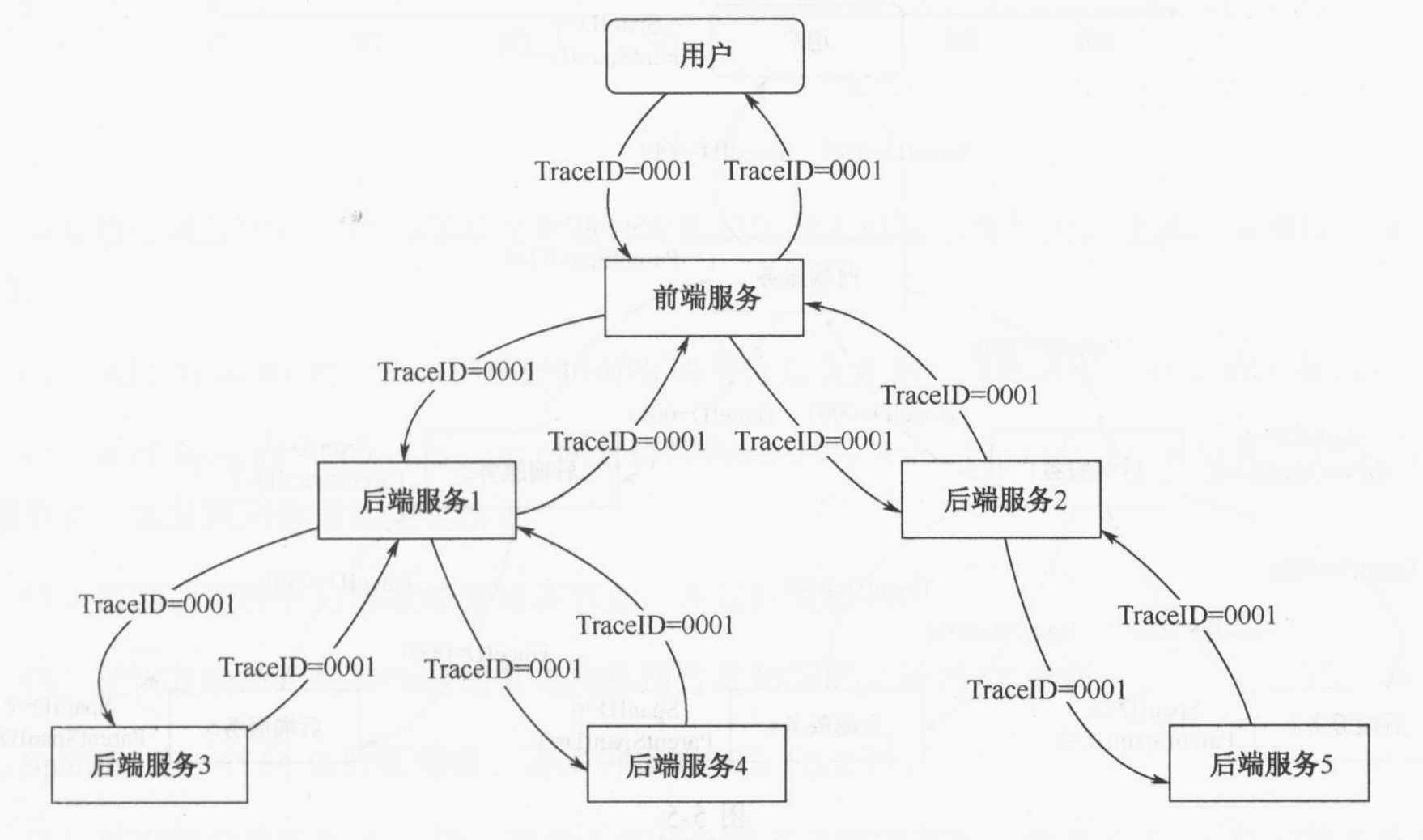
TraceID解决了系统调用关系的串联问题,通过调用关系串联,我们能够找到服务于一个用户请求的调用和响应消息的集合。
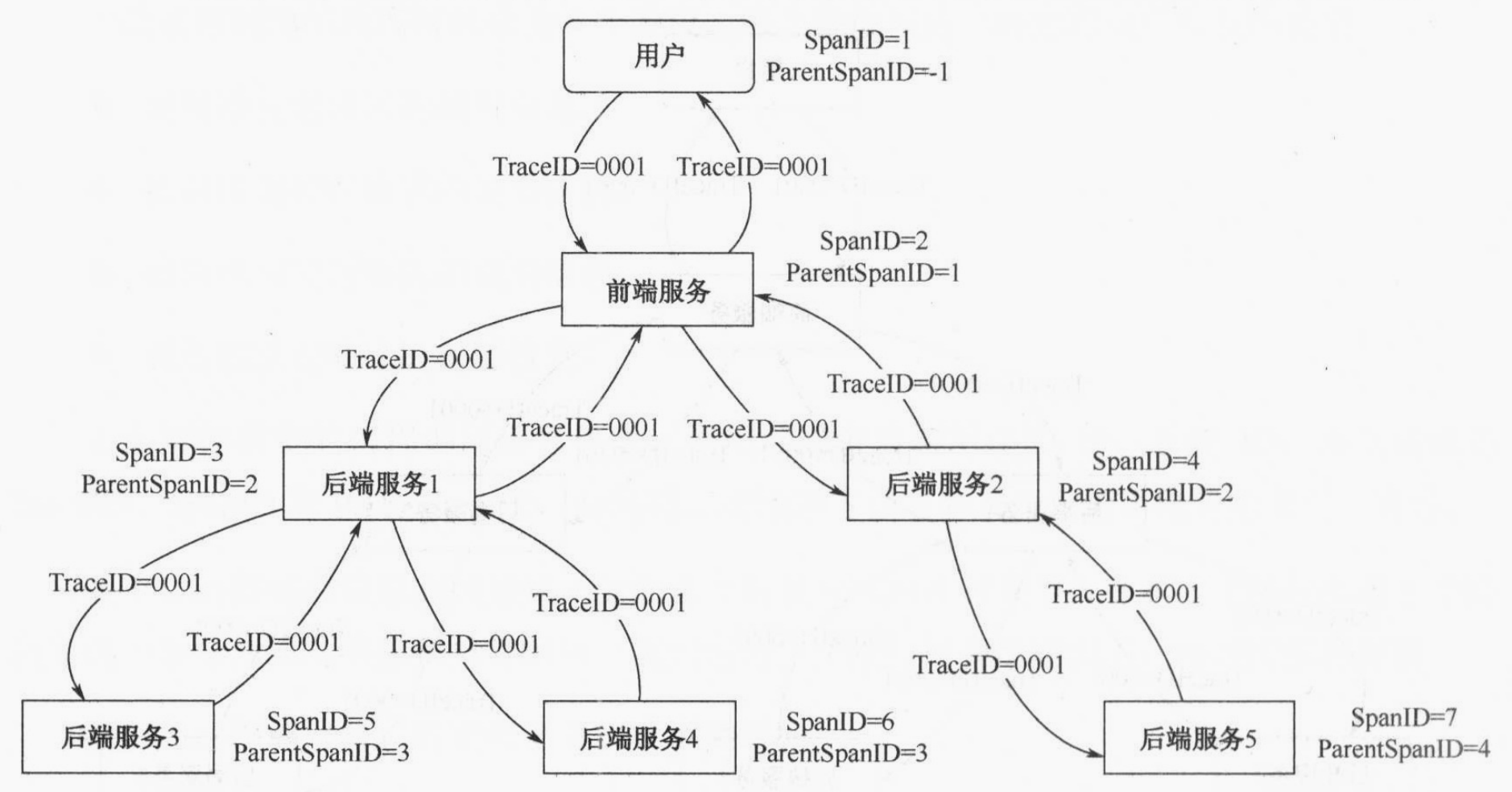
SpanID/ParentSpanID
TraceID无法标识和恢复调用请求和响应的顺序和层级关系。因此需要SpanID和ParentSpanID,这里我们统称SpanID。
业务链
在生产实践中,由于业务流程的复杂性,一个业务流程的完成由用户的多次请求组成。
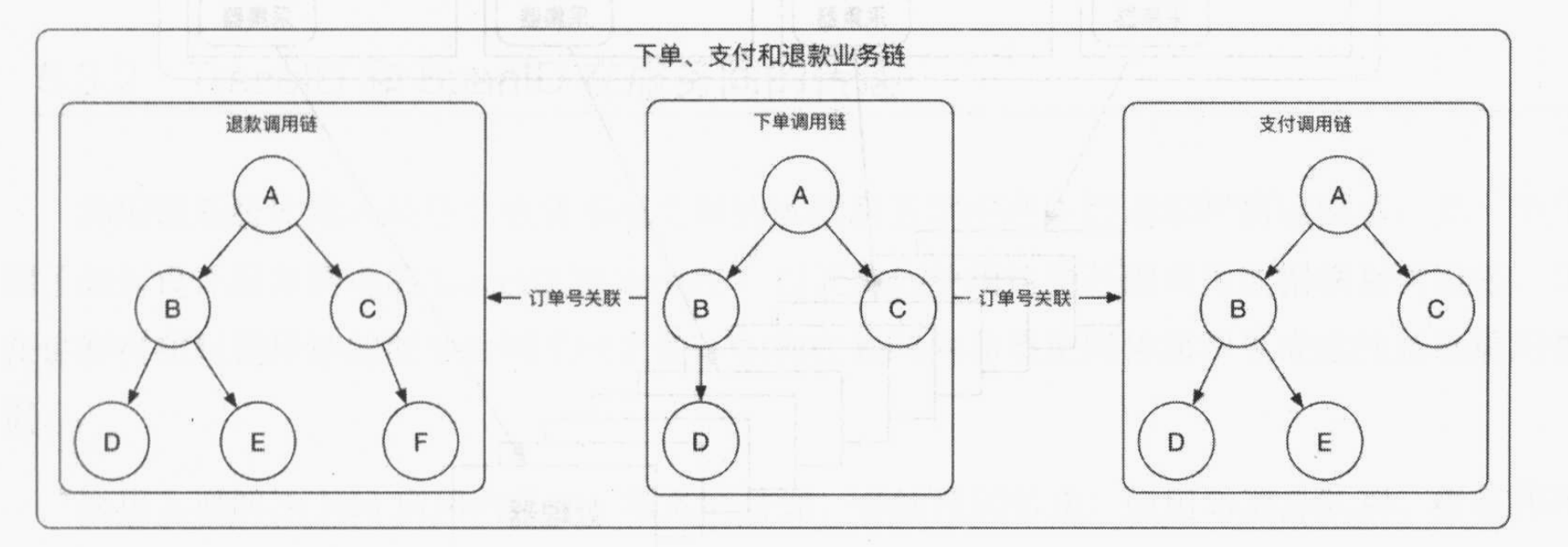
我们需要在多次请求之间建立联系,可以通过业务系统的订单号来串联业务链,调用链是简单的树形结构,业务链则是森林。
调用链跟踪系统的设计与实现
调用链跟踪系统通常由采集器、处理器和分布式存储系统组成,该系统对外提供查询和查看功能,整体的调用链跟踪系统的通用架构如下图所示:
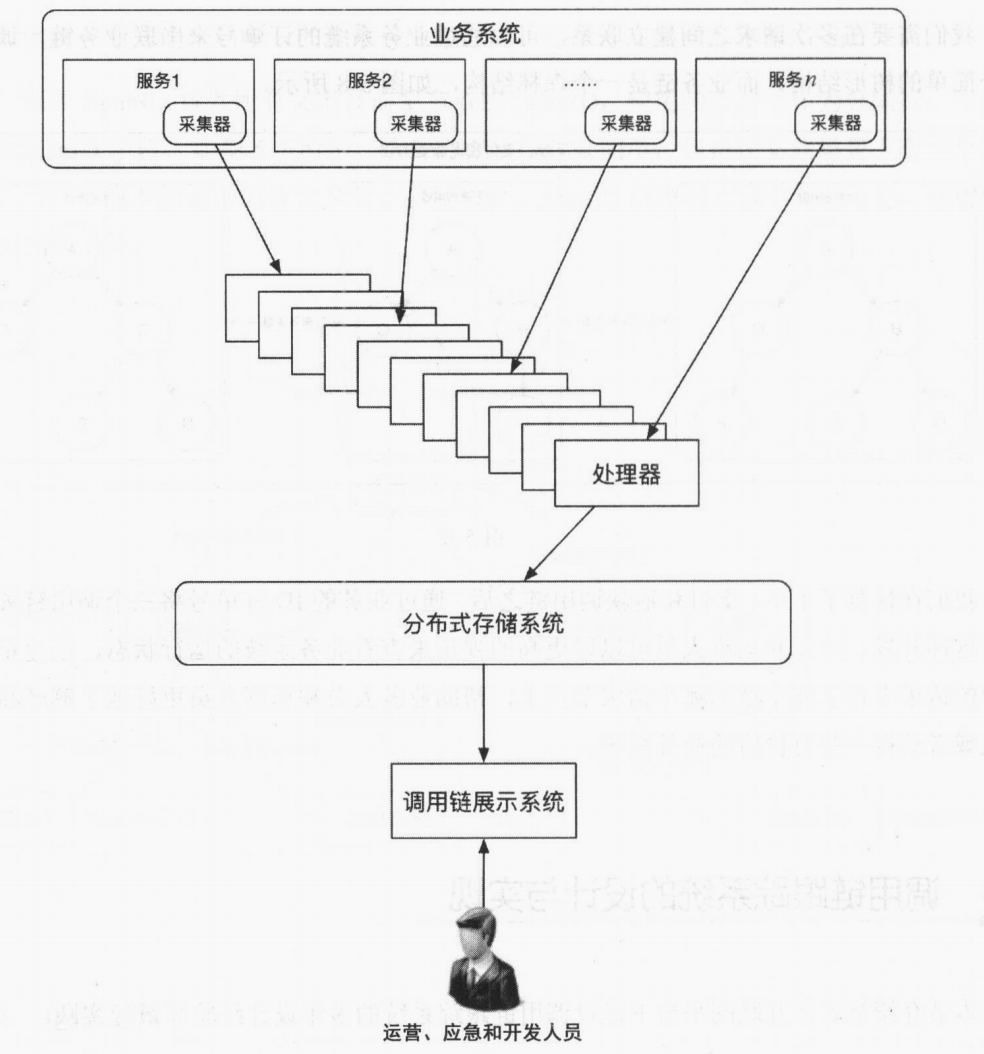
具体怎么实现的,不是学习重点,暂不赘述。

















 2842
2842

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









